
个人项目-论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | <设计一个论文查重的程序,加深对项目开发的理解,增强对程序的测试与纠错流程的了解> |
GITHUB地址:https://github.com/Hannibal00/Hannibal00
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 13 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | 730 |
| Development | 开发 | 500 | 550 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 13 |
| · Design Spec | · 生成设计文档 | 13 | 8 |
| · Design Review | · 设计复审 | 9 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 6 |
| · Design | · 具体设计 | 10 | 8 |
| · Coding | · 具体编码 | 60 | 60 |
| · Code Review | 代码复审 | 10 | 8 |
| · Test | 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | 30 | 36 |
| · Test Repor | 测试报告 | 20 | 30 |
| · Size Measurement | 计算工作量 | 10 | 11 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 18 |
| 合计 | 1382 | 1555 |
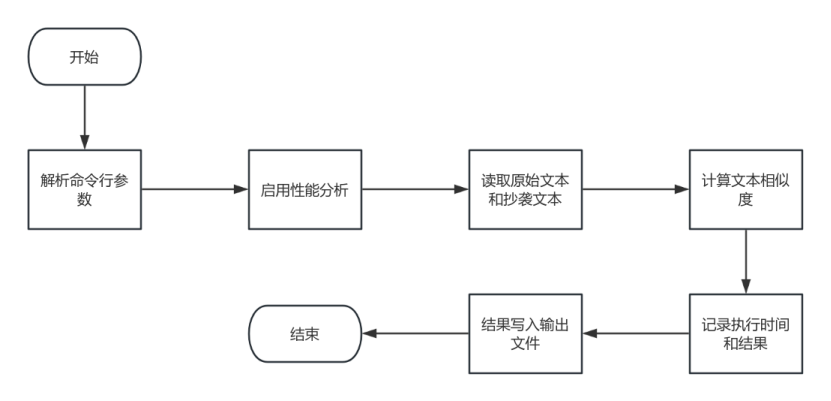
算法流程图
代码
导入库:
import sys
import difflib
import re
import string
import argparse
import logging
import time
import cProfile
import os # 添加了os模块用于检查文件是否存在
