
hadoop深入学习之SequenceFile
大数据学习篇:hadoop深入浅出系列之HDFS(七) ——小文件解决方案 - 美丽的泡沫 - CSDN博客 - http://blog.csdn.net/stronglyh/article/details/48751749#
上一篇文章讲了HDFS的java操作,今天讲HDFS的小文件解决方案
小文件指的是那些size比HDFS的block size(默认128M)小的多的文件。任何一个文件,目录和block,在HDFS中都会被表示为一个object存储在namenode的内存中,每一个object占用150 bytes的内存空间。所以,如果有10million个文件,每一个文件对应一个block,那么就将要消耗namenode 3G的内存来保存这些block的信息。如果规模再大一些,那么将会超出现阶段计算机硬件所能满足的极限。
重点说下几种解决方案
1)应用程序自己控制
2)archive
3)Sequence File
4)Map File
5)合并小文件,如Hbase部分的compact
6)*CombineFileInputFormat
一)应用程序控制
向hdfs写数据的时候,先把文件都合并在一起了,如果你再想看每个合并的文件,那是不可能的哟
final Path path = new Path("/combinedfile");
final FSDataOutputStream create = fs.create(path);
final File dir = new File("C:\\Windows\\System32\\drivers\\etc");
for(File fileName : dir.listFiles()) {
System.out.println(fileName.getAbsolutePath());
final FileInputStream fileInputStream = new FileInputStream(fileName.getAbsolutePath());
final List<String> readLines = IOUtils.readLines(fileInputStream);
for (String line : readLines) {
create.write(line.getBytes());
}
fileInputStream.close();
}
create.close();
使用情况:如果你每天产生日志文件,但是你需要按月的文件,就可以这样搞
二)archive 归档
Hadoop Archives (HAR files)是在0.18.0版本中引入的,它的出现就是为了缓解大量小文件消耗namenode内存的问题。HAR文件是通过在HDFS上构建一个层次化的文件系统来工作。一个HAR文件是通过hadoop的archive命令来创建,而这个命令实 际上也是运行了一个MapReduce任务来将小文件打包成HAR。对于client端来说,使用HAR文件没有任何影响。所有的原始文件都 (using har://URL)。但在HDFS端它内部的文件数减少了。
通过HAR来读取一个文件并不会比直接从HDFS中读取文件高效,而且实际上可能还会稍微低效一点,因为对每一个HAR文件的访问都需要完成两层 index文件的读取和文件本身数据的读取。并且尽管HAR文件可以被用来作为MapReduce job的input,但是并没有特殊的方法来使maps将HAR文件中打包的文件当作一个HDFS文件处理。
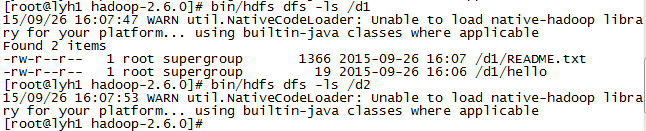
把每个小文件放到一个har包中,如下,首先检查下d1和d2文件夹,发现d1有两个文件 大小分别是1366和19,d2没有文件,现在我们执行har命令
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
bin/hadoop archive -archiveName test.har -p /d1 /d2
其中test.har 是文件名 d1是要被打包的文件夹 d2是目标文件夹
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
之后,我们回到d2中,查看多了一个test.har文件,再细看一下前面居然是d,代表文件类型是目录
-----------------------------------------------------------------------------

