python day2
Day2
模块初识
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。
Sys
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
print(sys.argv)
#输出
$ python test.py helo world
['test.py', 'helo', 'world'] #把执行脚本时传递的参数获取到了
# !/usr/bin/env python # -*- coding:utf-8 -*- # Author: liang # sys 模块 import sys print(sys.path)# 打印环境变量 # sys.path 打印的是python的环境变量。 #如果模块存在一下的路径中,那么就可以使用这个模块 #一般第三库会存在'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages'] 这个路径下面 #标准库一般放在刚刚的路径的上一层 print(sys.argv)# 打印当前文件的绝对路径 在命令行界面是相对路径 #sys.argv 可以去输入的值 ,就是在输入的时候可以取当前列表的值 #例如 这样的取值 sys.argv[2]取值获取列表中第三位的数字
Os
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
os.system("df -h") #调用系统命令
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: liang
# os 模块就的调用操作系统的命令
import os
cmd_res=os.system("dir") # 获取当前目录下的所有文件调用了系统命令
#只执行命令。不保存结果。
print("--->",cmd_res) #输出到屏幕上。而不是存在变量中。0 是命令的成功执行的状态吗
#如果你想存在变量中、那么用如下
#os.oppen可以存储在变量中。后面如果不加上.read()那么输出的只是一串内存地址
cms_res2=os.popen("dir").read()
print(cms_res2)
#如果想在当前目录下创建一个目录
os.mkdir("new_dir")
完全结合一下
import os,sys
os.system(''.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行
自己写一个模块
在当前目录下写一个简单的登陆过页面名字叫做 login
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: liang
_username='liang'
_password='abc123456'
username=input("Username:")
password=input("Password:")
if _username==username and _password==password:
print("welcome to {name} login ....".format(name=username))
else:
print("Invalerror is username or password")
在另一个页面直接用import login调用这个模块就可以了
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: liang
import login
如果login不在本目录下呢?如果是这样的吧。是调用不了的。直接报错。
两个方法。就是吧这个login放在python的全局变量中放在lib\ site-packages路径下!!就ok了。
或者在修改一下环境变量。再加一个路径
2.什么是 .pyc
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
3.数据类型
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
先扫盲 http://www.cnblogs.com/alex3714/articles/5895848.html
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
2、布尔值
真或假
1 或 0
3、字符串
"hello world"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
4.数据运算
算数运算:
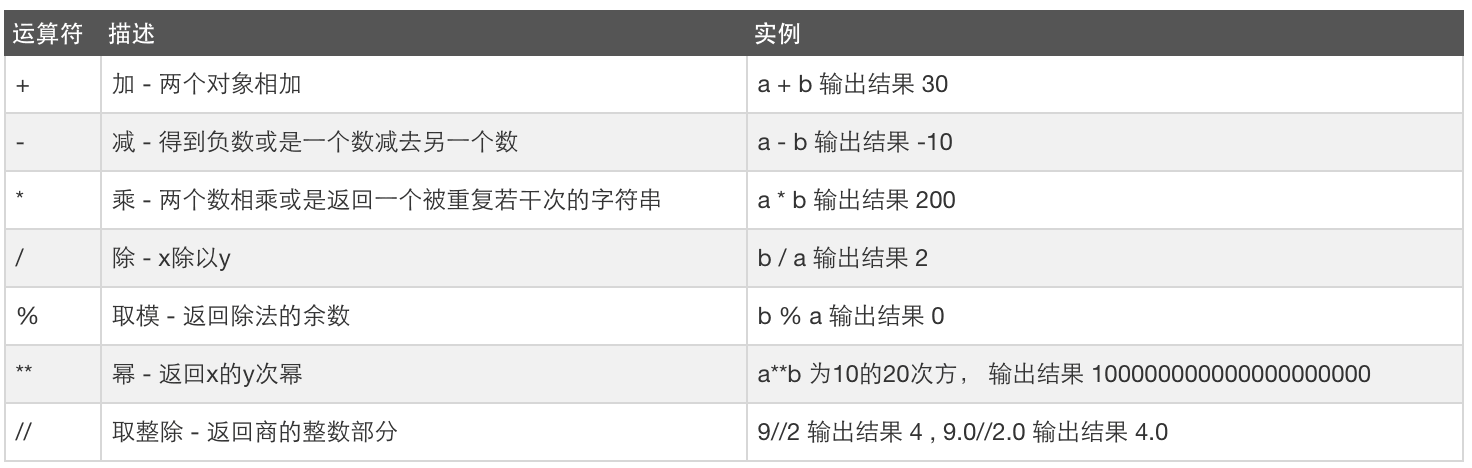
比较运算:

