mysql的explain执行计划的描述,实习遇到的对之前没有重视到的type和extra
结论:
0.执行计划,看一条还是多条,看是不是多表join,第一个是驱动表,观察是不是小表驱动。
1.看type 最少得是range。
如果是index 虽然走索引,但是走的是索引树全表扫描。相等于没有走最左前缀匹配。有abc联合索引,但是where只查bc没有a。(8.0索引跳跃,没有用到索引,通过可穷举a然后union优化让你用到索引)
2.看过滤性,扫描行数 len联合索引的长度
3.看extra 看是不是 using index using index condition索引
4.用到索引但是还是很慢,可能:
成本预估是基于统计数值,不准确
特殊sql,where a,b,c order by id 可能优先用id
区分度不高
实习遇到的优化mysql慢查询的问题。
截个图回忆下
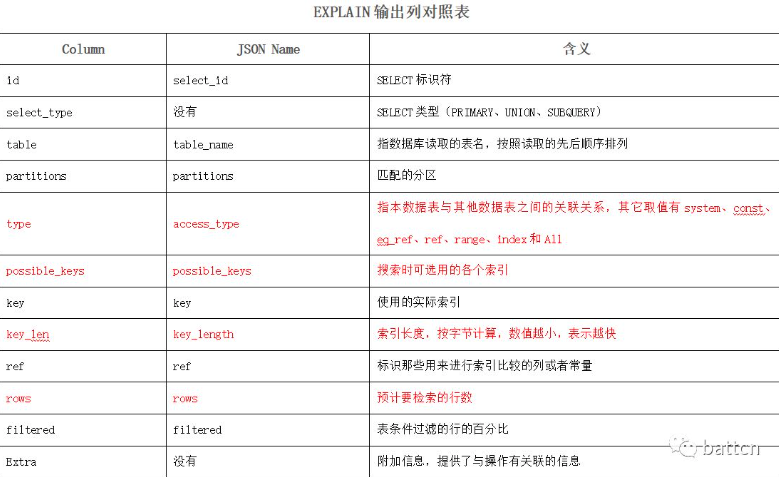
这里重点记录下type和extra的区别
Type:(这里选择的不根据你语句中select 的内容)
Const :如果唯一索引而且where的列是唯一索引 ,而且你搜索的值对应数据类型如果是int搜索的是int 不需要转转化(需要转化就不是const(常量值))。是int的话怎么都会用上常数。 如果是对应的数据类型是char但是搜索用int但是找不到,就会显示无使用索引。如果对应的数据类型是char还需要转化,无论是否找到数据都会显示type = index的索引
eq_ref : 如果搜索的是 join && 命中主键或非空唯一索引 && 等值连接
ref : 如果搜索的是 join && 命中被驱动表的普通非唯一索引 && 等值连接
又或者单表 命中普通非唯一索引
Range :范围查询
index:搜索的是 count等需要全表的索引树
搜索的是 虽然有索引但是where类型不匹配的单表
:需要扫描索引上的全部数据,只比全表扫描快一点
all:没有使用索引 走全表 (where 计算 或 函数 或 字段类型不一样 + 找数据中不同列相同的数据 + or/in/exist/not in/not exist 看成本计算(主要IO成本 +CPU成本) )
key 与select的值有关,如果不能满足覆盖索引,select * 可能直接走主键
extra:(开始根据你的select的内容)
Using where+using index :使用到联合索引但是没严格遵守最左前缀,使用范围查询
Using index:覆盖索引,不需要回表
Using where:没有用到索引或虽然where有对应索引条件但是select 的内容没有在索引中被覆盖
Using index condition:使用索引条件
Using join buffer(使用连接缓存):MySQL join使用了连接缓存。
当时的问题就是索引的优化,因为删除了一个字段,需要重新计算对应的索引修改成什么。修改了之后,会出现最后有没有走新索引的问题?我当时重新复习然后实践检验这些各个字段来判定速度的快慢。
加索引前,如果数据量太大,先考虑能不能修改mysql数据的长度
比如我那个时候,先删了索引,然后把varchar255转成varchar64了之后,再加索引的时候的速度再重建的速度快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号