
《[MySQL技术内幕:SQL编程》读书笔记
《[MySQL技术内幕:SQL编程》读书笔记
2019年3月31日23:12:11
严禁转载!!!
<MySQL技术内幕:SQL编程>这本书是我比较喜欢的一位国内作者姜承尧, 早年在学mysql时就听过姜老师的开源mysql网络视频教程, 记得在视频时总是姜老师姜老师的自称, 感到十分的亲切.
这本书主要是讲mysql在应用编程时如何正确并且更高效的根据业务场景编写相应的sql语句.
从一开始对mysql的历史, 数据库类型, 分支版本, 咋一看, 还挺熟悉的, 这个逻辑顺序不就是当时视频讲课的顺序. 在本章末尾, 还推荐了几款主流的图形化SQL查询分析器.
第二章主要是介绍了各种常用的数据类型. 包括UNSIGNED和ZEROFILL要注意的事情, 对于UNSIGNED, 如果没有设置sql_mode=no_unsigned_subtraction, 连个UNSIGNED
数据(小减大)的结果不是正确的负数. ZEROFILL主要是填充占位用的, 在显示的时候会在左边填充0, 实际显示还是实际大小, 只是显示不一样. 然后就是常用的时间日期数据类型了. 这里主要的问题是闰年, 星期, 跨年, 国际化这种需要注意的. datetime 不能有默认值, timestamp可以有默认值. mysql5.6前now, datetime等会截断微秒, 5.6后可以保留微秒(microsecond()函数). 再到字符类型, 字符类型主要是有固定长和变长两种, 变长的再表记录中在额外的头有这个可变数据的长度......当然比价orange人头疼的字符集和比较规则, 这里介绍的还是很清晰的.
第三章是查询处理.查询处理包括了逻辑查询和物理查询. 逻辑查询操作顺序用一图介绍. 然后就是根据操作顺序来对每一个操作展开讲解. 主要是联合, 过滤, 排序, 分组等操作. 我们要有集合的思维来看待关系型数据库.以上操作步骤是逻辑查询的, 真正的查询还要经过物理查询, 经过server层的分析器和优化器,真正构造一条执行查询语句.
第四章是子查询。子查询分为独立子查询和相关子查询。独立子查询与外部查询是不相关的, 但是要明确显式定义, 如果没有显示定义子查询的列, 那么就会被mysl的优化器把子查询优化成相关子查询,相关子查询的查找速度与外部查询的匹配次数有关。因此往往就会造成查询慢的原因。这章分析和提出一些办法来如何减少子查询和外部查询的匹配次数,提高效率。第一、增加一个索引提高查询速度。第二、通过派生表来减少子查询与外部查询的匹配次数。接着介绍了EXISTS谓词和其与IN的区别,后面就是介绍派生表了。派生表用好不容易,需要经验丰富。所以平时尽量避免子查询。最后介绍了MariaDB对SEMI JSON的优化。
第五章是联接与集合操作。联接有多种联合方式,针对不同的业务选择不同的联接方式,CROSS JOIN, INNER JOIN,OUTER JOIN,NATURAL JOIN, STRAIGHT JOIN,SELF JOIN
,NONEQUI JOIN,SEMI JOIN。然后介绍不同的联接算法,包括Simple Nested-Loops Join算法,Block Nested-Loops Join算法,Block Nested-Loops Join算法
,Block Nested-Loops Join算法,Classic Hash Join算法。最后又介绍了集合操作,mysql标准只有UNION DISTINCT和UNION ALL两种,但是可以在这个基础上扩展为EXCEPT和INTERSECT。
第六章是聚合和旋转操作。mysql为我们提供了一些聚合函数,并且有多种聚合,附加聚合,连续聚合等操作,通过聚合可以减少子查询的使用。然后还介绍了开放架构设计的表可以旋转,行-->列,列-->行。这种主要是用于报表输出,直观阅读。最后介绍了CUBE和ROLLUP,主要是配合GROUP BY使用,分组聚合,提高效率。
第七章是游标。从面向过程和面向集合的两个角度来展开讲解,同时给出了游标操作的步骤。但是要慎用游标,不是不用,而是在必须的场合下才使用。游标对于扫描一次表的情况是劣势的,但是如果对于一些面向集合的解决方案所需扫描成本为O(N^2)的情况,使用游标的解决方案只需O(N)。
第八章是事务编程。了解了什么事事务,事务是原子单位,要么都成功,要么都失败回滚。一般事务需要满足ACID。然后介绍了四种隔离级别,隔离级别是存储引擎层面的。InnoDB默认是REPEATABLE READ级别(可重复读),但是有了Next-Key Lock(间隙锁),可像串行化读那样。事务完全安全。接着介绍了事务有关的控制语句和隐式提交的语句。mysql的分布式事务需要XA事务的支持,异构数据库组成分布式事务需要InnoDB的隔离级别是SERIALIZABLE隔离级别。然后引出几个不好的事务编程。这一章节,分析了事务的概念和如何应用事务。
第九章是索引。索引是数据库查询的精华。正是因为有了索引,才能使查询变得更高效,使数据库应用更广泛。这章从数据结构树开始说起,到mysql底层数据结构B+树,到B+树索引的底层实现都分析了,后面还介绍了一下其他的索引实现,T树索引,哈希索引等。总的来说,这章是从底层来分析的,获益良多。
第十章是分区。谨慎选择是否要分区,因为分区并不一定能带来效率的提升的。分区是在索引的基础上对表进行水平分区。这章中介绍了RANGE、LIST、HASH、KEY、 COLUMNS五种主要的分区。
2.数据类型
-
2.1 尽量不要使用unsigned, 在没有设置 sql_model='no_unsigned_subtraction'选项时, 两个unsigned变量相减等操作会出现结果错误
-
2.2 zerofill 整型填充, 不足定义的字节数, 会在前面填充0, 实际显示还是实际大小, 只是显示不一样.
-
2.3 set_model 主要是用来控制mysql的严格度
-
2.4 datetime 不能有默认值, timestamp可以有默认值
-
2.5 mysql5.6前now, datetime等会截断微秒, 5.6后可以保留微秒(microsecond()函数)
-
2.6 now(), datetime(), sleep(), current_timestamp(), sysdate() sysdate返回的是当前函数执行时的时间, now是执行SQL语句的时间
-
2.7 使用date_format() 不会走索引. do not !!! do not!!! do not!!!
3.查询处理
-
3.1 查询流程中, 每个操作都产生一个虚拟表, 除了最后一个,其他对用户都是透明的.
-
3.2查询流程
![]()

