TypeError: cannot use a string pattern on a bytes-like object
Downloading: http://example.webscraping.com/sitemap.xml Traceback (most recent call last): File "/Users/mac126/111/网站地图爬虫.py", line 14, in <module> crawler_sitemap('http://example.webscraping.com/sitemap.xml') File "/Users/mac126/111/网站地图爬虫.py", line 8, in crawler_sitemap links=re.findall('<loc>(.*?)</loc>',sitemap) File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/re.py", line 222, in findall return _compile(pattern, flags).findall(string) TypeError: cannot use a string pattern on a bytes-like object
#网站地图爬虫.py源码 import re from 爬虫下载网页 import download def crawler_sitemap(url): sitemap=download(url) links=re.findall('<loc>(.*?)</loc>',sitemap) for link in links: html=download(link) # print(html) crawler_sitemap('http://example.webscraping.com/sitemap.xml')
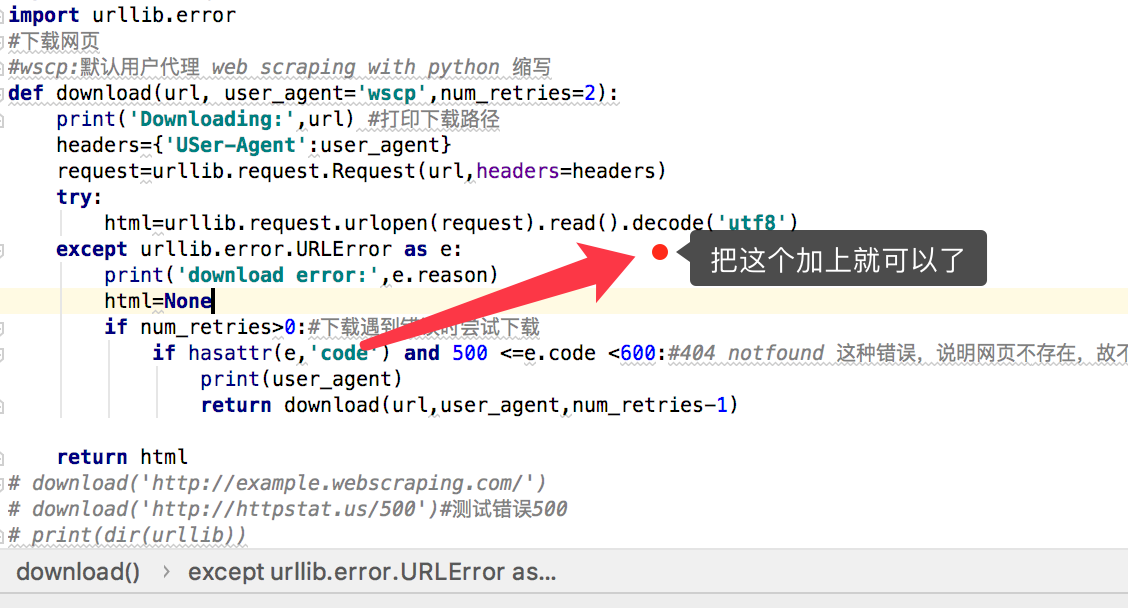
#下载网页 #具有功能:捕获异常,重试下载并设置用户代理 import urllib.request import urllib.error #下载网页 #wscp:默认用户代理 web scraping with python 缩写 def download(url, user_agent='wscp',num_retries=2): print('Downloading:',url) #打印下载路径 headers={'USer-Agent':user_agent} request=urllib.request.Request(url,headers=headers) try: html=urllib.request.urlopen(request).read() except urllib.error.URLError as e: print('download error:',e.reason) html=None if num_retries>0:#下载遇到错误时尝试下载 if hasattr(e,'code') and 500 <=e.code <600:#404 notfound 这种错误,说明网页不存在,故不需要重新下载 print(user_agent) return download(url,user_agent,num_retries-1) return html # download('http://example.webscraping.com/') # download('http://httpstat.us/500')#测试错误500 # print(dir(urllib))
解决方法如图: