

Excel数据自动导入word模板
Excel数据自动导入word模板
1)提取链接
链接:https://pan.baidu.com/s/1WYm8_hfKXVdR6Ffacd2MTg
提取码:601e
2)要是程序运行失败,肯定是过程不对,或者输入错误,未做异常处理,以后有空再说
一、 准备工作
1.1、word模板准备
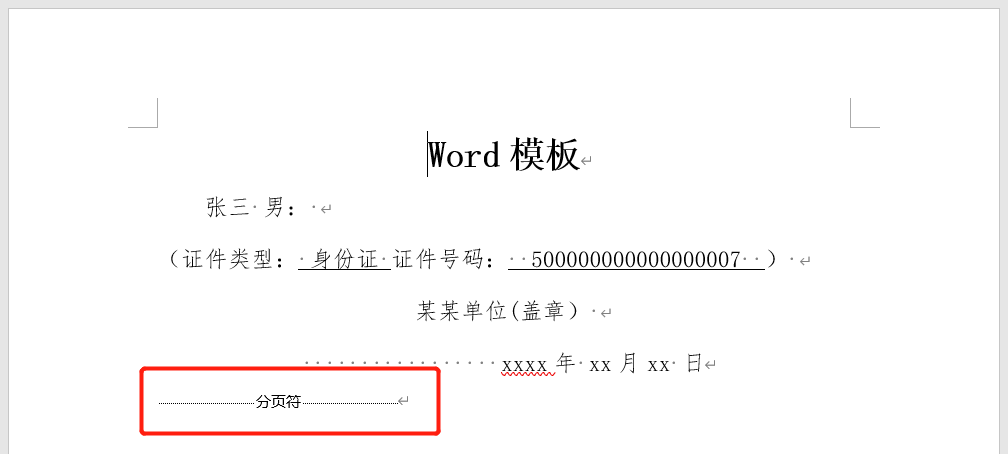
设置占位符,就是excel数据要填入的位置,注意:
-
占位符是由两个大括号包裹占位符名称
-
输入时要设置为英文输入,中文输入法的符号和英文的符号是不一样的
-
占位符名称使用英文,使用中文可能出现未知错误

1.2、Excel数据准备
将excel文件保存为.xls格式,因为新版的.xlsx兼容性不好,程序读取会出问题
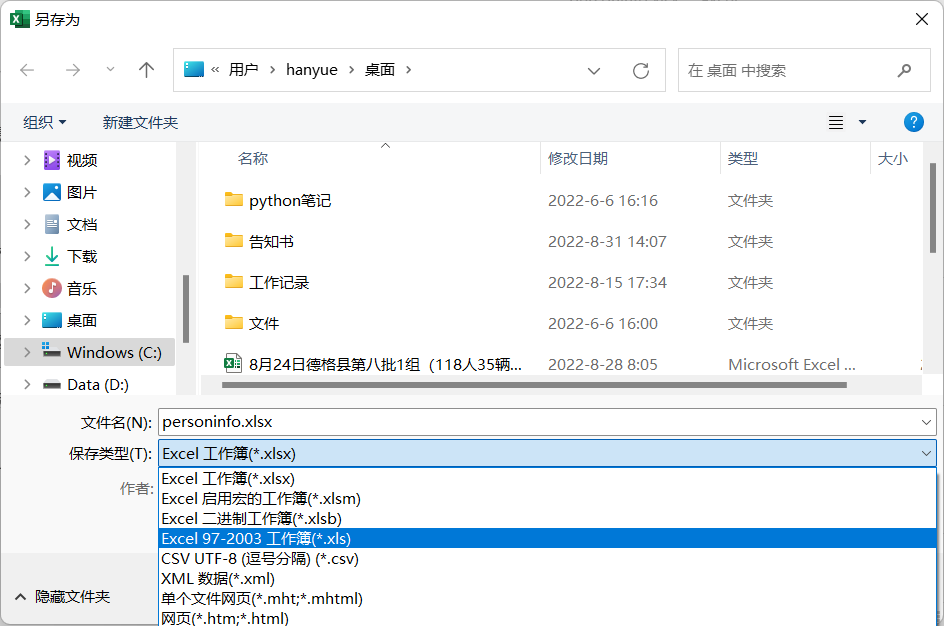
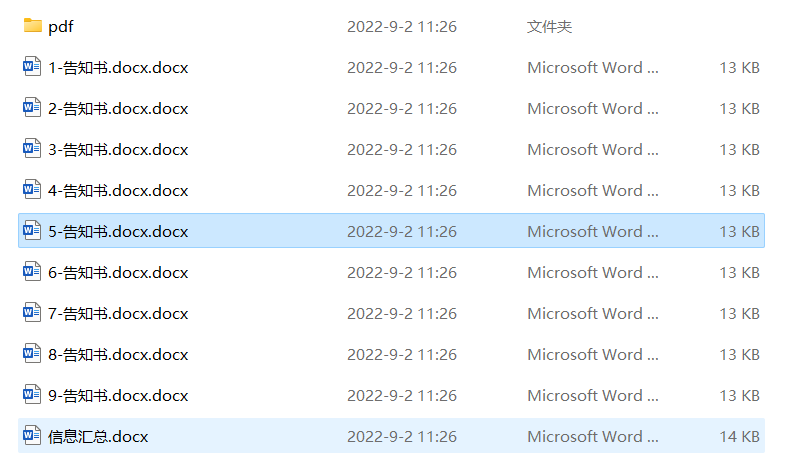
软件应用场景经常为将数据填入模板后进行打印,有时候打印完成后需要分类。
软件提供功能将生成的文件合并成一个word文件,排序按照Excel的行顺序,因此有需求的可以先将excel排序分类。
1.3、文件夹准备
新建一个文件夹,文件将在此文件夹内生成
二、运行程序
特别注意:
输入的所有地址必须是反斜杆:
直接复制的地址(都是正斜杠):C:\Users\hanyue\Desktop
需要手动改成返斜杆:C:/Users/hanyue/Desktop
2.1、告诉程序word模板信息
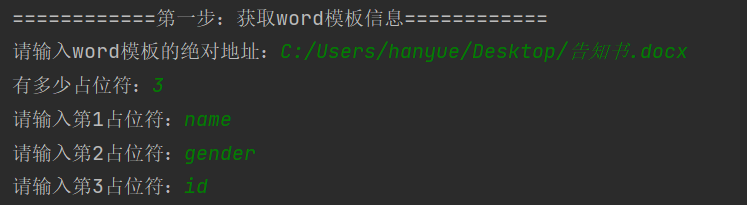
1)输入word模板地址:
- 请输入word模板的绝对地址:word文档地址拼接文档名称
- 例如(注意改成反斜杆):C:/Users/hanyue/Desktop/告知书.docx
2)输入占位符信息:
- 有多少占位符:有几个写多少
- 请输入第n占位符:输入占位符名称(顺序不重要)
2.2、告诉程序Excel表格信息
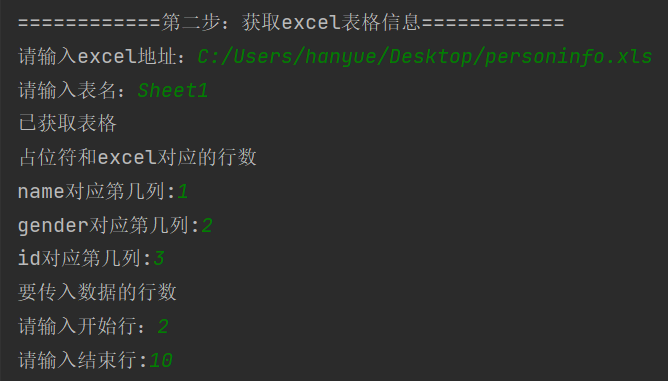
1)请输入excel地址(注意检查是不是 .xls文件):
- 请输入excel地址:excel文档地址拼接文档名称
- 例如:C:/Users/hanyue/Desktop/personinfo.xls
