
机器学习-常见问题积累【1】
-----JHJ_BABY 平时学习积累、归纳、整理-------------------------
1、python和R在做数据分析时各有自己得擅长得领域,如python做时域分析得难度就远远比R大,因为R有非常成熟得Package!
2、数据处理:如何处理缺失数据?各种处理方法得的利弊?
3、数据处理:如何将类别型(又称做描述型)变量转为连续变量?如何处理有序变量?如何处理无序变量?
4、数据处理:如何进行特征选择?如何进行数据压缩?
5、模型解释:什么是欠拟合?什么是过拟合?如何处理这两种情况?
6、模型解释:什么是偏差与方差分解?与欠拟合和过拟合有什么联系?
7、评估模型一般有哪些手段?
1)分类模型评估的方法有哪些?
2)回归问题评估方法有哪些?
3)数据不均衡的评估方法有哪些?
8、深度学习是否比其他学习模型都好?为什么?
9、在只有少量的有标签数据的情况下,如何构建一个反保险欺诈系统?
10、在数据分布不均匀的情况下,是采用过采样还是欠采样?如何调整代价函数和阈值?
11、SVM,什么是最大间隔分类器?什么是kernel,如何选择kernel?
12、为什么K-means不适合异常值检测?K-means和GMM是什么关系?是否可以用FMM来直接拟合异常值?
13、如何可以得到无监督学习中的分类规则?
14、L1和L2正则化两者有什么不同,什么时候采用L1,什么时候采用L2?为什么L1可以得到稀疏解?它们与嵌入式特征选择有什么联系?
15、根据岗位准备一份项目策划书
16、精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
看懂周志华<<机器学习>>前十章,并熟练的使用Sklearn中基础API进行建模就可以了,勿矫枉过正,如果你的岗位不是理论型科学家岗位,不要与
数学推导死磕。
-----------------------------------------------------------------------------------------
Answer:
2、
第一类:
1>分析缺失值所在比例,如果某个属性的缺失值太多,可考虑去除该属性。
2>可以用均值、众数、中位数、随机值填充代替。
3>用0填充代替 。
第一类措施,效果一般,相当于人为的添加了噪声
第二类:
用其他变量做预测模型(如logistic)来算出缺失变量。
第二类效果稍微比第一类好点。但是存在缺陷,如果其他变量和该变量毫无关联,那么预测值将毫无意义。如果预测的缺失值很准确,则说明其他变量和该变量强相关,这个变量没有存在的意义。
第三类:
将缺省值当作一个类型,把变量映射到高维空间。比如,一个变量为男、女、缺失值的取值范围,映射到高维后就成为是否为难,是否为女,是否为缺失值,由原来的一维映射到三维。这样做的好处是,可以保存原始信息,不用考虑缺失值的问题。缺点在于这种情况在基础变量多,数据量大的时候容易出现特征爆炸,计算量剧增,如果样本不够大,特征信息稀疏、计算效果差。
------------------------------------------------------------------
3、
类别型转连续型的变量,一般理解就是用离散数据拟合一个回归方程,将相当于数电信号转模电信号原理差不多。但数据处理方面,我们接触的大多数是连续型转类别型,比如将连续的年龄分布,转成类别型:小学生,初中生,高中生,大学生,其他。
所谓有序变量,如班长<排长<连长,只可排序,加减,不可乘除。所谓无序变量,如赤、橙、黄、绿、青、蓝、紫。这两者在处理的时候最好都做下one-hot encoding(独热编码又称哑变量),也有将有序变量直接当作连续变量来用,但最好是做下one-hot encoding。
-------------------------------------------------------------------
4、
过滤式(filter)\包裹式(wrapper)\嵌入式(embedding)
过滤式(filter):先对特征集选择,然后进行训练。其特征重要性由“相关统计量”的一个算法来计算得到,一般用的少。
包裹式(wrapper):直接将学习模型性能做为特征子集的评价准则,针对给定的学习模型进行优化。wrapper比filter要好。特征选择过程需要多次训练学习器,因此计算开销比filter大很多。
嵌入式(embedding):将特征选择和模型训练过程融为一体。
数据压缩:总的思想就是将一个原始信号数据,采样抽取其特征信号,保存下这些特征信号后的大小肯定比原始信号数据小,而这些特征信号在后来的解压过程能够大部分的还原原始信号。
------------------------------------------------
5、
过拟合:在训练数据上表现良好,在测试数据上表现差。
常见处理方式:
交叉验证、增加样本、减少特征量、降低正则化、去除噪声特征量等。
欠拟合:在训练数据和未知数据上表现都很差。
常见处理方式:
增加特征量、添加组合特征、增强正则化等。
6、
偏差度量了学习算法的期望预测与真实结果的偏离程度,即i刻画了学习算法本身的拟合能力。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声,则表达了在当前上任何学习算法所能达到的期望泛化误差的下界,刻画的是学习问题本身的难度。
给定学习任务,为取得好的泛化性能,则需要使偏差较小,即充分拟合数据,并使得方差较小,即使得数据扰动产生较小的影响。
算法学习初期,偏差主导了泛化错误率,训练拟合数据不充分(欠拟合);在学习后期,数据拟合充分后,算法拟合能力很强,容易拟合噪声数据(过拟合),这时方差主导了泛化错误率。
7、
1)分类模型评估方法:
混淆矩阵、准确率(Accuracy)、对数损失函数(log-loss)、AUC、ROC
2)回归问题评估方法有:
MAE(Mean Absolute Error)平均绝对差值

MSE(Mean Square Error)均方误差
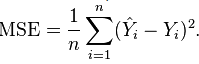
RMSE(Root Mean Square error)均方根误差


