Python网络爬虫专业级框架_scrapy安装及基本概念
一、Scrapy介绍
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
二、VS中安装Scrapy
1、搜索scrapy包安装
2、安装pywin32
3、安装Beautiful Soup 解析包
三、猜想
我们说的爬虫,一般至少要包含几个基本要素:
1、请求发送对象 send,对于request的封装,防止被封。
2、解析文档对象
3、承载所需要解析的对象
4、获取对象后的操作者
5、整个流程错误的处理
四、验证
scrapy的核心对象
基本概念:
1、items:定义爬取的数据
2、spiders:爬取规则
3、item laoders:爬取到的数据填充item
4、item pipeline:存储爬取的数据
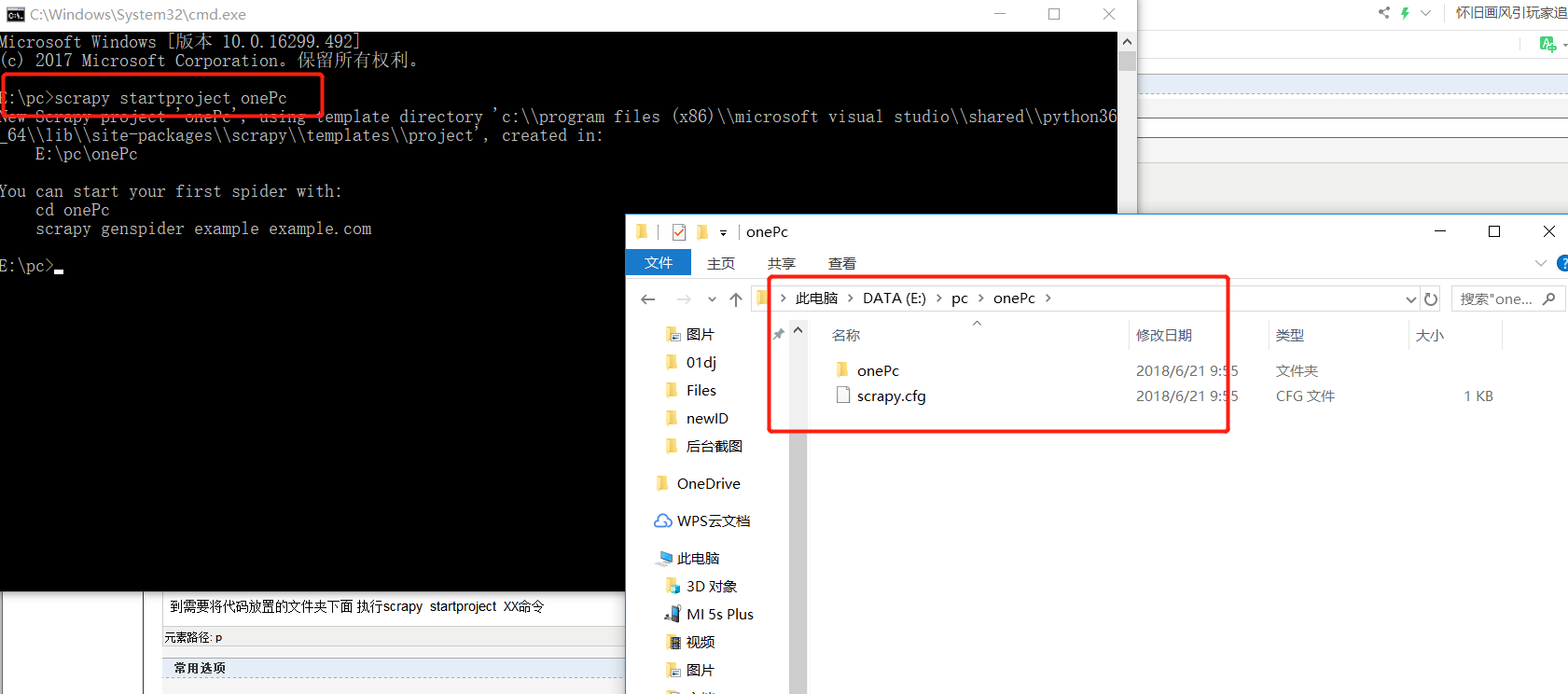
五、创建爬虫scrapy爬虫项目
到需要将代码放置的文件夹下面 执行scrapy startproject X
创建成功后会自动生成爬虫项目,项目里面各个文件的功能描述如下:
scrapy.cfg:它是scrapy项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
items.py:它定义item数据结构,所有的item的定义都可以放这里。
pipelines.py:它定义item pipeline的实现。
settings.py:定义项目的全局配置。
middlewares.py:定义spider middlewares和downloader middlewares的实现。
spiders:其内包含一个个spider的实现,每个spider都有一个文件。