
本次作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
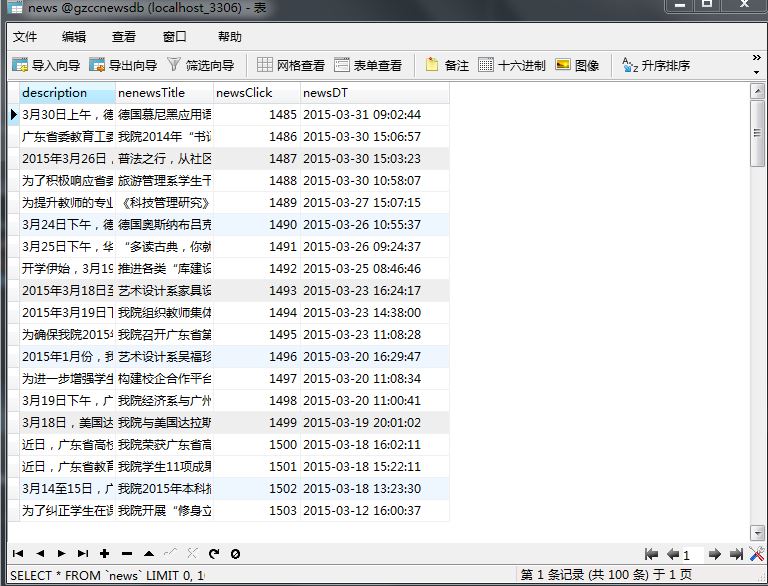
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
![]()
![]()


二.爬虫综合大作业
1.选择一个热点或者你感兴趣的主题。
2.选择爬取的对象与范围。
3.了解爬取对象的限制与约束。
4.爬取相应内容。
5.做数据分析与文本分析。
6.形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
7.文章公开发布。
1.选取了
歌手:The Weeknd / Kendrick Lamar
的歌曲评论
2.对象和范围
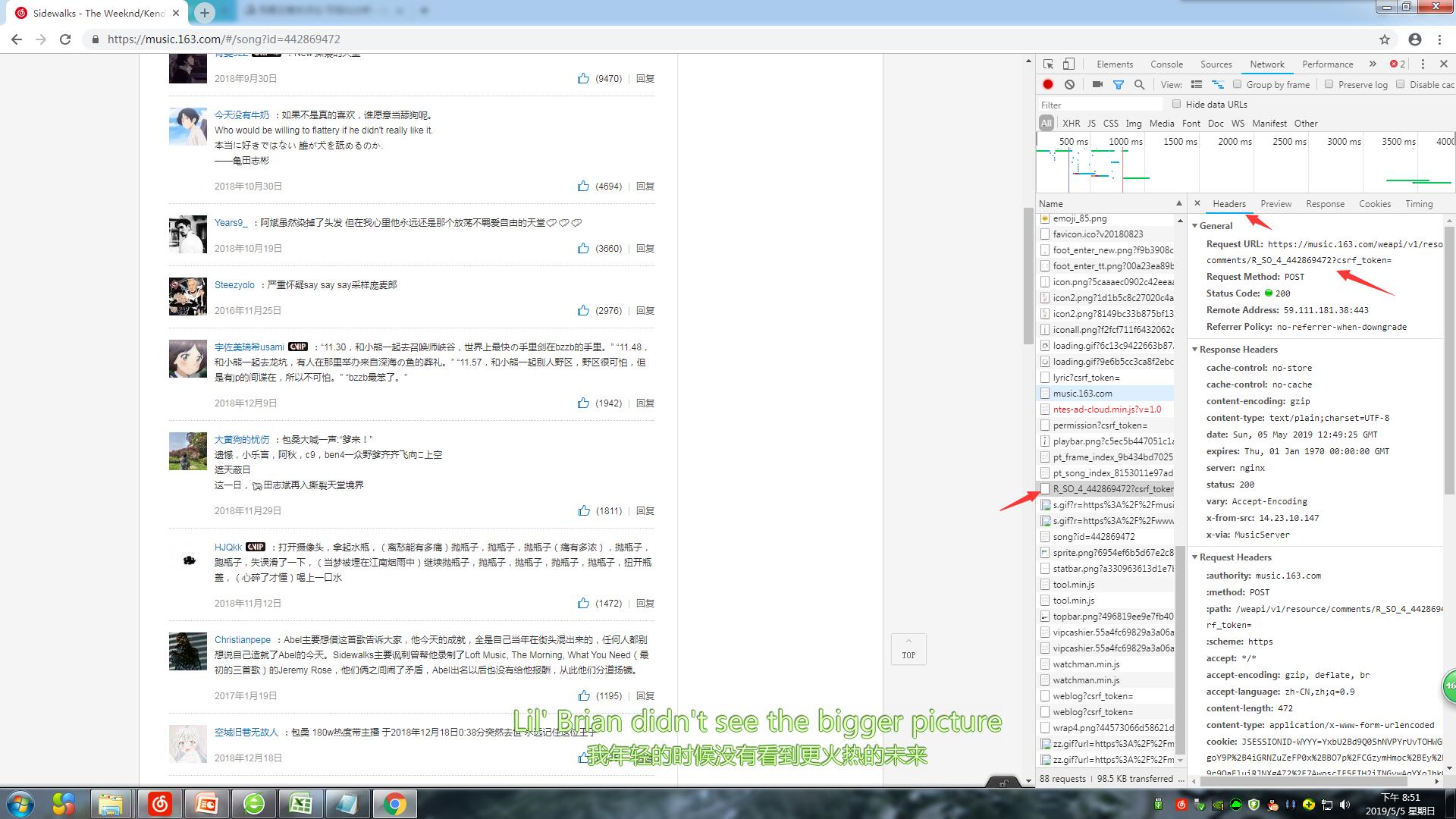
3.已经明白约束和限制
使用了网上获得的代理agent
4.爬取评论
保存到txt中:

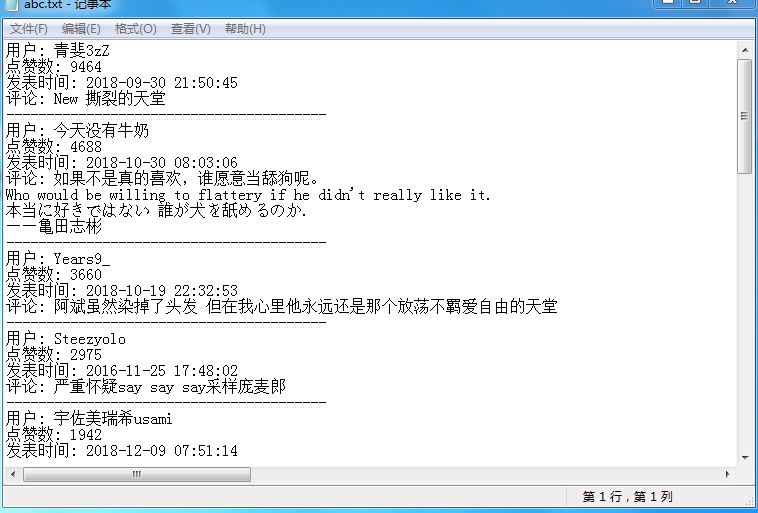

保存到excel中:

5.分析

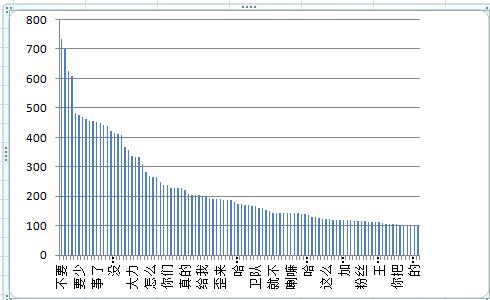
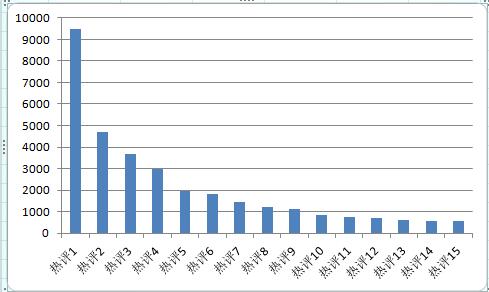

一般数据分析无非是采用(统计)数字、图或者表的形式来展现数据之中隐含的信息。其中图和表显然是最直观的了。所以这里我使用可视化的方法即用图形来展示从评论中挖掘到的各种信息。这次分析主要是几个方面:1.歌曲评论都是一些什么词汇 2.究竟是什么样的评论才能上热评 3.为什么评论带火一首歌
1.这首歌曲是从2016年11月25日开始有评论,最开始没有大热,它的评论区大热是从2018年年中开始。总体来说是一种一开始时间评论区评论数很少,后面因为某种原因呈爆发式增长。由于歌手逐渐出名,这种实力歌曲评论自然猛涨,后来这段热潮过去了,评论数就降下来了。不过这首歌某直播平台某知名主播使用后,评论区就特别火。我觉得真正厉害的歌曲评论区都是稳定的,不会出现大起大落的评论数。不过实际上不是每一首歌曲的评论区都是这种模式发展的。
2.歌曲评论都是某直播平台某主播的直播词汇,基本都演化成了梗。粉丝们在评论区里评论了关于直播的内容,其实这些内容都与歌曲无关,但是也为歌曲评论区热度的提高贡献了一份力量。比如包桑、深海鱼、加大力度、CCC、那没事了、梁志彬等等。
3.我们来看看什么样的评论可以上热评。根据数据图表发现热评都有成千上百的点赞数,但是基本上都是不与歌曲相关的评论,都是一些与某直播平台某主播有关的评论。点赞数最多的评论,这些评论能够快速且强烈的引起广大用户的共鸣。字数长短不一的评论,不过都能表达出自己的观点,引发其余听众的情感共鸣更是成为热评的关键。
4.网易云音乐虽然在歌曲版权的争取上有一定的劣势,但是其中的评论区有一说一还是对网易云音乐的发展起到了很大的推动作用。通过对其中一首由网络主播带火的歌曲评论区,看出它的产品竞争力和新鲜感是不容小看的。
源码:
import urllib.request
import http.cookiejar