-----------------------------------------------------------------------------
既然是个目录,就可以使用ls查看
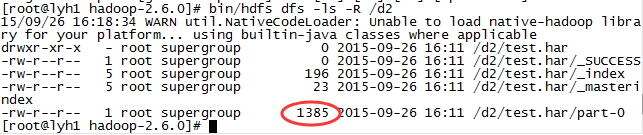
-----------------------------------------------------------------------------
我们看到了一个大小为1385的文件,正好是刚才d1中两个文件的大小之和(1366+19),原来只是合并啊,没有压缩,har的作用就是把大量的小文件打包存放
那么是否可以查看合并之和的内容呢。当然可以了
hadoop fs -lsr har:///dest/xxx.har
注:相对于应用程序合并来说,har归档之后的文件打包是可以查看的
1.Hadoop’s SequenceFile
三)Sequence File
通常对于“the small files problem”的回应会是:使用SequenceFile。这种方法是说,使用filename作为key,并且file contents作为value。实践中这种方式非常管用。回到10000个100KB的文件,可以写一个程序来将这些小文件写入到一个单独的 SequenceFile中去,然后就可以在一个streaming fashion(directly or using mapreduce)中来使用这个sequenceFile。不仅如此,SequenceFiles也是splittable的,所以mapreduce 可以break them into chunks,并且分别的被独立的处理。和HAR不同的是,这种方式还支持压缩。block的压缩在许多情况下都是最好的选择,因为它将多个 records压缩到一起,而不是一个record一个压缩。
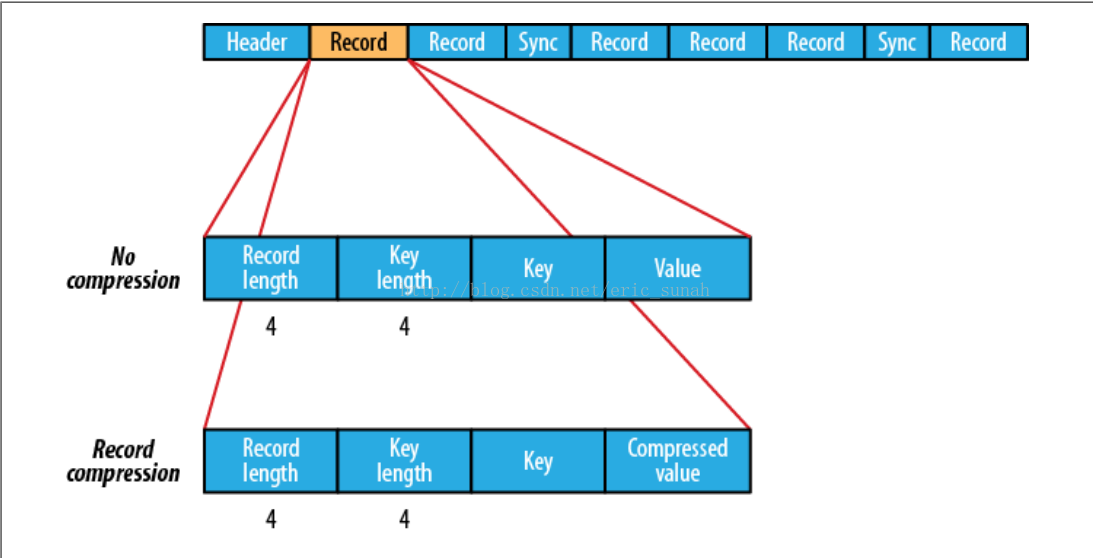
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成。
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
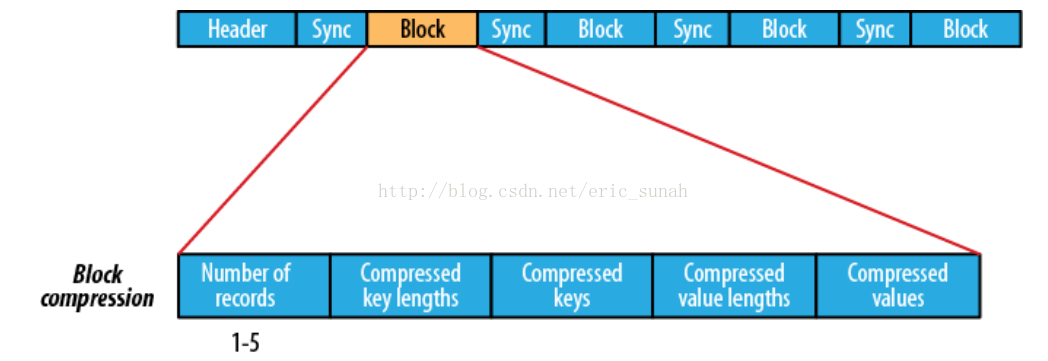
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
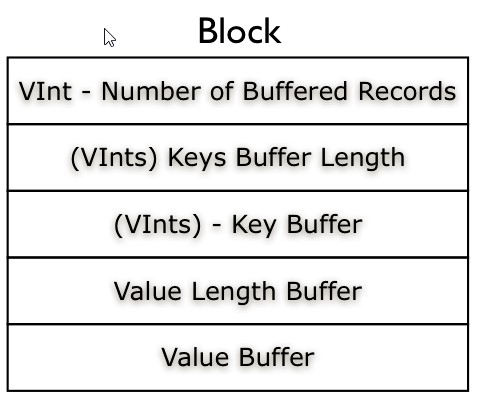
block compression是将一连串的record组织到一起,统一压缩成一个block,如下图。
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的。
SequenceFile是键值对的形式:
FileSystem fs=FileSystem.get(conf);Path seqFile=new Path("seqFile.seq");
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
//通过writer向文档中写入记录writer.append(new Text("key"),new Text("value"));IOUtils.closeStream(writer);//关闭write流
//Reader内部类用于文件的读取操作SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
//通过reader从文档中读取记录Text key=new Text();Text value=new Text();while(reader.next(key,value)){ System.out.println(key); System.out.println(value);}IOUtils.closeStream(reader);//关闭read流SequenceFile 是 Hadoop 的一个重要数据文件类型,它提供key-value的存储,但与传统key-value存储(比如hash表,btree)不同的是,它是 appendonly的,于是你不能对已存在的key进行写操作。In contrast with other persistent key-value data structures like B-Trees, you can’t seek to a specified key editing, adding or removing it. This file is append-only.

