Ceph性能优化
几个 Ceph 性能优化的新方法和思路(2015 SH Ceph Day 参后感)
一周前,由 Intel 与 Redhat 在10月18日联合举办了 Shanghai Ceph Day。在这次会议上,多位专家做了十几场非常精彩的演讲。本文就这些演讲中提到的 Ceph性能优化方面的知识和方法,试着就自己的理解做个总结。
0. 常规的 Ceph 性能优化方法
(1). 硬件层面
- 硬件规划:CPU、内存、网络
- SSD选择:使用 SSD 作为日志存储
- BIOS设置:打开超线程(HT)、关闭节能、关闭 NUMA 等
(2). 软件层面
- Linux OS:MTU、read_ahead 等
- Ceph Configurations 和 PG Number 调整:使用 PG 计算公式(Total PGs = (Total_number_of_OSD * 100) / max_replication_count)计算。
- CRUSH Map
更多信息,可以参考下面的文章:
- Ceph性能优化总结(v0.94)
- Measure Ceph RBD performance in a quantitative way 1,2
- Ceph性能调优——Journal与tcmalloc
- Ceph Benchmarks
- 官方的 CEPH CUTTLEFISH VS BOBTAIL PART 1: INTRODUCTION AND RADOS BENCH
1. 使用分层的缓存层 - Tiered Cache
显然这不是一个 Ceph 的新特性,在会议上有这方面的专家详细地介绍了该特性的原理及用法,以及与纠错码方式结合的细节。
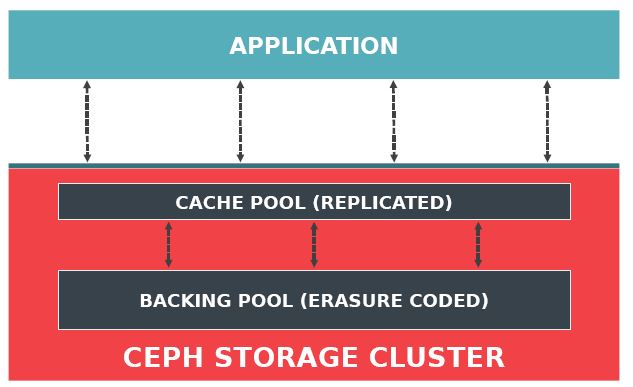
简单概括:
- 每一个缓存层次(tiered cache)使用一个 RADOS pool,其中 cache pool 必须是拷贝(replicated)类型,而 backing pool 可以是拷贝类型也可以是纠错码类型。
- 在不同的缓存层次,使用不同的硬件介质,cache pool 使用的介质必须比 backing pool 使用的介质速度快:比如,在 backing pool 使用一般的存储介质,比如常规的HDD或者 SATA SDD;在 cache pool 使用快速介质,比如 PCIe SDD。
- 每一个 tiered cache 使用自己的 CRUSH rules,使得数据会被写入到指定的不同存储介质。
- librados 内在支持 tiered cache,大多数情况下它会知道客户端数据需要被放到哪一层,因此不需要在 RDB,CephFS,RGW 客户端上做改动。
- OSD 独立地处理数据在两个层次之间的流动:promotion(HDD->SDD)和 eviction(SDD -> HDD),但是,这种数据流动是代价昂贵(expensive)和耗时的(take long time to “warm up”)。
2. 使用更好的 SSD - Intel NVM Express (NVMe) SSD
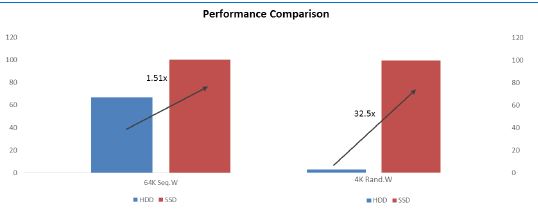
在 Ceph 集群中,往往使用 SSD 来作为 Journal(日志)和 Caching(缓存)介质,来提高集群的性能。下图中,使用 SSD 作为 Journal 的集群比全 HDD 集群的 64K 顺序写速度提高了 1.5 倍,而 4K 随机写速度提高了 32 倍。