从文本中读取文件的函数:
def read_file(file_path):
if not os.path.exists(file_path):
print(f"File not found: {file_path}")
sys.exit(1)
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text
except Exception as e:
print(f"Error reading file: {str(e)}")
sys.exit(1)
用于清理文本的函数,例如去除标点符号
def clean_text(text):
text = re.sub(f"[{string.punctuation}]", '', text)
text = text.lower()
return text
计算文本相似度的函数
def calculate_similarity(original_text, plagiarized_text):
original_text = clean_text(original_text)
plagiarized_text = clean_text(plagiarized_text)
# 使用difflib库的SequenceMatcher来计算相似性
similarity = difflib.SequenceMatcher(None, original_text, plagiarized_text).ratio()
return round(similarity, 4)
主函数
def main():
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description="Check plagiarism between two text files")
parser.add_argument("original_file_path", type=str, help="Path to the original text file")
parser.add_argument("plagiarized_file_path", type=str, help="Path to the plagiarized text file")
parser.add_argument("output_file_path", type=str, help="Path to the output file")
args = parser.parse_args()
# 启用性能分析
profiler = cProfile.Profile()
profiler.enable()
#开始计时
start_time = time.time()
# 从文件读取原始文本和抄袭文本
original_text = read_file(args.original_file_path)
plagiarized_text = read_file(args.plagiarized_file_path)
# 计算文本相似度
similarity = calculate_similarity(original_text, plagiarized_text)
end_time = time.time()
# 将相似度写入输出文件
with open(args.output_file_path, 'w', encoding='utf-8') as output_file:
output_file.write(f"{similarity:.2f}\n")
# 显示运行时间和结果
print(f"Similarity: {similarity:.2f}")
print(f"Execution time: {end_time - start_time:.4f} seconds")
# 停止性能分析
profiler.disable()
profiler.print_stats(sort='cumulative')
本次查重算法的设计主要依靠引入的difflib库,我使用了其中的SequenceMatcher来计算两个文本中的相似性,为此我还设计了clean_text函数来对文本进行处理,为了方便进行代码的调试我还使用了cprofiler来进行性能分析。
运行过程
输入命令行指令
示例:python chachong.py "C:\Users\86180\Desktop\orig.txt" "C:\Users\86180\Desktop\orig_0.8_add.txt" "C:\Users\86180\Desktop\output.txt"