4.子查询
-
4.1 子查询必须包含括号
-
4.2 IN /// ANY/SOME /// ALL /// NOT IN/<>ALL
-
4.3 独立子查询是不依赖外部查询而运行的子查询。易于调试。
-
4.4 mysql优化器会对 IN 子句优化, 如果 IN 不是显式的列表定义, IN 子句会被优化成EXITS的相关子查询. (解决办法: 一般是增加多一层子查询, 减少外部查询和子查询的匹配次数)
-
4.5 相关子查询: 引用了外部查询列的子查询, 即子查询对外部查询的每一行进行计算.
-
4.6 对相关子查询的处理, 减少子查询与外部查询的匹配次数
错误:

正确:

然而查询速度很慢:
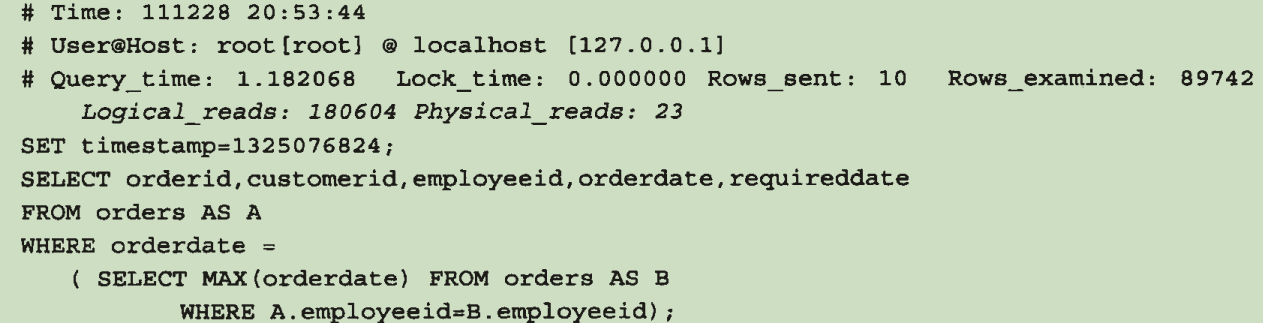
优化: 增加一个索引提高查询速度:

优化: 通过派生表来减少子查询与外部查询的匹配次数:

子查询优化:
-
索引
-
派生表
-
使用连接(JOIN)来代替子查询
-
4.7 EXISTS谓词
-
4.7 EXISTS 的输入一般是子查询, 并关联到外部查询, 但不是必须的. 根据子查询返回行, 该谓词返回true或false, 不会返回unknown.
![]()
-
4.8 EXISTS 和 IN 的执行计划是一样的, 但是 NOT EXISTS 和 NOT IN的执行计划是不一样的, 因为有UNKNOWN的存在. NOT EXISTS返回TRUE和FALSE, NOT IN返回FALSE和UNKNOWN.
-
4.9 派生表是完全的x虚拟表, 并没有也不可能被物理化地具体化

5.连接与集合操作
5.1 由于历史原因,出现了新旧查询方法:
- select * from a, b where a.x = b.x;
- select * from a inner join b on a.x = b.x;
5.2 JOIN方式
CROSS JOININNER JOINOUTER JOINNATURAL JOINSTRAIGHT JOINSELF JOINNONEQUI JOINSEMI JOIN
逻辑查询的三个步骤:
- 产生笛卡尔积的虚拟表
- 按照ON过滤条件进行数据的匹配操作
- 添加外部行
CROSS JOIN:全表连接,做笛卡尔积, m * n。用于快速生成重读测试数据,作为返回结果集的行号。
INNER JOIN:不会添加外部行。过滤条件在WHERE或ON是一样的,最好是表之间的过滤是在ON,一个表的过滤在WHERE。后面不跟ON,等同于CROSS JOIN。可以使用USING( )来指定根据相同名称列来匹配。
OUTER JOIN:通过OUTER JOIN添加的保留表中存在未找到的匹配数据,对未找到并添加的外部行会用NULL填充。必须配有ON子句。可以使用USING( )来指定根据相同名称列来匹配。
- LEFT OUTER JOIN:以左表为基准,右表去匹配。
- RIGHT OUTER JOIN:以右表为基准,左表去匹配。
NATURAL JOIN:等同于INNER JOIN 和USING的组合。将两个表相同名称列进行匹配。
STRAIGHT JOIN:强制险读左表。一般是有经验的DBA用来设定最优路径。
SELF JOIN:同一个表不同实例之间的JOIN操作。读同一个表进行连接必须先指定表别名。主要是解决层次结构问题。
NONEQUI JOIN:包含“等于”运算符之外的运算符。
SEMI JOIN:根据一个表存在的记录去找另外一个表的相关记录。
5.3 多表联接
INNER JOIN多表查询。可以用ON()把过滤条件都放在一起。OUTER JOIN 多表的联接顺序对结果有影响。
5.4 联接算法的历史
- MySql 5.5版本仅支持Nested-Loops Join算法
- MySql 5.6开始支持Batched Key Access Joins算法(简称BKA)
5.5 Nested-Loops Join算法
当联接的表上有索引,是非常高效,根据B+树的特性,时间复杂度是O(N),但是如果没有索引,会被视为最坏情况,时间复杂度是O(N^2)。
5.5 Nested-Loops Join算法的分类:
- Simple Nested-Loops Join算法
- Block Nested-Loops Join算法
5.6 Simple Nested-Loops Join算法:从一张表中每次读取一条记录,然后将记录与嵌套表中的记录进行比较。
For each row r in R do
lookup r in S index
If find s == r
Then output the tuple <r, s>
联接两个表都有索引,并且索引高度相同,优化器会选择将记录数最少的表作为外部表,因为内部表示索引扫描,只和索引的高度有关,与记录数量无关。
5.7 Block Nested-Loops Join算法
针对没有索引联接的情况,使用join buffer(联接缓冲)来减少内部循环减少读表的次数。实质是预先一次性读取比如10条记录到内存,减少读取次数来提高效率。
5.8 Block Nested-Loops Join算法
结合索引和group(额外join buffer)。后者可以提交cache命中率。
Classic Hash Join算法
mysql暂时不支持,MariaDb支持。
5.9 集合操作
- UNION DISTINCT
- 创建一张临时表,即虚拟表
- 对这张临时表的列添加唯一索引
- 将输入的数据插入临时表
- 返回临时表
- UNION ALL
5.10 集合操作注意
OUTFILE只能存在于最后一个select语句中,并且虽然在最后面,但是导出的事所有的结果。
UNION DISTINCT
由于有唯一索引,对性能还是影响的,所以在确定没有重复数据时,最好是用UNION ALL。
EXCEPT
找出位于第一个输入中但不位于第二个输入中的行数据。
INTERSECT
返回在两个输入中都出现的行。
6.聚合和旋转操作
-
6.1 mysql只支持流聚合。
- 流聚合依赖于获得的存储在GROUP BY列中的数据,如果SQL查询中包含的GROUP BY语句多于一行,流聚合会先根据GROUP BY对行进行排列。
-
6.2 开放架构是一种用于频繁更改架构的设计模式。对于利用开放架构设计的表,一般使用Pivoting技术来查询。
-
6.3 已知属性个数,可以用静态Pivoting。
-
6.4 Pivoting还可以用来做格式化聚合函数,一般用于报表输出,直观。
![]()
-
6.5 Unpivoting,Pivoting的反向操作。把行转为列。
-
6.6 mysql仅支持CUKE,不支持ROLLUP。ROLLUP是根据维度在数据结果集中进行的聚合操作。ROLLUP的优点是一次可以取得N次GROUP BY的结果,提高查询效率。单个维度没啥优势,第一个维度优势就大了。
-
6.7 ROLLUP不能喝ORDER BY一起使用,用LIMIT的话阅读性差,没有实际意义。
-
6.8 CUBE只在层次上对数据聚合,对所有维度进行聚合,具有N维度的列,需要2^N次分组操作。

7游标
-
7.1 游标不是恶魔,存在即合理。合理利用才是硬道理。
-
7.2 游标可以在存储过程,函数,触发器和事件中使用。
-
7.3 游标三个属性:
- Asensitive:数据库也可以不复制数据集
- Read Only:不可更新
- NonScrollable:游标只能向一个方向移动,不能跳过任何行。
-
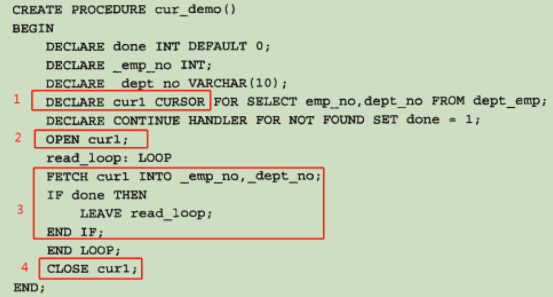
7.4 游标的使用步骤:
- 定义游标
- 打开定义游标的变量
- 从游标取得数据
- 关闭游标
![]()
-
7.5从游标放入数据到变量时,变量的名字不能和列的名字一样,不然会变成NULL。
8.事务编程
-
8.1 事务概述。事务应该满足ACID。(原子性,一致性,隔离性,持久性)
- 原子性:每条语句,或者一个事务,当做一个整体,要么成功,要么失败回滚。事务是一个不可分割的单位。
- 一致性:事务将数据库从一个状态转变为另外一种一致的状态,数据库的完整性约束不会被改变。
- 隔离性:别称并发控制,可串行化,锁。保证事务提交前其他事务看不见。
- 持久性:凡是提交了的事务,都应该持久化到磁盘上,即使数据库崩溃,也能通过日志来恢复。
-
8.2 事务的分类
- 扁平事务
- 带保存点的扁平事务
- 链事务
- 嵌套事务
- 分布式事务
扁平事务

- 优点:使用简单,广泛使用。
- 缺点:不能提交事务的一部分,或分步骤提交。
带保存点的扁平事务
定义:除了支持扁平事务外,允许在是事务执行过程中回滚到同一事务中较早的一个状态。保存点同来通知系统记住事务当前的状态,以便以后发生错误,事务能回到该状态。
- 优点:能够灵活的回滚到某个状态,避免回滚到最初状态的消耗。
链事务
多个事务连续操作时,由于保存点是非持久的。带保存点的扁平事务,在系统崩溃时,需要重头开始执行到保存点,而不是从最近的一个保存点开始。

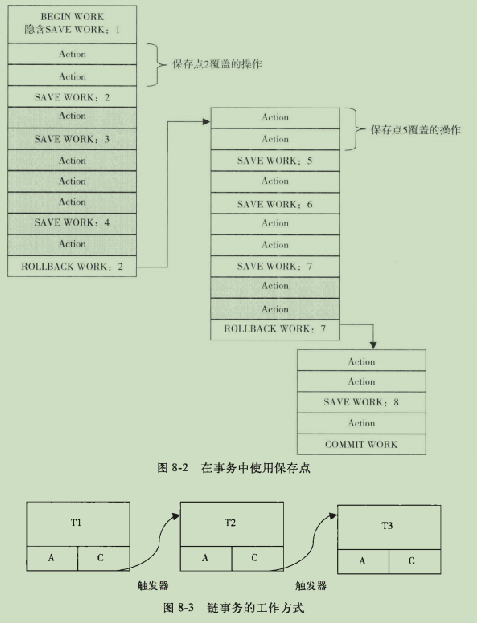
- 优点:多个事务时,保存点更灵活
- 缺点:事务仅能回滚到当前事务的最近保存点。
嵌套事务
不是mysql原生的,可以通过带保存点的扁平事务来模拟。但是要注意各个事务锁的问题。
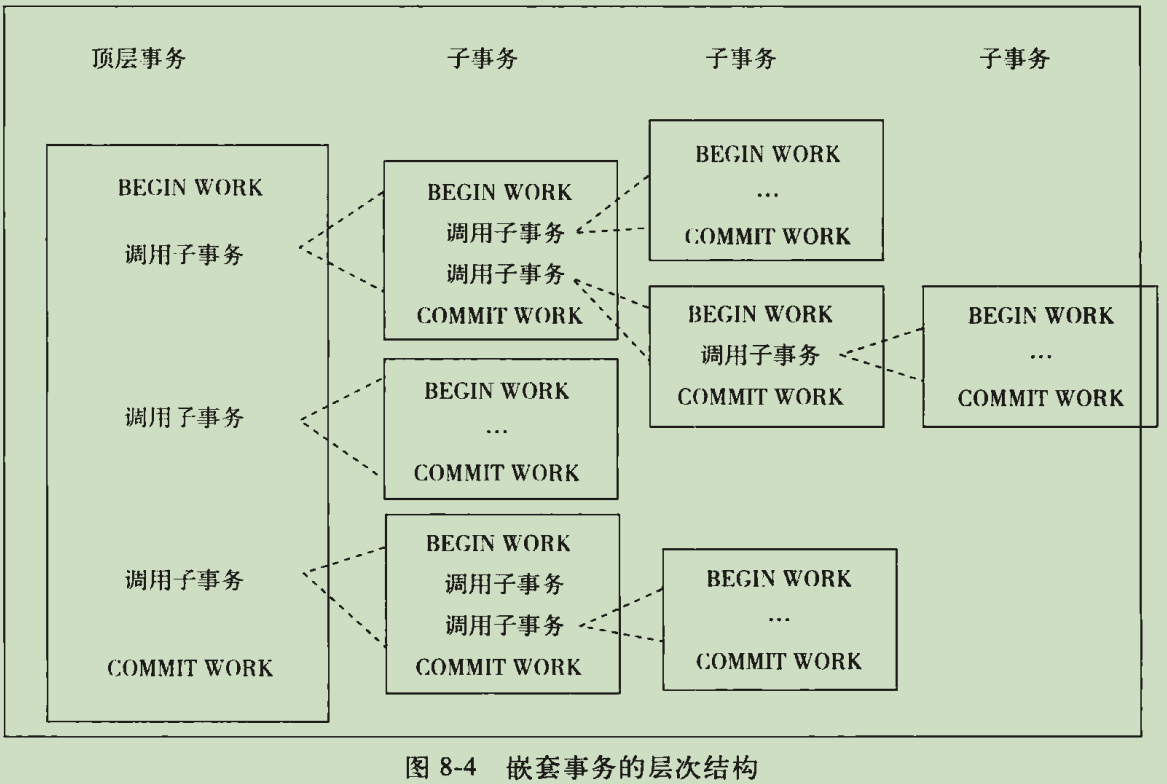

所有工作由叶子点来完成,只有叶子点具有访问数据,发送消息,获取其他类型的资源。父节点或顶点节点只是起到逻辑控制,何时调用子事务的事情。
分布式事务
在分布式环境下运行的扁平事务。
8.3 事务控制语句
- START TRANSATION / BEGIN
- COMMIT
- ROLLBACK
- SAVEPOINT xxx
- RELEASE SAVEPOINT xxx
- ROLLBACK TO [SAVEPOINT] xxx
- SET TRANSATION (READ UNCOMMITTED / READ COMMITTED / REPEATABLE READ / SERIALIZABLE)
在命令行下开启事务可以:
BEGIN
。。。
END
或者
START TRANSATION
。。。
COMMIT
但是在存储过程中,mysql数据库的分析器会自动的把BEGIN识别为BEGIN...END,所以在存储过程中只能使用START TRANSATION
- 8.4 隐式提交的SQL语句
执行以下语句自动回提交事务

- 8.5 事务的隔离级别
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
InnoDB存储引擎支持的隔离级别是REPEATABLE READ,使用Next-Key Lock的锁算法,避免了幻读的产生。在这个级别下已经可以完全保证事务的安全性。达到SERIALIZABLE的隔离级别,但是性能比其好。
隔离级别越低,事务请求的锁越少或保持锁的时间约短。
在READ COMMITTED事务隔离级别下,除了唯一性约束检查及外键约束的检查需要Gap lock,InnoDB存储引擎不会使用Gap Lock锁算法。(注意,mysql5.1以前,这个隔离级别只能工作在Replication(复制)的二进制日志为Row格式下。mysql5.1后不会了,也可以工作在STATEMENT格式下。)
最好建议是选择Row格式的二进制日志。因为记录的是行的变更,而不是SQL语句。避免出现不同步的现象
- 8.6 分布式事务编程
分布式事务:允许多个独立的事务资源参与到一个全局的事务中。全局事务中的事务要么全都成功,要么都回滚。在使用分布式事务时,InnoDB的隔离级别必须是SERIALIZABLE的。
InnoDB支持XA事务,并通过XA事务来支持分布式事务。异构分布式数据库可以通过XA事务实现分布式事务。
XA事务:
-
一个或多个资源管理器(提供访问事务资源的方法)
-
一个事务管理器(协调参与全局事务中的各个事务)
-
一个应用程序(定义事务的边界,指定全局事务中的操作)
![]()
-
8.7 不好的事务编程习惯
-
不要在循环中提交。无论是显式提交还是隐式提交。
![]()
-
不要自动提交。因为不同语言的API的自动提交设置是不一样的,容易出错。
-
不要使用自动回滚。最好是在程序中控制事务。
-
-
8.8 长事务

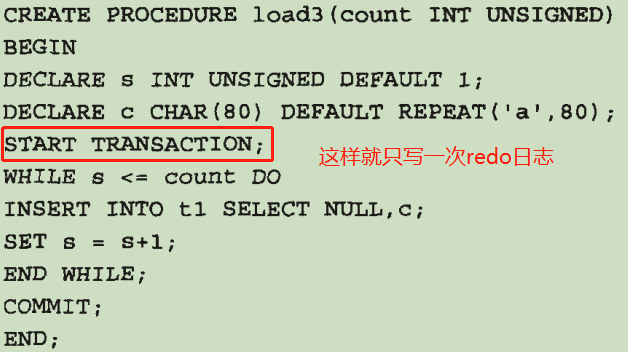
长事务最好分为批量小事务。因为长事务如果失败,回滚的代价太大了。
9.索引
- 9.1 缓冲池、顺序读取与随机读取
数据库一般需要持久化,持久化就要和磁盘打交道,因此就会出现访问磁盘的操作。随机访问磁盘是比较慢的,顺序访问会快很多。所以现在基本都有缓冲池的存在。缓冲池作为内存和磁盘的中间件,主要是缓存以页的方式缓存数据页,查询和修改时会先在缓存查看有没有,有就命中,效率就很高了。或者没有的话,先把数据页调出到缓存池中,再修改数据页,然后异步写入磁盘持久化。
- 9.2 数据结构与算法
二分查找算法:

树数据结构是mysql底层数据结构
- 9.3 B+树
B+树的演变由来:二叉搜索树--->平衡二叉树--->B+树

对mysql的B+数的插入和删除操作会引起分裂和合并的产生,主要是为了维护B+索引树的平衡,不过有些时候可以通过左旋右旋来避免分裂合并。


- 9.4 B+树索引
索引是存储引擎层面实现的,所以不同的存储引擎底层的数据结构可能是不一样的。
由于B+索引树的高扇出,所以查找速度是很快的。
B+树索引分为:聚集索引和辅助索引。区别在与存放的数据内容。
聚集索引:根据主键创建的B+树,聚集索引的叶子存放的是表中的真实数据。非叶子节点存放的是目录项数据(页号等)。
辅助索引:根据索引创建的B+树。叶子节点只存放索引键值和其指向的主键。根据辅助索引查找时需要回表操作。可以存放更多键值,高度一般小于聚集索引。

- 9.5 Cardinality
什么时候需要添加B+树索引,一般经验是在访问表很少部分行时使用才有意义。高选择性的字段才有意义。
通过show index; 查看Cardinality列的值来判断是否要加对这一列加索引。
Cardinality的统计是在存储引擎层实现的。因为每个存储引擎对B+树的实现是不同的。
Cardinality的统计一般是通过采样完成的。因为Cardinality的统计放生在insert和update操作,然而这两个操作是很频繁的,所以不会实时的更新的。

InnoDB存储引擎每次随机选择8个叶节点进行采样。所以每次查看Cardinality值可能是不相同的。采样过程:

- 9.6 B+树索引的使用
别盲目听从,研究业务确定是否需要索引,对哪些列做索引。
联合索引的键数量是多个,不是一个。
联合索引省掉第二个键的排列,所以有时候可以提高查询效率。
覆盖索引:从辅助索引就可以等到查询的记录,而不需要回表操作。大量减少了IO操作。
一般来说,对于诸如(a,b)这类联合索引,一般不可以选择b列来进行查询,但是在统计操作,如果是覆盖索引,优化器会优先选择。
发生隐式转换时,索引失效。
范围查找或JOIN操作,有时会不走索引,而是通过扫描聚集索引,也就是全表扫描。原因:
- 选取的是整行信息,而覆盖索引是没有包含全部数据信息的,所以只能走全表扫描了。
你够自信可以使用 FORCE INDEX 啊。
mysql支持INDEX HINT(显式告诉优化选择指定索引)。两种情况需要:

-
USING INDEX 只是告诉优化器选择指定的索引,优化器不一定真的会选择。
-
FORCE INDEX 是强制优化器选择指定的索引。
-
9.7 Multi-Range Read
mysql5.6后才有的。
MMR优化的目的是减少磁盘的随机访问,并且将随机访问转化为顺序访问。

反正开了MMR之后,对效率的提高是吊吊的。
- 9.8 Index Condition PushDown
mysql5.6后才有的。
ICP是一种根据索引来查询的优化方式

反正开了ICP之后,对效率的提高是吊吊的。
- 9.9 T树索引
从mysql5.1开始 NDB Cluster开始使用T树。
T树不将真实数据放在节点,只是存放数据的指针。
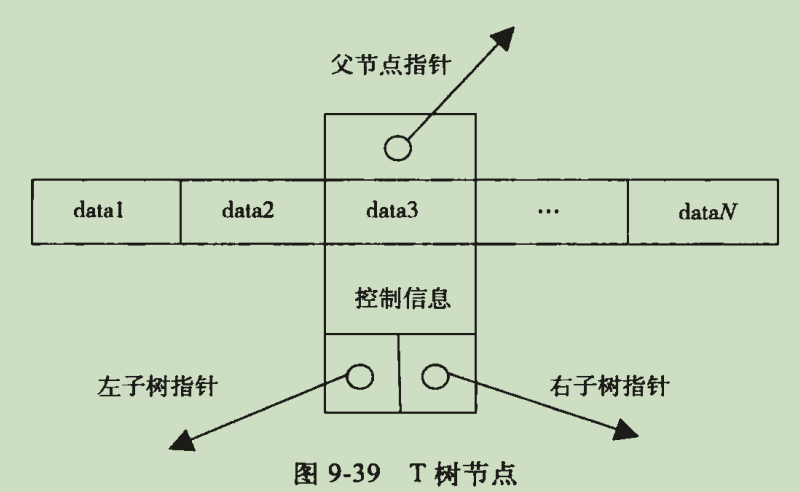
T树结构:

