
机器学习积累【2】
1、样本不平衡问题
正样本多余正样本:
1)欠采样,随机抽取负样本去除,使的正负样本比例平衡。缺点是会丢失多数类的一些重要信息,不能够充分利用已有的信息
2)过采样,增加一些正样本,使得正负样本比例接近。最简单的办法是简单复制少数类样本,缺点是可能导致过拟合,没有给少数类增加任何新的信息。改进的方法是通过在少数类中加入随机高斯噪声或产生新的合成样本等方法。
3)直接使用原始训练数据进行训练,但在训练好的分类器进行预测时,将比例缩放嵌入到其决策的过程中,称为“阈值移动”。
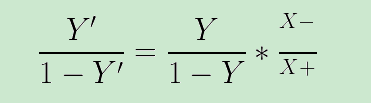
4)
在类别不平衡中,以下几个点需要注意:
常规的分类评价指标可能会失效,比如将所有的样本都分类成大类,那么准确率、精确率等都会很高。这种情况下,AUC是最好的评价指标。
你能够使用原型选择技术去降低不平衡水平。选择那些重要的样本。One-Sided Selection (OSS) 是一个预处理技术(模型训练之前使用),能够处理类别不平衡问题。
从另一个角度,可以增加小类的样本个数,可以使用过采样与原型生成技术(prototype-generation techniques)。
在K-Fold 校验中,每一份数据集中原则上应该保持类别样本比例一样或者近似,如果每份数据集中小类样本数目过少,那么应该降低K的值,直到小类样本的个数足够。
一般来说,如果事前不对不平衡问题进行处理,那么对于小类别的样本则会错误率很高,即大部分甚至全部小类样本都会分错。
见文章:
1、机器学习的训练数据不是看它分布均不均衡,而是看它符不符合原来的分布。如果符合原来的分布,那么训练误差最小化也就意味着整体分布误差的最小化,也就没有必要进行均衡。
2、基于样本的分布选取比例。因为大部分的model都假设train test 的data是iid的。如果条件所限没有真实比例的训练集,可以自己生成一些正例/负例配平或者用一些可以设置prior的model。
3、假如特征很强,比例偏差一些也没关系。特征弱的话,还是保持比例吧
【数据分布一致性的重要性】:训练/测试集的划分尽可能保持与原始数据分布的一致性。之前有很多的错误的理解,比如A、B类数据分布不均匀,A类:B类=100:1,由于B类样本少,B类预测出来的F1值会较小。若我们想提高F1,通过增大B类的样本数量比如达到了A类:B类=100:100,其实这种做法是错误的,因为这样数据分布被改变。用样本为A类:B类=100:100模型训练出来的模型与用样本分布为 A类:B类=100:1模型训练出来的模型的归纳偏好不一样,那么两者预测出来的结果也相差很大,这说明了保持训练样本和测试样本分布一致很重要