输出结果:
从上图可知对于抄袭文本的查重率高达91%,完成时间为0.248秒,效率可观。
性能分析
这里使用了python自带的cprofiler库进行分析
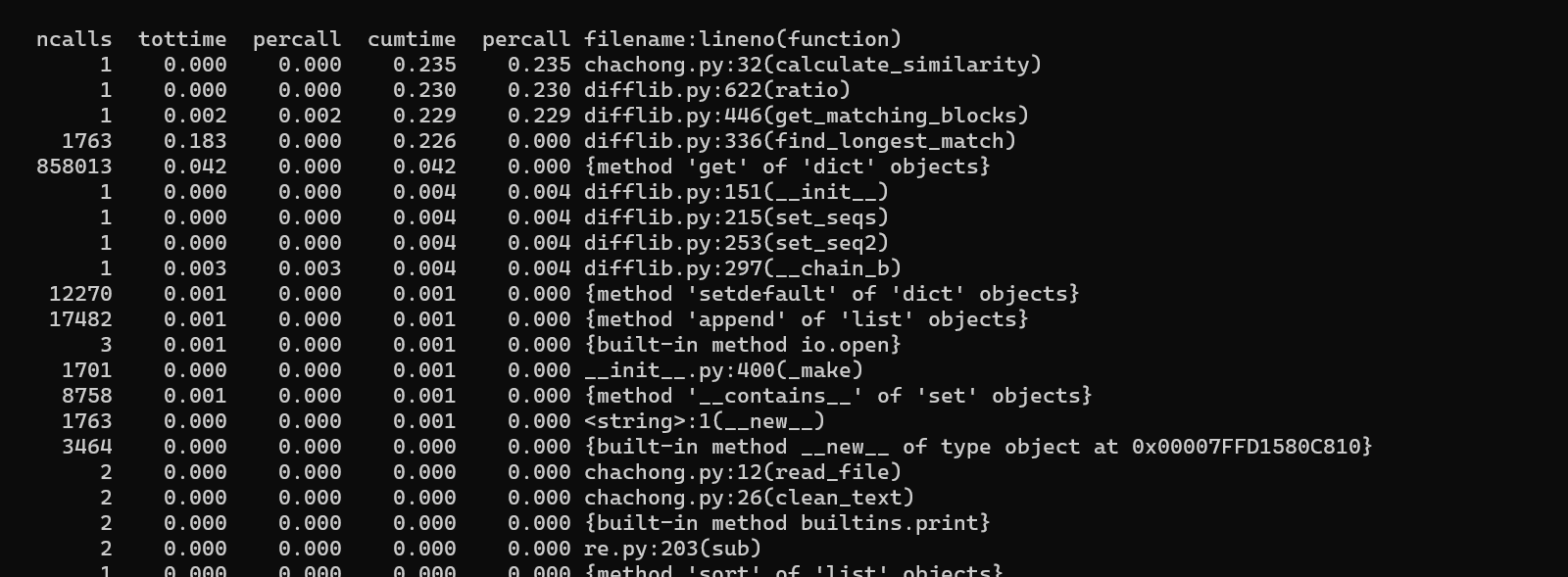
可以在这里看出分析文本时所花费的时间是最多的
单元测试
这里运用了coverage工具来计算覆盖率
对于初始命令python chachong.py "C:\Users\86180\Desktop\orig.txt" "C:\Users\86180\Desktop\orig_0.8_add.txt" "C:\Users\86180\Desktop\output.txt"的覆盖率
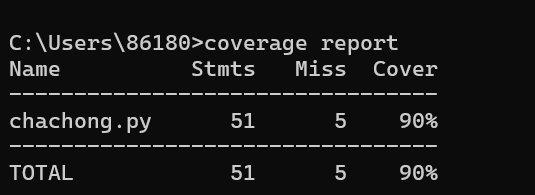
此时代码覆盖率为90%
接下来测试一个删除了部分文本的文本文件:
运行结果:
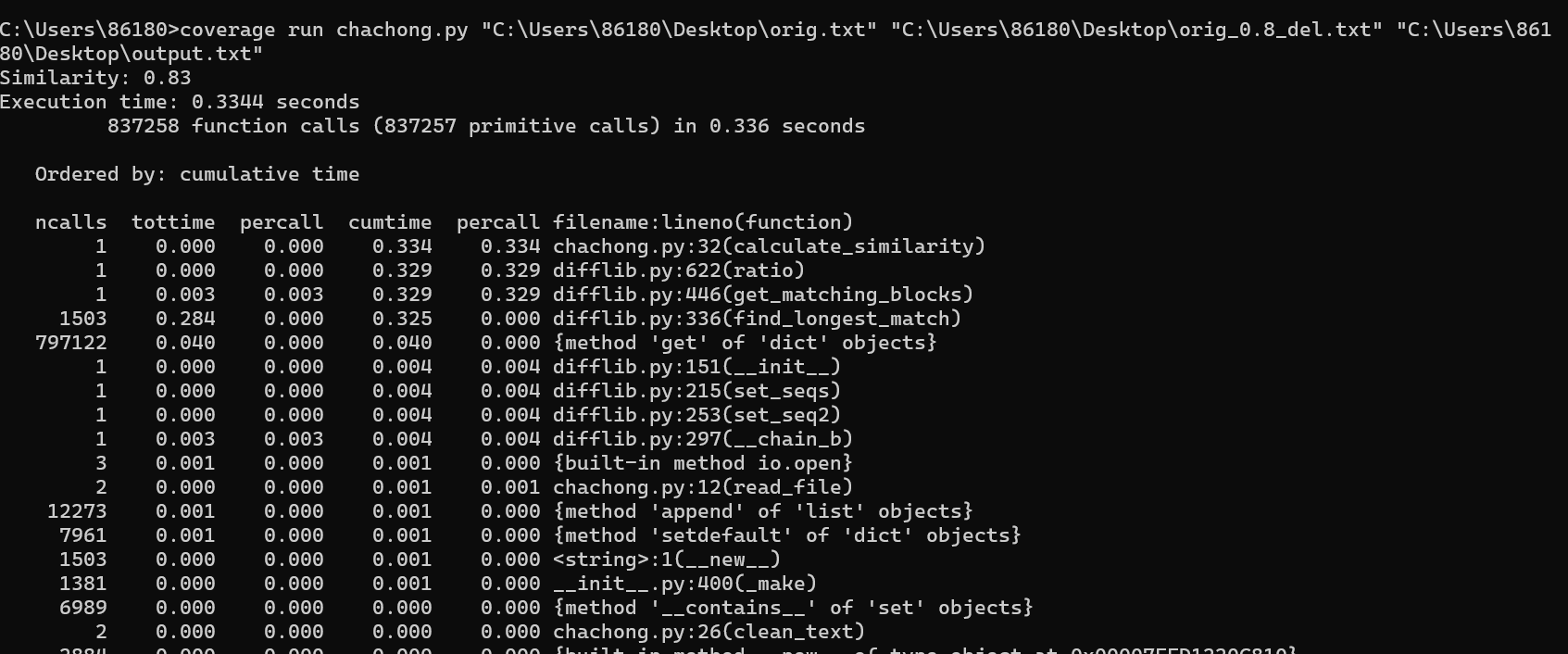
代码覆盖率:

依然为90%
测试一个文字乱序的文本
运行结果:
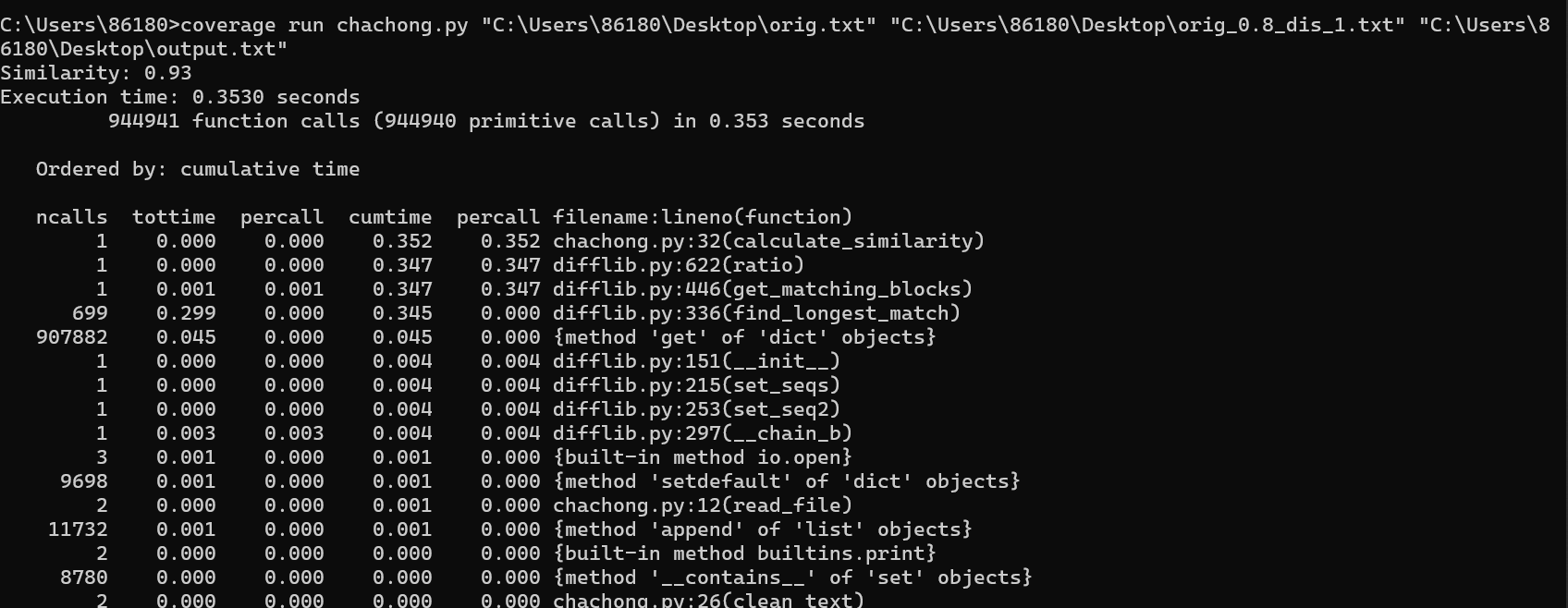
代码覆盖率:
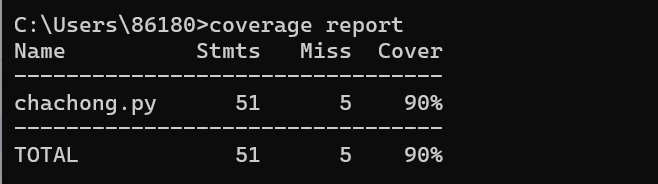
代码覆盖率依旧为90%
测试一个空文本:
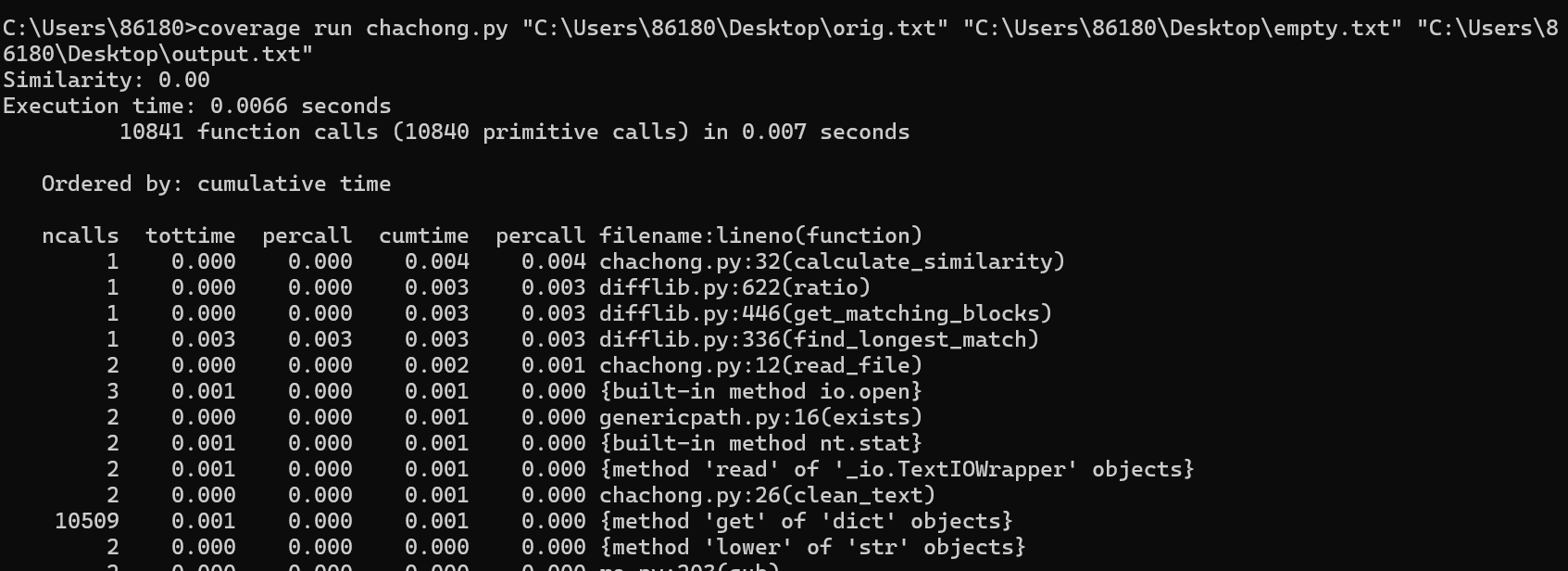
此时查重率为0%,结果正确
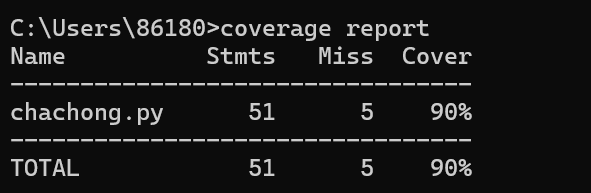
代码覆盖率依旧为90%
异常处理
代码:
def read_file(file_path):
if not os.path.exists(file_path):
print(f"File not found: {file_path}")
sys.exit(1)
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text
except Exception as e:
print(f"Error reading file: {str(e)}")
sys.exit(1)
该部分代码主要用于处理文件路径不正确的异常情况
测试一个不存在的文本文件:

显示文件未找到,代码覆盖率为65%

