数据库并发控制原理
1.Transaction
数据库事务以Begin()开始,以Commit()或Abort()结束。事务需要满足ACID属性。
1.1 ACID
Atomicity
-
A:Atomicity 原子性,即多个操作合并在一起,如一个原子一样不可分割。
可通过一下方法实现:
-
Logging :记录一个事务里面的所有请求到 log 中,当 abort 时,可以根据 log 日志撤销操作。每一次在 Log 中新增操作时需同时持久化到硬盘中。
-
Shadow Paging:修改数据时,拷贝一份该数据的page,在其上面修改。当事务commit之后,该page才对其他事务可见。
-
-
C:Consistency,一致性,这个和分布式系统的里面的一致性含义并不相同。CAP 中的一致性更多指的是数个副本的一致。ACID 中的一致性指的是数据库处于应用程序所期待的状态。比如银行从 A 账户转一部分钱到 B 账户,肯定是希望 A+B 账户的总金额在任何时刻都是一样的。
-
I:Isolation,独立性,即不同的事务之间不会互相干扰,互相独立。
数据库通过 concurrency control(并发控制)来保证不同事务之间的独立性,互不干扰。并发控制分为乐观模型和悲观模型。
- Optimistic:假设事物的冲突是很少发生的,只有当事务 commit 的时候,才会检查是否存在冲突,确实是否需要 abort。适合多读少写的场景。通常基于 MVCC,timestamp 的并发控制是乐观模型。
- Pessimistic:假设冲突是经常发生,在一个事务开启的时候,就先检查是否存在冲突。适合少读多写的场景。通常基于锁的的并发控制是悲观模型。
-
D:Durability,就是持久化。同样可以通过 logging 或 shadow page 来实现。
1.2 Schedule
schedule即对于多个事务如何安排执行策略的问题。
- Serial Schedule
指的是多个不同事务按顺序执行。如下图先执行 T1 后再执行 $T2$,或先执行 T2 再执行 T1,两个 txn 不会穿插在一起。
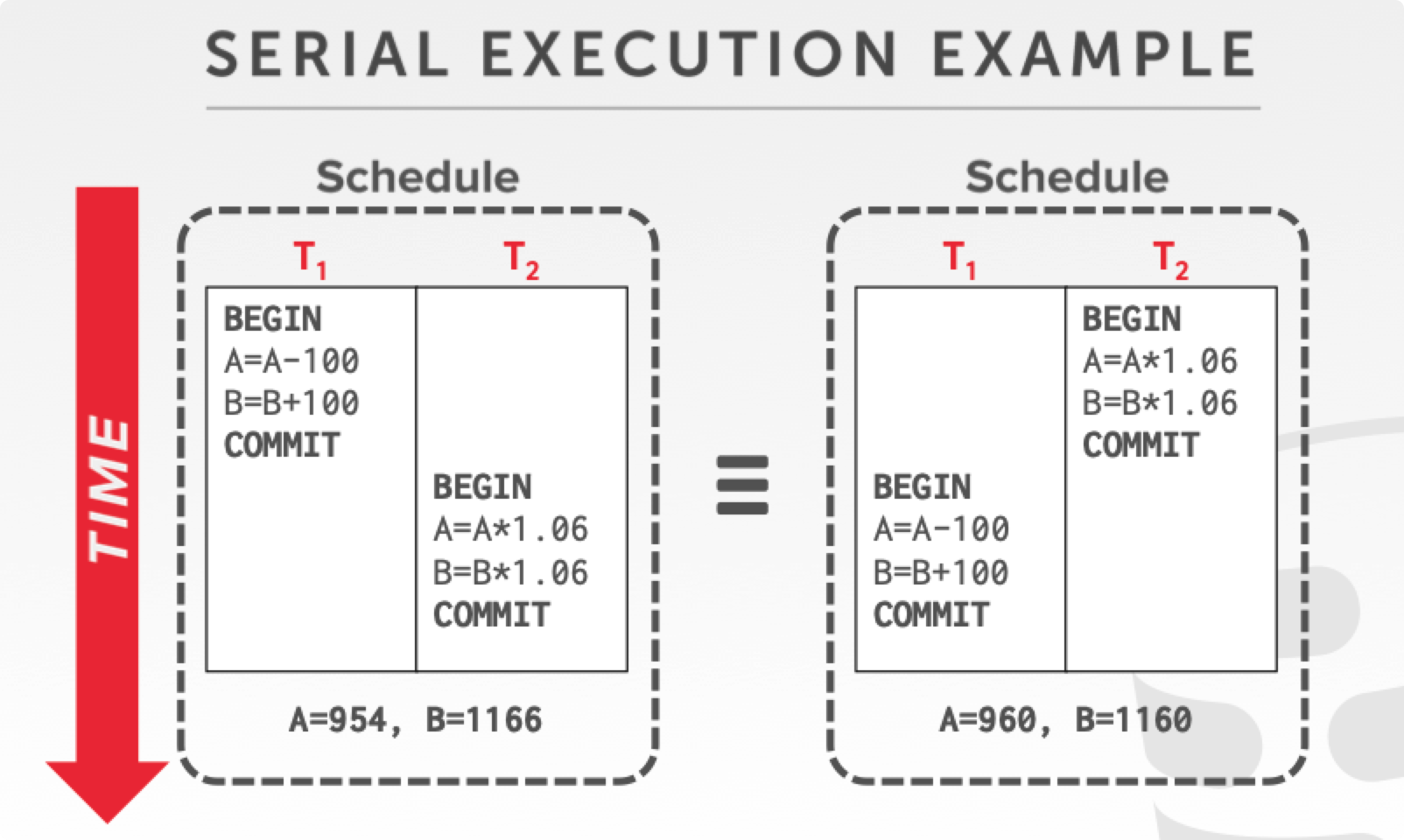
如果数据库种所有的 schedule 都是 serial schedule,这样性能很差,相当于数据库是单线程执行的(不过 Redis 好像就是单线程)。数据库并发控制存在的意义就是让并发执行的 schedule 的结果和你 serial schedule 执行的结果一样。
- Equivalent Schedule
在任何数据库状态下,如果两个 schedule 执行后均能得到相同的结果,那么称这两个 schedule 为 equivalent schedule。
- Serializable Schedule
如果一个 schedule 和一个 serial schedule 互为 equivalent schedule,那么称该 schedule 为 serializable schedule。
- Recoverable Schedule



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理