- 注意改成反斜杆
- 格式必须是.xls
2)请输入表名
- 请输入表名:表名
- 例如:Sheet1
- 大小写要正确
3)告诉word文档的占位符对应excel数据第几列
excel列数是字母表示,可以设置为数字,可以直接数,A列就是第1列,B列就是第2列
- 这里相对于占位符和Excel表格数据建立连接
4)输入开始行数和截止行数
- 中间的行数的所有数据都会填入
- 行数直接按照行数显示填入即可
2.3、告诉程序生成文件的信息

1)请输入生成文件保存地址:
- 之前准备工作创建了新文件夹,进入文件夹,获取地址栏信息
2)请输入作为后缀的占位符(不知道选哪个就敲空格)
指生成文件名称的前缀
- 前缀必须是占位符
- 有重复的会按数字排序标注
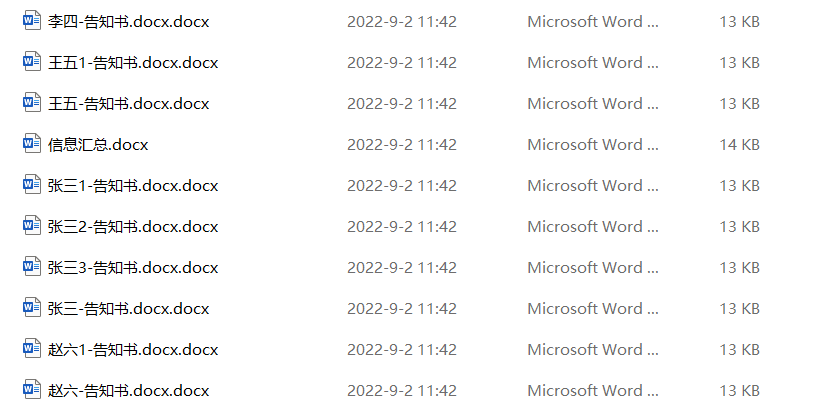
要是对应占位符输入错误,或者直接输入空格,还直接按1、2、3、4编号排序
3)告诉程序生成的—信息汇总.docx是否要分页
2.4、告诉程序是否生成pdf
特别注意:
由于生成模板有打印需求,打印完成后可能需要根据各自信息进行分类,可以事先把Excel进行分类,生成的信息汇总会按Excel顺序排列。
生成的word文件会自动汇总成一个word文件,文件名称为—信息汇总.docx,但是汇总后,格式可能有轻微变化。
生成的pdf文件也会自动汇总成一个PDF文件,文件名称为—信息汇总.pdf,汇总后格式比较完美,不会变化,但是程序运行速度会降低。
1)是否生成PDF(y/n):
输入小写y表示需要生成PDF
三、程序源码
import os
import PyPDF2
from docx import Document
from docxtpl import DocxTemplate
import xlrd
from docxcompose.composer import Composer
from win32com.client import Dispatch
print("============第一步:获取word模板信息============")
wordAddress = input("请输入word模板的绝对地址:")
zwcs = 0
zwnum = input("有多少占位符:")
zwnum = int(zwnum)
zwfs = []
while zwcs < zwnum:
zwmc = input("请输入第"+ str(zwcs + 1) +"占位符:")
zwfs.append(zwmc)
zwcs += 1
print("============第二步:获取excel表格信息============")
xls = input("请输入excel地址:")
biaoming = input("请输入表名:")
xlrd = xlrd.open_workbook(xls)
table = xlrd.sheet_by_name(biaoming)
print("输入占位符和excel对应的行数")
paramzd = dict.fromkeys(zwfs)
for param in zwfs:
paramzd[param] = int(input(param+"对应第几列:")) - 1
print("要传入数据的行数")
start = input("请输入开始行:")
finish = input("请输入结束行:")
rstart = int(start) - 1
rfinish = int(finish)
print("============第三步:生成文件的信息============")
baocun = input("请输入生成文件保存地址:")
houzui = input("请输入作为后缀的占位符(不知道选哪个就敲空格):")
sffy = input("word信息汇总是否生成分页(y/n):")
mark1 = 0
if sffy == "y":
mark1 = 1
print("============第四步:是否生成PDF============")
print("生成pdf会导致速度稍慢,但是word信息汇总文件格式可能需要微调")
print("pdf汇总文件不会出现这种问题,需要生成选输入小写y")
sfPdf = input("是否生成PDF(y/n):")
mark = 0
if sfPdf == "y":
mark = 1
i = rstart
flag = 0
for a in zwfs:
if a == houzui:
flag = 1
pianshu = 1
stradd = wordAddress.split("/")
pijie = stradd[len(stradd)-1]
pijiepdfs = pijie.split(".")
pijiepdf = pijiepdfs[0]
if flag == 1:
houzuis = []
master = Document()
new_doc = Document()
if mark == 1:
pdfaddress = baocun + "/pdf"
os.mkdir(r"%s" %pdfaddress)
wordPdf = Dispatch('Word.Application')
merger=PyPDF2.PdfFileMerger()
while i < rfinish:
context = dict.fromkeys(zwfs)
for param in zwfs:
context[param] = paramzd[param]
for key in context:
context[key] = table.cell_value(i, context[key])
word = DocxTemplate(r"%s" %wordAddress)
baocunwenjian = ""
word.render(context)
if flag == 0:
baocunwenjian = baocun + "/" + "" + str(pianshu) + "-" + pijie
word.save(baocunwenjian)
i += 1
if pianshu == 1:
master = Document(baocunwenjian)
if mark1 == 1:
master.add_page_break()
new_doc = Composer(master)
else:
next_doc = Document(baocunwenjian)
if mark1 == 1:
next_doc.add_page_break()
new_doc.append(next_doc)
if mark == 1:
doc = wordPdf.Documents.Open(baocunwenjian)
doc.SaveAs(pdfaddress + "/" + "" + str(pianshu) + "-" + pijiepdf + ".pdf", FileFormat=17)
doc.Close()
merger.append(PyPDF2.PdfFileReader(pdfaddress + "/" + "" + str(pianshu) + "-" + pijiepdf + ".pdf"))
if flag == 1:
if not context[houzui] in houzuis:
houzuis.append(context[houzui])
else:
geshu = 1
while True:
guodu = context[houzui]
guodu += str(geshu)
if not guodu in houzuis:
context[houzui] = guodu
houzuis.append(context[houzui])
break
else:
geshu += 1
baocunwenjian = baocun + "/" + "" + context[houzui] + "-" + pijie
word.save(baocunwenjian)
i += 1
if pianshu == 1:
master = Document(baocunwenjian)
if mark1 == 1:
master.add_page_break()
new_doc = Composer(master)
else:
next_doc = Document(baocunwenjian)
if mark1 == 1:
next_doc.add_page_break()
new_doc.append(next_doc)
if mark == 1:
doc = wordPdf.Documents.Open(baocunwenjian)
doc.SaveAs(pdfaddress + "/" + "" + context[houzui] + "-" + pijiepdf + ".pdf", FileFormat=17)
doc.Close()
merger.append(PyPDF2.PdfFileReader(pdfaddress + "/" + "" + context[houzui] + "-" + pijiepdf + ".pdf"))
print("第几份文件:" + str(pianshu))
pianshu += 1
new_doc.save(baocun + "/信息汇总.docx")
xlrd.release_resources()
if mark == 1:
merger.write(pdfaddress + "/信息汇总.pdf")
merger.close()

