
Python标准库---random模块的使用
更新时间:2019.09.12(更新目录)
1. 谈谈随机数:
我们经常会用到随机数,对它也并不陌生。但是谈到如何使用计算机来生成随机数的时候,我们便会发现,无论是多么先进的计算机都难以实现真正意义上完全随机的数。实际上,我们使用计算机生成的都是伪随机数。虽说是“伪”随机数,但也不能说它是假的随机数,而是应该归为有一定规律的随机数 。
。
那为什么说这些计算机生成的数是“有规律”的呢 ?主要是这些随机数都是通过随机数种子来迭代计算生成的,通常来说这些随机数种子来自于当前系统的时间戳或者操作系统中的随机源。并且由于每台计算机的硬件层面都有所不同,所以用不同计算机生成的随机数基本都是不同的(系统时间是通过计算机主板的定时计数器来计算的)。
?主要是这些随机数都是通过随机数种子来迭代计算生成的,通常来说这些随机数种子来自于当前系统的时间戳或者操作系统中的随机源。并且由于每台计算机的硬件层面都有所不同,所以用不同计算机生成的随机数基本都是不同的(系统时间是通过计算机主板的定时计数器来计算的)。
如果我们固定随机数种子后,每次在同一台计算机得到的随机数都是一样的。而对于默认由系统时间戳得到的随机数种子,在短时间内生成大量随机数时也会出现不少重复。因此,如果我们想生成接近于真正意义上的随机上,就需要对随机数种子设置更多的参考指标。
2. Random模块---用于生成各种分布的伪随机数
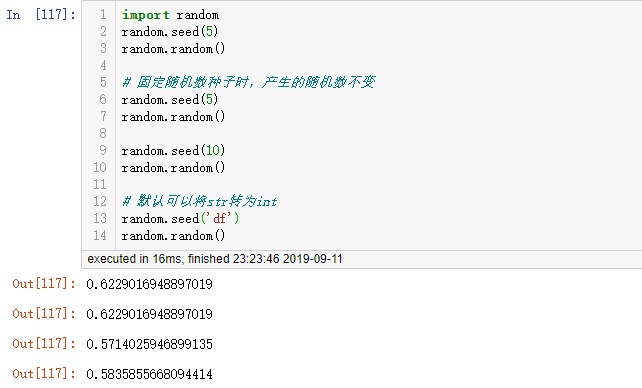
2.1 random.seed(a=None, version=2):
- 作用:设置随机数种子,
- 参数:第一个如果不指定就默认是当前的系统时间戳或者操作系统中提供的随机源,第二个参数是指所使用的种子版本(version),默认是版本2,可以将str、byte、bytearay等对象转为int并使用所有位。而版本1(旧)是用于str和byte生成更窄的种子范围。
- 例子:
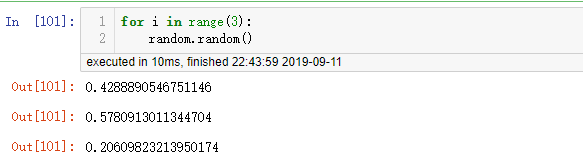
2.2 random.random():
- 作用:获取区间[0, 1)的一个浮点随机数
- 参数:不需要参数
- 例子:
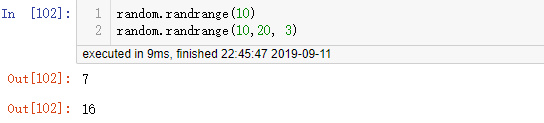
2.3 random.randrange(start, stop[, step]):(其实就好像range一样 )
)
- 作用:在指定的范围里,随机抽取一个整数
- 参数:接收的都是整数,第一个是start,第二个是stop,第三个是步长step(可选)
- 例:
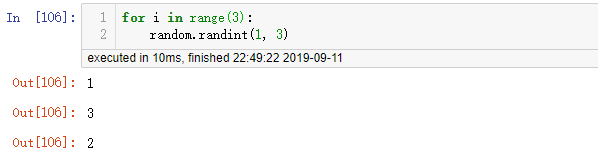
2.4 random.randint(a, b):
- 作用:从[a, b]中生成一个随机整数,等价于random.randrange(a, b+1)
- 参数:a表示起始范围,b表示终止范围
- 例:
2.5 random.uniform(a, b):
- 作用:获取区间[a, b)或者[a, b]的一个浮点随机数
- 参数:如果a > b, 则获取的随机数是b<=N<=a,如果a < b, 则获取的随机数是a<=N<=b
- tip:由于它是根据a+(b-a)*random.random(),并对结果进行舍入,所以可能包含边界b也可能不包含b
- 例:

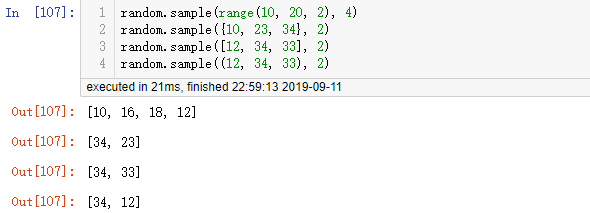
2.6 random.sample(seq, k):
- 作用:用于样本抽样
- 参数:第一个是序列或者集合(像当总体较大时指定range()作为参数,即快又节省内存),第二个是用于指定选取几个样本,最后返回样本列表
- tip1:从总体序列或者集合中不放回地选取n个样本,其中样本数不能大于总体序列的长度
- tip2:如果序列中有包含重复的元素,这些元素都有机会入样
- 例:
2.7 random.choice(seq):
- 作用:从一个非空的序列中随机选择一个元素
- 参数:非空序列
- 例:

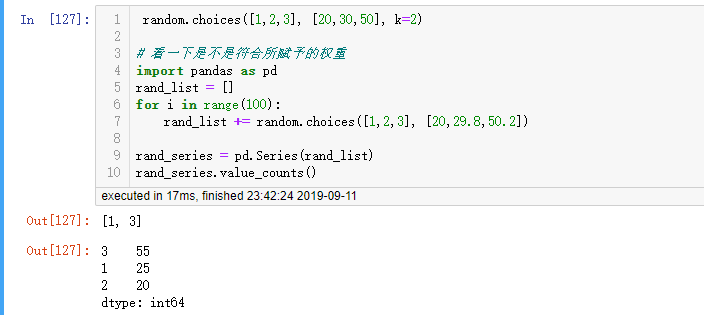
2.8 random.choices(seq, weights=None, *, cum_weights=None, k=1):
- 作用:可以对序列的元素给定权重(权重的个数要和序列的长度相同),并且选取多个元素,不给定时默认各个元素的权重是相等的
- 参数:第一个序列,第二三个是权重(可选),第四个是选择个数,最后返回的是一个列表
- tip1:权重的形式可以是相对权重weights(像[10,30,40,20])或者累计权重cum_weights(像[10, 40, 80, 100])。但实际上在执行时,相对权重会转化为累计权重,因此直接使用累计权重可以节省工作量
- tip2:权重可以指定任何的数字形式(整数、浮点数、分数等)
- 例:
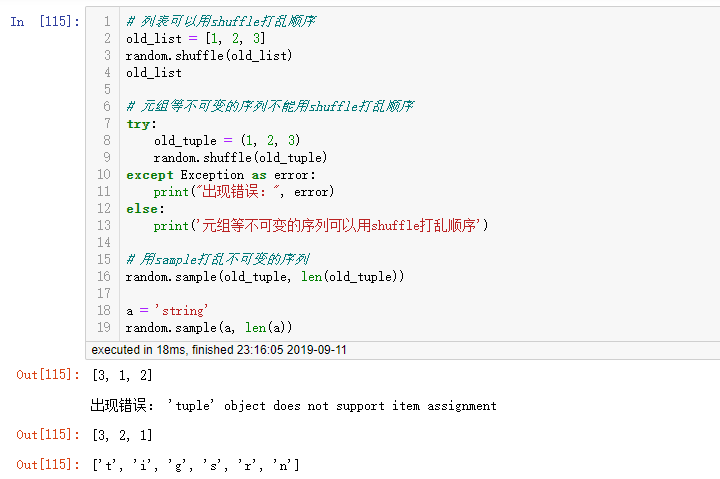
2.9 random.shuffle(seq):
- 作用:将可变序列元素的位置打乱
- 参数:要打乱位置的序列
- tip:如果想将不可变序列(像元组、字符串等)的元素位置打乱,可以使用random.sample(x, len(x))
- 例:
3. 其他补充资料:
实际上有许多中方法来计算随机数,像Python就是用梅森旋转法来计算的。
- 传送门:Python随机数的产生算法


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 本地部署DeepSeek后,没有好看的交互界面怎么行!
· DeepSeek 解答了困扰我五年的技术问题。时代确实变了!
· 趁着过年的时候手搓了一个低代码框架
· 推荐一个DeepSeek 大模型的免费 API 项目!兼容OpenAI接口!