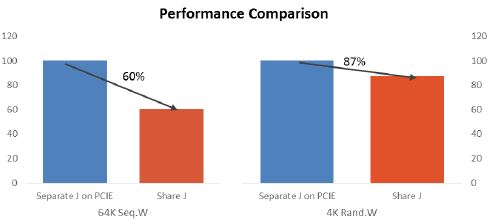
而Journal 和 OSD 使用的 SSD 分开与两者使用同一块SSD,还可以提高性能。下图中,两者放在同一个 SATA SSD 上,性能比分开两块 SSD (Journal 使用 PCIe SSD,OSD 使用 SATA SSD),64K 顺序写速度下降了 40%,而 4K 随机写速度下降了 13%。
因此,更先进的 SSD 自然能更加提高Ceph 集群的性能。SSD 发展到现在,其介质(颗粒)基本经过了三代,自然是一代比一代先进,具体表现在密度更高(容量更大)和读写数据更快。目前,最先进的就是 Intel NVMe SSD,它的特点如下:
- 为 PCI-e 驱动器定制的标准化的软件接口
- 为 SSD 定制(别的是为 PCIe 所做的)
- SSD Journal : HDD OSD 比例可以从常规的 1:5 提高到 1:20
- 对全 SSD 集群来说,全 NVMe SSD 磁盘Ceph 集群自然性能最好,但是它造价太高,而且性能往往会受限于网卡/网络带宽;所以在全SSD环境中,建议的配置是使用 NVMe SSD 做 Journal 而使用常规 SSD 做 OSD 磁盘。
同时,Intel SSD 还可以结合 Intel Cache Acceleration Software 软件使用,它可以智能地根据数据的特性,将数据放到SSD或者HDD:
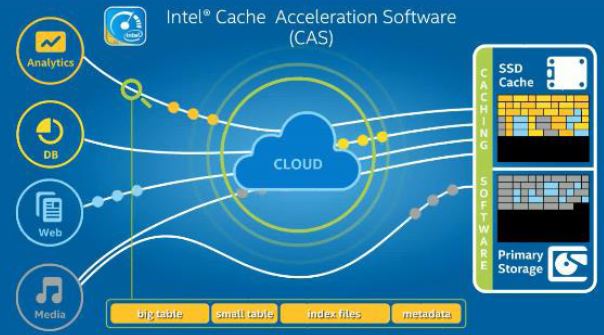
测试:
- 测试配置:使用 Intel NVMe SSD 做 Cache,使用 Intel CAS Linux 3.0 with hinting feature (今年年底将发布)
- 测试结果:5% 的 cache,使得吞吐量(ThroughOutput)提交了一倍,延迟(Latency)降低了一半
3. 使用更好的网络设备 - Mellanox 网卡和交换机等
3.1 更高带宽更低延迟的网卡设备
Mellanox 是一家总部在以色列的公司,全球约 1900 名员工,专注高端网络设备,2014 年revenue 为 ¥463.6M 。(今天正好在水木BBS上看到该公司在中国的分公司待遇也是非常好)。其主要观点和产品:
- Ceph 的 Scale Out 特性要求用于 replicaiton、sharing 和 metadata (文件)的网络吞吐量更高、延迟更低
- 目前 10 GbE(万兆以太网络) 已经不能满足高性能Ceph 集群的要求(基本上 20个 SSD 以上的集群就不能满足了),已经开始全面进入 25, 50, 100 GbE 时代。目前,25GbE 性价比比较高。
- 大部分网络设备公司使用的是高通的芯片,而 Mellanox 使用自研的芯片,其延迟(latency)是业界最低的(220ns)
- Ceph 高速集群需要使用两个网络:public network 用于客户端访问,Cluster network 用于 heartbeat、replication、recovery 和 re-balancing。
- 目前 Ceph 集群广泛采用 SSD, 而快速的存储设备就需要快速的网络设备
实际测试:
(1)测试环境:Cluster network 使用 40GbE 交换机,Public network 分布使用 10 GbE 和 40GbE 设备做对比

(2)测试结果:结果显示,使用 40GbE 设备的集群的吞吐量是使用 10 GbE 集群的 2.5 倍,IOPS 则提高了 15%。
目前,已经有部分公司使用该公司的网络设备来生产全SSD Ceph 服务器,比如,SanDisk 公司的 InfiniFlash 就使用了该公司的 40GbE 网卡、2个 Dell R720 服务器作为 OSD 节点、512 TB SSD,它的总吞吐量达到 71.6 Gb/s,还有富士通和Monash 大学。
3.2 RDMA 技术
传统上,访问硬盘存储需要几十毫秒,而网络和协议栈需要几百微妙。这时期,往往使用 1Gb/s 的网络带宽,使用 SCSI 协议访问本地存储,使用 iSCSI 访问远端存储。而在使用 SSD 后,访问本地存储的耗时大幅下降到几百微秒,因此,如果网络和协议栈不同样提高的话,它们将成为性能瓶颈。这意味着,网络需要更好的带宽,比如40Gb/s 甚至 100Gb/s;依然使用 iSCSI 访问远端存储,但是 TCP 已经不够用了,这时 RDMA 技术应运而生。RDMA 的全称是 Remote Direct Memory Access,就是为了解决网络传输中服务器端数据处理的延迟而产生的。它是通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能.它消除了外部存储器复制和文本交换操作,因而能腾出总线空间和CPU 周期用于改进应用系统性能. 通用的做法需由系统先对传入的信息进行分析与标记,然后再存储到正确的区域。
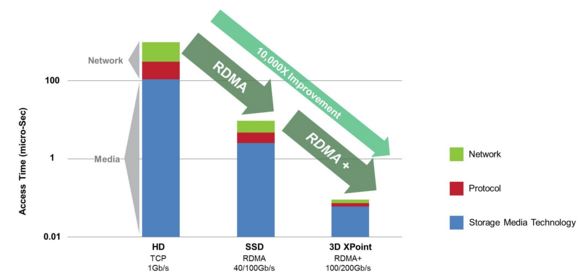
这种技术上,Mellanox 是业界领先者。它通过 Bypass Kenerl 和 Protocol Offload 的实现,提供高带宽、低CPU占用和低延迟。目前,该公司在 Ceph 中实现了 XioMessager,使得Ceph 消息不走 TCP 而走 RDMA,从而得以提高集群性能,该实现在 Ceph Hammer 版本中提供。
更多信息,可以参考:
http://www.mellanox.com/related-docs/solutions/ppt_ceph_mellanox_ceph_day.pdf
http://ir.mellanox.com/releasedetail.cfm?ReleaseID=919461
Mellanox Benchmarks Ceph on 100Gb Ethernet
<2015/11/26 更新>
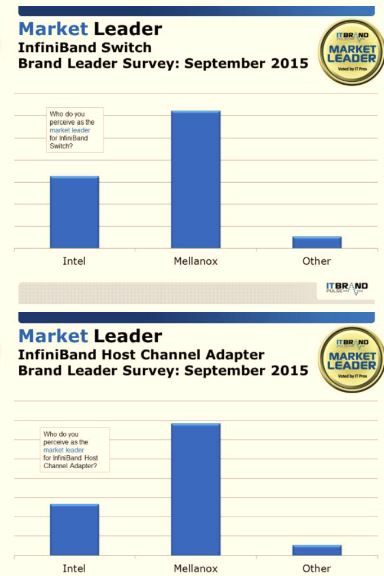
之前不熟悉这个公司,一个原因是其名字实在太长太难记了。今天看到西瓜哥的微信,才发现这个公司的Infiniband 交换机和 HBA 卡在美国数据中心里面的领导地位。唯一能和它竞争的就是Intel。
4. 使用更好的软件 - Intel SPDK 相关技术
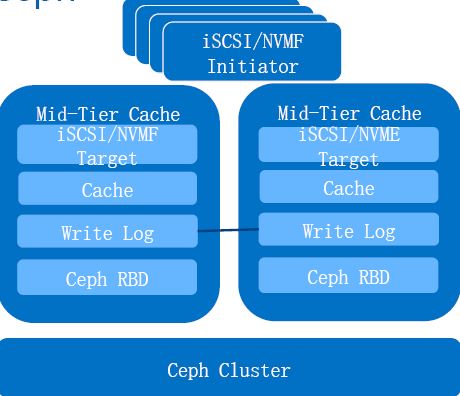
4.1 Mid-Tier Cache 方案
该方案在客户端应用和 Ceph 集群之间添加一个缓存层,使得客户端的访问性能得以提高。该层的特点:
- 对 Ceph 客户端提供 iSCSI/NVMF/NFS 等协议支持;
- 使用两个或者多个节点提高可靠性;
- 添加了Cache,提高访问速度
- 使用 write log 保证多节点之间数据一致性
- 使用 RBD 连接后端Ceph集群
4.2 使用 Intel DPDK 和 UNS 技术
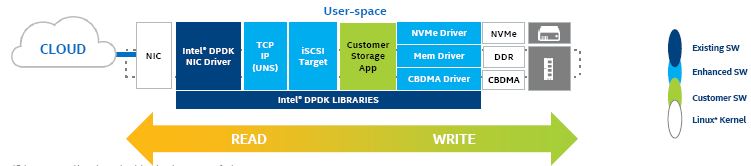
Intel 使用该技术,在用户空间(user space)实现了全 DPDK 网卡及驱动、TCP/IP协议栈(UNS)、 iSCSI Target,以及 NVMe 驱动,来提高Ceph的 iSCSI 访问性能。好处:
- 与 Linux*-IO Target (LIO) 相比,其 CPU overhead 仅为 1/7。
- 用户空间的 NVMe 驱动比内核空间的 VNMe 驱动的 CPU 占用少 90%
该方案的一大特点是使用用户态网卡,为了避免和内核态的网卡冲突,在实际配置中,可以通过 SRIOV 技术,将物理网卡虚拟出多个虚拟网卡,在分配给应用比如OSD。通过完整地使用用户态技术,避免了对内核版本的依赖。
目前,Intel 提供 Intel DPDK、UNS 、优化后的 Storage 栈作为参考性方案,使用的话需要和 Intel 签订使用协议。用户态NVMe驱动已经开源。
4.3 CPU 数据存放加速 - ISA-L 技术
该代码库(code libaray)使用 Intel E5-2600/2400 和 Atom C2000 product family CPU 的新指令集来实现相应算法,最大化地利用CPU,大大提高了数据存取速度,但是,目前只支持单核 X64 志强和 Atom CPU。在下面的例子中,EC 速度得到几十倍提高,总体成本减少了百分之25到30.

5. 使用系统的工具和方法 - Ceph 性能测试和调优工具汇总
本次会议上,还发布了若干Ceph 性能测试和调优工具。
5.1 Intel CeTune
Intel的该工具可以用来部署、测试、分析和调优(deploy, benchmark, analyze and tuning)Ceph 集群,目前它已经被开源,代码 在这里。主要功能包括:
- 用户可以对 CeTune 进行配置,使用其 WebUI
- 部署模块:使用 CeTune Cli 或者 GUI 部署 Ceph
- 性能测试模块:支持 qemurbd, fiorbd, cosbench 等做性能测试
- 分析模块:iostat, sar, interrupt, performance counter 等分析工具
- 报告视图:支持配置下载、图标视图
5.2 常见的性能测试和调优工具
Ceph 软件栈(可能的性能故障点和调优点):
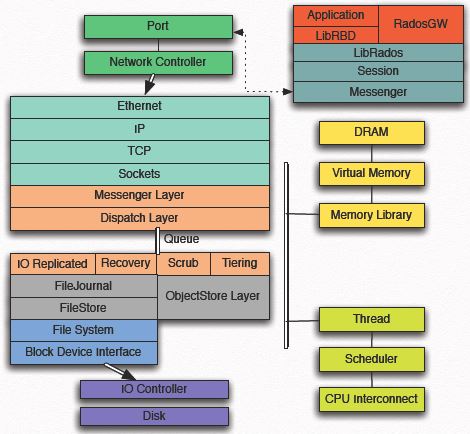
可视性性能相关工具汇总:

Benchmarking 工具汇总:

调优工具汇总:

6. 综合评价
上面的几种方法,与传统的性能优化方法相比,部分具有其创新性,其中,
- 更好的硬件,包括SSD和网络设备,自然能带来更好的性能,但是成本也相应增加,而且带来的性能优化幅度具有不一致性,因此,需要在应用场景、成本、优化效果之间做综合权衡;
- 更好的软件,目前大都还没有开源,而且大都还处于测试状态,离在生产环境中使用尚有距离,而且都和 Intel 的硬件紧密绑定;
- 更全面的方法,则是广大 Ceph 专业人员需要认真学习、使用到的,在平时的使用中能够更高效的定位性能问题并找到解决方法;
- Intel 在 Ceph 上的投入非常大,客户如果有Ceph集群性能问题,还可以把相关数据发给他们,他们会提供相应建议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号