文件的压缩态标识在文件开头的header数据中。在header数据之后是一个Metadata数据,他是简单的属性/值对,标识文件的一些其他信息。SequenceFile has 3 available formats: An “Uncompressed” format, A “Record Compressed” format and a “Block-Compressed”. All of them share a header that contains some information which allows the reader to recognize is format. There’re Key and Value Class Name’s that allow the reader to instantiate those classes, via reflection, for reading. The version number and format (Is Compressed, Is Block Compressed), if compression is enabled the Compression Codec class name field is added to the header.
格式
每一个SequenceFile都包含一个“头”(header)。Header包含了以下几部分。
1.SEQ三个字母的byte数组
2.Version number的byte,目前为数字3的1个byte
3.Key和Value的类名
4.压缩相关的信息
5.其他用户定义的元数据
6.同步标记,sync marker
Metadata 在文件创建时就写好了,所以也是不能更改的。The sequence file also can contain a “secondary” key-value list that can be used as file Metadata. This key-value list can be just a Text/Text pair, and is written to the file during the initialization that happens in the SequenceFile.Writer constructor, so you can’t edit your metadata.


SequenceFile 有三种压缩态(压缩格式):
“Uncompressed” format– 未进行压缩的状态
“Record Compressed” format - 对每一条记录的value值进行了压缩(文件头中包含上使用哪种压缩算法的信息)
“Block-Compressed” – 当数据量达到一定大小后,将停止写入进行整体压缩,整体压缩的方法是把所有的keylength,key,vlength,value 分别合在一起进行整体压缩
每一个key-value记录如下图,不仅保存了key,value值,也保存了他们的 长度。
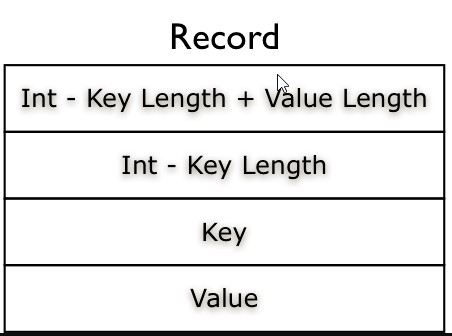
记录(Record): Hadoop SequenceFile的存储格式是通用的KV数据存储格式,key和value都是变长二进制数据。Record Len 表示的是key 和value 的占用的byte之和,Record压缩方式中 key 是不压缩。同步点Sync 作用数据恢复和扫描。当指定读取的位置不是记录首部的时候,通过读取一个同步点的记录,不至于读取数据的reader “迷失”。 (hadoop实现:每2000byte 就插入一个同步点,这个同步点占16 byte ,包括同步点标示符:4byte ,一个同步点的开销是20byte 。)对二进制数据,任何字符都可出现,故采用单字节的Sync标识难于区分数据和同步点,需要采用多字节的Sync(什么样的多个字节常被用来所Sync标识?0xFFFFFFFFFFFFFFFF?)。
块(Block):存储Block header和多个record数据。Hadoop SequenceFile可认为没有块概念,只有Block-Compressed SequenceFile才会将多个record压缩后一起存储,详见hadoop文档。
对于每一条记录(K-V),其内部格式根据是否压缩而不同。SequenceFile的压缩方式有两种,“记录压缩”(record compression)和“块压缩”(block compression)。如果是记录压缩,则只压缩Value的值。如果是块压缩,则将多条记录一并压缩,包括Key和Value。具体格式如下面两图所示:
2.MapFile, SetFile, ArrayFile 及 BloomMapFile
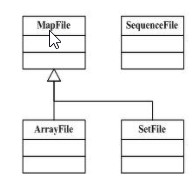
SequenceFile 是Hadoop 的一个基础数据文件格式,后续讲的 MapFile, SetFile, ArrayFile 及 BloomMapFile 都是基于它来实现的。Hadoop SequenceFile is the base data structure for the other types of files, like MapFile, SetFile, ArrayFile and BloomMapFile.
