已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小。
写在前面:
用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述。
但是对于根据generate_from_frequencies()给定词频如何画词云图的资料找了很久,下面只讲这种方法。
generate_from_frequencies适用于我已知词及其对应的词频是多少(已有数据库),不需要分词的情况下。
官方文档说generate_from_frequencies函数的参数是array of tuple,但是我试了很久都不行,最后发现居然应该是dict 字典形式!
即形如:{ word1: fre1, word2: fre2, word3: fre3,......, wordn: fren }
注意:
词云wordcloud的中文显示,需要特殊处理,在网上看了不少是说加字体路径之类的方法我试了都不行,最后只好采用改变编码的形式才解决好。
1 | fp = pd.read_csv(read_name, encoding='gbk') # 读取词频csv文件, 编码为gbk |
还有,示例词云的轮廓背景图由china_map.jpg给出,如下图:
一、数据文件准备
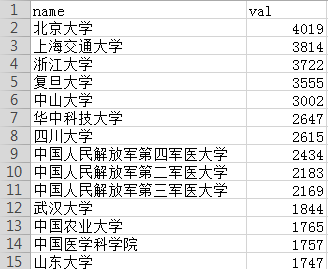
support_institution.csv
数据库字段分组查询数量
1 | select support_institution name,count(support_institution) value from nsfc GROUP BY name ORDER BY value DESC; |
查询结果部分截图:

导出为csv文件:support_institution.csv
二、导入模块包
可参考Windows下安装Python、matplotlib包 及相关
https://blog.csdn.net/mikasa3/article/details/78942650
1、numpy
2、pandas
3、wordcloud
4、matplotlib
三、完整代码

import numpy as np
import pandas as pd
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image
def draw_cloud(read_name):
image = Image.open('china_map.jpg') # 作为背景轮廓图
graph = np.array(image)
# 参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状
wc = WordCloud(font_path='simkai.ttf', background_color='black', max_words=100, mask=graph)
fp = pd.read_csv(read_name, encoding='gbk') # 读取词频文件, 因为要显示中文,故编码为gbk
name = list(fp.name) # 词
value = fp.val # 词的频率
for i in range(len(name)):
name[i] = str(name[i])
dic = dict(zip(name, value)) # 词频以字典形式存储
wc.generate_from_frequencies(dic) # 根据给定词频生成词云
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off") # 不显示坐标轴
plt.show()
wc.to_file('nsfc依托单位词云.png') # 图片命名
if __name__ == '__main__':
draw_cloud("support_institution.csv")
四、运行结果
词云图:

五、补充:WordCloud的参数详解


WordCloud(font_path='', width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9, mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None, background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling=0.5, regexp=None, collocations=True, colormap=None, normalize_plurals=True )
font_path : string # 字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf' width : int (default=400) # 输出的画布宽度,默认为400像素 height : int (default=200) # 输出的画布高度,默认为200像素 prefer_horizontal : float (default=0.90) # 词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 ) mask : nd-array or None (default=None) # 如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。 # 如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。 scale : float (default=1) # 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。 min_font_size : int (default=4) # 显示的最小的字体大小 font_step : int (default=1) # 字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。 max_words : number (default=200) # 要显示的词的最大个数 stopwords : set of strings or None # 设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS background_color : color value (default=”black”) # 背景颜色,如background_color='white',背景颜色为白色。 max_font_size : int or None (default=None) # 显示的最大的字体大小 mode : string (default=”RGB”) # 当参数为“RGBA”并且background_color不为空时,背景为透明。 relative_scaling : float (default=.5) # 词频和字体大小的关联性 color_func : callable, default=None # 生成新颜色的函数,如果为空,则使用 self.color_func regexp : string or None (optional) # 使用正则表达式分隔输入的文本 collocations : bool, default=True # 是否包括两个词的搭配 colormap : string or matplotlib colormap, default=”viridis” # 给每个单词随机分配颜色,若指定color_func,则忽略该方法。
PS:以下内容可以不看,当然,看我也拦不住 ○( ^皿^)っHiahiahia…
上面的中国地图显示的词云并不好看(可能因为词语过长),所以补充一个好看的作品(*^▽^*)
2019国务院政府工作报告词云。
文本地址:
http://www.gov.cn/guowuyuan/baogao.htm
全文代码:
# coding:utf-8
import jieba # 分词
import matplotlib.pyplot as plt # 数据可视化
from wordcloud import WordCloud, ImageColorGenerator, STOPWORDS # 词云
import numpy as np # 科学计算
from PIL import Image # 处理图片
def draw_cloud(text, graph, save_name):
textfile = open(text).read() # 读取文本内容
wordlist = jieba.cut(textfile, cut_all=False) # 中文分词
space_list = " ".join(wordlist) # 连接词语
backgroud = np.array(Image.open(graph)) # 背景轮廓图
mywordcloud = WordCloud(background_color="white", # 背景颜色
mask=backgroud, # 写字用的背景图,从背景图取颜色
max_words=100, # 最大词语数量
stopwords=STOPWORDS, # 停用词
font_path="simkai.ttf", # 字体
max_font_size=200, # 最大字体尺寸
random_state=50, # 随机角度
scale=2,
collocations=False, # 避免重复单词
)
mywordcloud = mywordcloud.generate(space_list) # 生成词云
ImageColorGenerator(backgroud) # 生成词云的颜色
plt.imsave(save_name, mywordcloud) # 保存图片
plt.imshow(mywordcloud) # 显示词云
plt.axis("off") # 关闭保存
plt.show()
if __name__ == '__main__':
draw_cloud(text="government.txt", graph="china_map.jpg", save_name='2019政府工作报告词云.png')
词云图:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2018-08-06 函数的参数(必选,默认,可变,关键字)