T树边界定义:
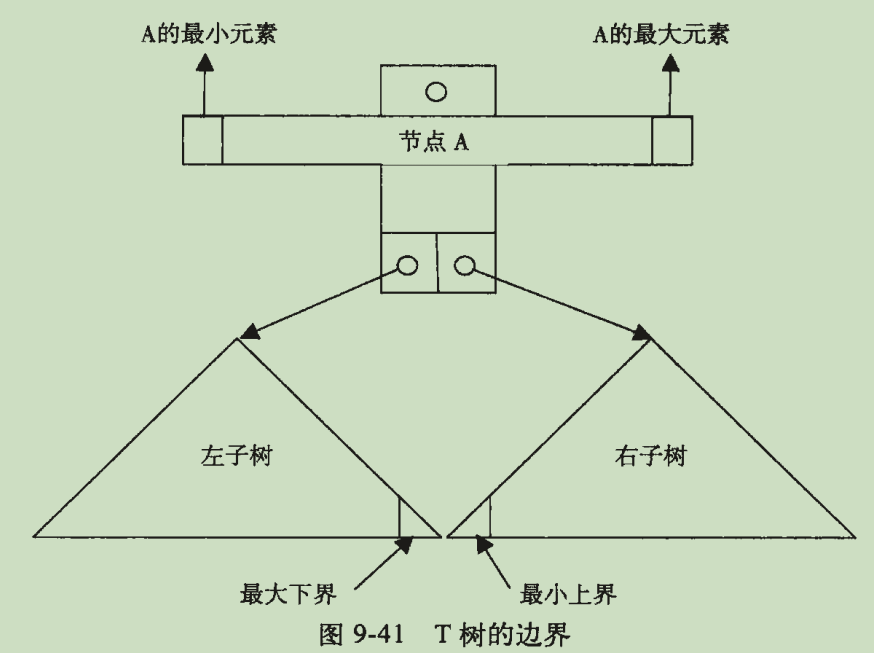
查找算法:

插入算法:

删除算法:

- 9.10 哈希索引
InnoDB存储引擎只支持自适应哈希索引(不可以人工干预,对字典类型的查找速度超快),而Memory存储引擎支持哈希索引。
哈希函数是关键。
发生碰撞,解决办法:
- 链接法
- 开放式向前探索法(1步跳,迭代n步跳)
查看自适应哈希索引的情况:
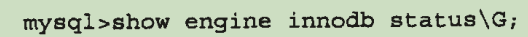
哈希索引只能是等值查询。因为哈希函数映射后就是一个值,就是通过比较值来得到对应的槽。
10.分区
- 10.1 分区概述
分区是表的一种设计模式。正确的分区可以极大提高数据库的查询效率。
分区不是在存储引擎层面实现的,所以并不是Innodb独有的。mysql仅支持水平分区(将同一表中的不同行的记录分配到不同的物理文件中),并且是局部分区索引,一个区中既存放数据又存放索引。
mysql支持一下的分区方法:
- RANGE分区 (指定一个连续范围)
- LIST分区(指定一个离散范围)
- HASH分区(通过自定义函数的返回值来进行分区,返回值不能是负值)
- KEY分区(根据mysql提供的离散函数进行分区)
如果表中存在主键或唯一索引,分区列必须是唯一索引的一部分。
- 10.2 分区类型
RANGE分区

LIST分区

在INSERT多行数据时, 如果有一行数据插入失败,MyISAM存储引擎会将之前的行数据都插入,但之后的数据不会被插入。但是InnoDB会把全部行插入当做事务,有一条失败就会全部失败,前面插入的行数据会回滚。
HASH分区

KEY分区

- 10.3 子分区
子分区是在分区的基础上再分区。

- 10.4 子分区中的NULL值
mysql数据库允许对NULL值分区,但是会把NULL值视为小于任何一个非NULL值。
对RANGE分区

对LIST分区

对HASH分区和KEY分区

- 10.5 分区和性能
分区并不是一定能带来性能的提高。要合理分区。有时候有主键和索引就可以很快查询到所需数据,不是一定更分区,减少查询的数据量才是更快的。因为索引的搜索是B+树啊。

- 10.6 在表和区间交换数据
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号