import urllib.parse
import json
import time
import codecs
from Crypto.Cipher import AES
import base64
import os
class music:
#初始化
def __init__(self):
#设置代理,以防止本地IP被封
self.proxyUrl = "http://202.106.16.36:3128"
#request headers,这些信息可以在ntesdoor日志request header中找到,copy过来就行
self.Headers = {
'Accept': "*/*",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "music.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"
}
# 使用http.cookiejar.CookieJar()创建CookieJar对象
self.cjar = http.cookiejar.CookieJar()
# 使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象
self.cookie = urllib.request.HTTPCookieProcessor(self.cjar)
self.opener = urllib.request.build_opener(self.cookie)
# 将opener安装为全局
urllib.request.install_opener(self.opener)
#第二个参数
self.second_param = "010001"
#第三个参数
self.third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
#第四个参数
self.forth_param = "0CoJUm6Qyw8W8jud"
def get_params(self, page):
#获取encText,也就是params
iv = "0102030405060708"
first_key = self.forth_param
second_key = 'F' * 16
if page == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
else:
offset = str((page - 1) * 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset, 'false')
self.encText = self.AES_encrypt(first_param, first_key, iv)
self.encText = self.AES_encrypt(self.encText.decode('utf-8'), second_key, iv)
return self.encText
def AES_encrypt(self, text, key, iv):
#AES加密