四)MapFile
MapFile是有序的,方便查找,以前的hadoop的底层用就是MapFile,现在不是了,但是他依然有意义。
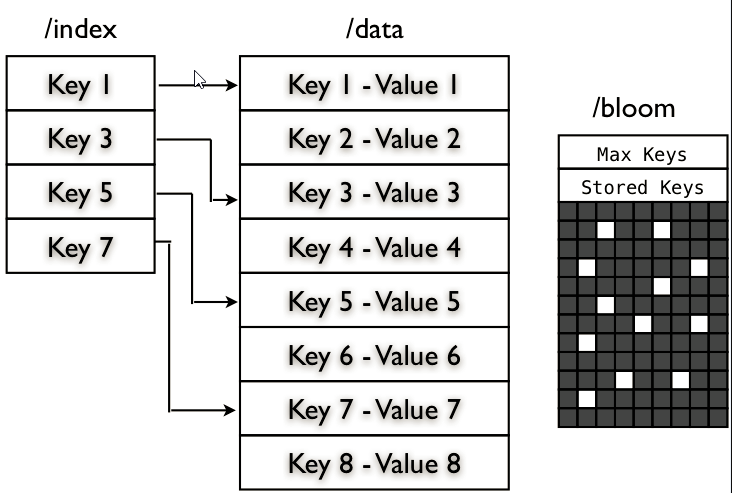
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
FileSystem fs=FileSystem.get(conf); Path mapFile=new Path("mapFile.map"); //Writer内部类用于文件的写操作,假设Key和Value都为Text类型 MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class); //通过writer向文档中写入记录 writer.append(new Text("key"),new Text("value")); IOUtils.closeStream(writer);//关闭write流 //Reader内部类用于文件的读取操作 MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf); //通过reader从文档中读取记录 Text key=new Text(); Text value=new Text(); while(reader.next(key,value)){ System.out.println(key); System.out.println(key); } IOUtils.closeStream(reader);//关闭read流
MapFile
一个key-value 对应的查找数据结构,由数据文件/data 和索引文件 /index 组成,数据文件中包含所有需要存储的key-value对,按key的顺序排列。索引文件包含一部分key值,用以指向数据文件的关键位置。
来源: http://blog.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
The MapFile is a directory that contains two SequenceFile: the data file (“/data”) and the index file (“/index”). The data contains all the key, value records but key N + 1 must be greater then or equal to the key N. This condition is checked during the append() operation, if checkKey fail it throws an IOException “Key out of order”.
The Index file is populated with the key and a LongWritable that contains the starting byte position of the record. Index does’t contains all the keys but just a fraction of the keys, you can specify the indexInterval calling setIndexInterval() method. The Index is read enteirely into memory, so if you’ve large map you can set a index skip value that allows you to keep in memory just a fraction of the index keys.
SetFile – 基于 MapFile 实现的,他只有key,value为不可变的数据。SetFile and ArrayFile are based on MapFile, and their implementation are just few lines of code. The SetFile instead of append(key, value) as just the key field append(key) and the value is always the NullWritable instance.
ArrayFile – 也是基于 MapFile 实现,他就像我们使用的数组一样,key值为序列化的数字。The ArrayFile as just the value field append(value) and the key is a LongWritable that contains the record number, count + 1.
BloomMapFile – 他在 MapFile 的基础上增加了一个 /bloom 文件,包含的是二进制的过滤表,在每一次写操作完成时,会更新这个过滤表The BloomMapFile extends the MapFile adding another file, the bloom file “/bloom”, and this file contains a serialization of the DynamicBloomFilter filled with the added keys. The bloom file is written entirely during the close operation.
If you want to play with SequenceFile, MapFile, SetFile, ArrayFile without using Java, I’ve written a naive implementation in python. You can find it, in my github repository python-hadoop.
![]()

参考url
--------------------------------
1.Hadoop I/O: Sequence, Map, Set, Array, BloomMap Files - Cloudera Engineering Blog
http://blog.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
== 以上 2017/7/6 下午5:29:17
--------------------------------
1.[hadoop源码阅读][4]-org.apache.hadoop.io - 阿笨猫 - 博客园
http://www.cnblogs.com/xuxm2007/archive/2012/06/15/2550986.html
== 以上 2017/7/6 下午5:06:26
http://hadoop.apache.org/common/docs/r0.20.2/api/index.html
http://blog.csdn.net/ludi7125/article/details/7605719
http://www.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
http://blog.nosqlfan.com/html/1217.html
http://jerrylead.iteye.com/blog/1181716
http://www.itivy.com/arch/archive/2011/12/12/hadoop-writable-interface-introduction.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号