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
encrypt_text = encryptor.encrypt(text.encode('utf-8'))
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_encSecKey(self):
#获取encSecKey
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def get_json(self, url, params, encSecKey):
# post所包含的参数
self.post = {
'params': params,
'encSecKey': encSecKey,
}
# 对post编码转换
self.postData = urllib.parse.urlencode(self.post).encode('utf8')
try:
#发出一个请求
self.request = urllib.request.Request(url,self.postData,self.Headers)
except urllib.error.HTTPError as e:
print(e.code)
print(e.read().decode("utf8"))
#得到响应
self.response = urllib.request.urlopen(self.request)
#需要将响应中的内容用read读取出来获得网页代码,网页编码为utf-8
self.content = self.response.read().decode("utf8")
#返回获得的网页内容
return self.content
def get_hotcomments(self, url):
#获取热门评论
params = self.get_params(1)
encSecKey = self.get_encSecKey()
content = self.get_json(url, params, encSecKey)
json_dict = json.loads(content)
hot_comment = json_dict['hotComments']
f = open('C:\\Users\\Administrator\\Desktop\\abc.txt', 'w', encoding='utf-8')
for i in hot_comment:
#将评论输出至txt文件中
time_local = time.localtime(int(i['time'] / 1000)) # 将毫秒级时间转换为日期
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
f.write('用户: ' + i['user']['nickname'] + '\n')
f.write('点赞数: ' + str(i['likedCount']) + '\n')
f.write('发表时间: ' + dt + '\n')
f.write('评论: ' + i['content'] + '\n')
f.write('-' * 40 + '\n')
f.close()
def get_allcomments(self, url):
#获取全部评论
params = self.get_params(1)
encSecKey = self.get_encSecKey()
content = self.get_json(url, params, encSecKey)
json_dict = json.loads(content)
comments_num = int(json_dict['total'])
f = open('C:\\Users\\Administrator\\Desktop\\abcd.txt', 'w', encoding='utf-8')
present_page = 0
if (comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
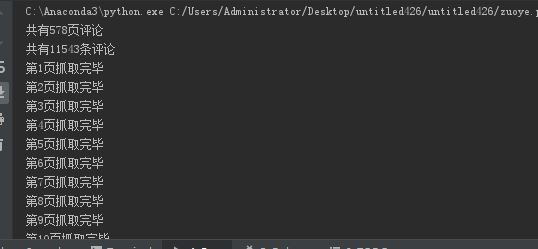
print("共有%d页评论" % page)
print("共有%d条评论" % comments_num)
# 逐页抓取
for i in range(page):
params = self.get_params(i + 1)
encSecKey = self.get_encSecKey()
json_text = self.get_json(url, params, encSecKey)
json_dict = json.loads(json_text)
present_page = present_page + 1
for i in json_dict['comments']:
# 将评论输出至txt文件中
time_local = time.localtime(int(i['time'] / 1000))# 将毫秒级时间转换为日期
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
f.write('用户: ' + i['user']['nickname'] + '\n')
f.write('点赞数: ' + str(i['likedCount']) + '\n')
f.write('发表时间: ' + dt + '\n')
f.write('评论: ' + i['content'] + '\n')
f.write('-' * 40 + '\n')
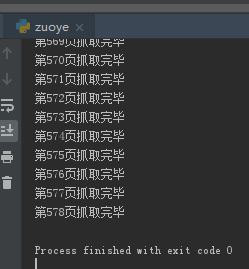
print("第%d页抓取完毕" % present_page)
f.close()
mail = music()
mail.get_hotcomments("https://music.163.com/weapi/v1/resource/comments/R_SO_4_442869472?csrf_token=")
mail.get_allcomments("https://music.163.com/weapi/v1/resource/comments/R_SO_4_442869472?csrf_token=")