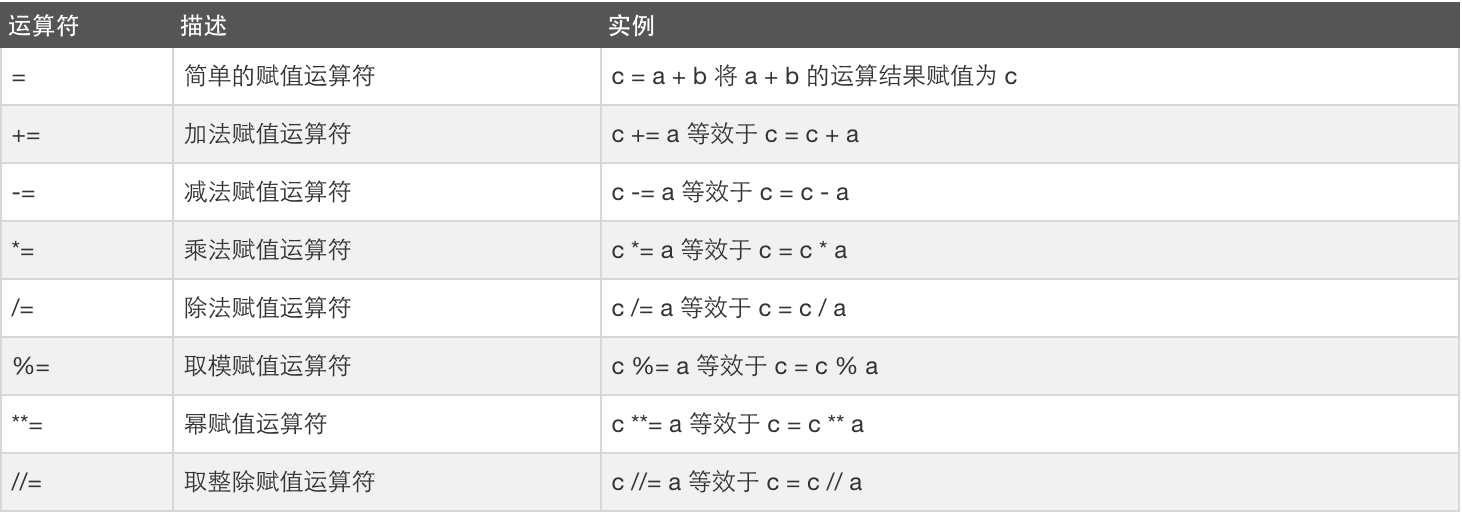
赋值运算:
逻辑运算:

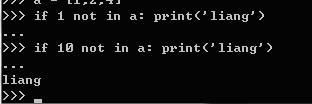
表示 如果 10 没有在 a里面就输入liang
成员运算:

身份运算:

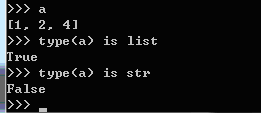
可以用于判断一个类型
位运算:
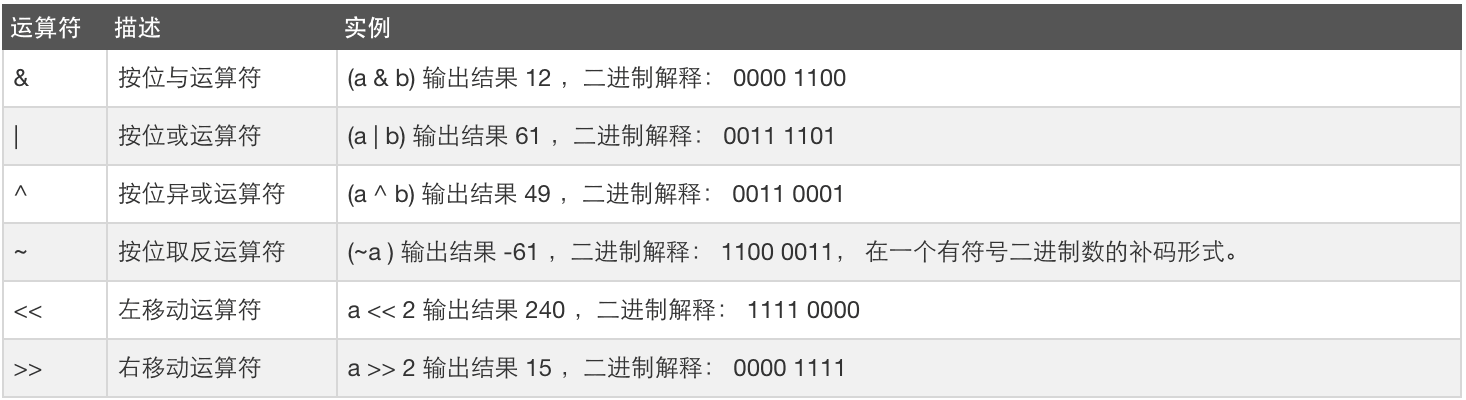


#!/usr/bin/python a = 60 # 60 = 0011 1100 b = 13 # 13 = 0000 1101 c = 0 c = a & b; # 12 = 0000 1100 print "Line 1 - Value of c is ", c c = a | b; # 61 = 0011 1101 print "Line 2 - Value of c is ", c c = a ^ b; # 49 = 0011 0001 #相同为0,不同为1 print "Line 3 - Value of c is ", c c = ~a; # -61 = 1100 0011 print "Line 4 - Value of c is ", c c = a << 2; # 240 = 1111 0000 print "Line 5 - Value of c is ", c c = a >> 2; # 15 = 0000 1111 print "Line 6 - Value of c is ", c
运算符优先级:
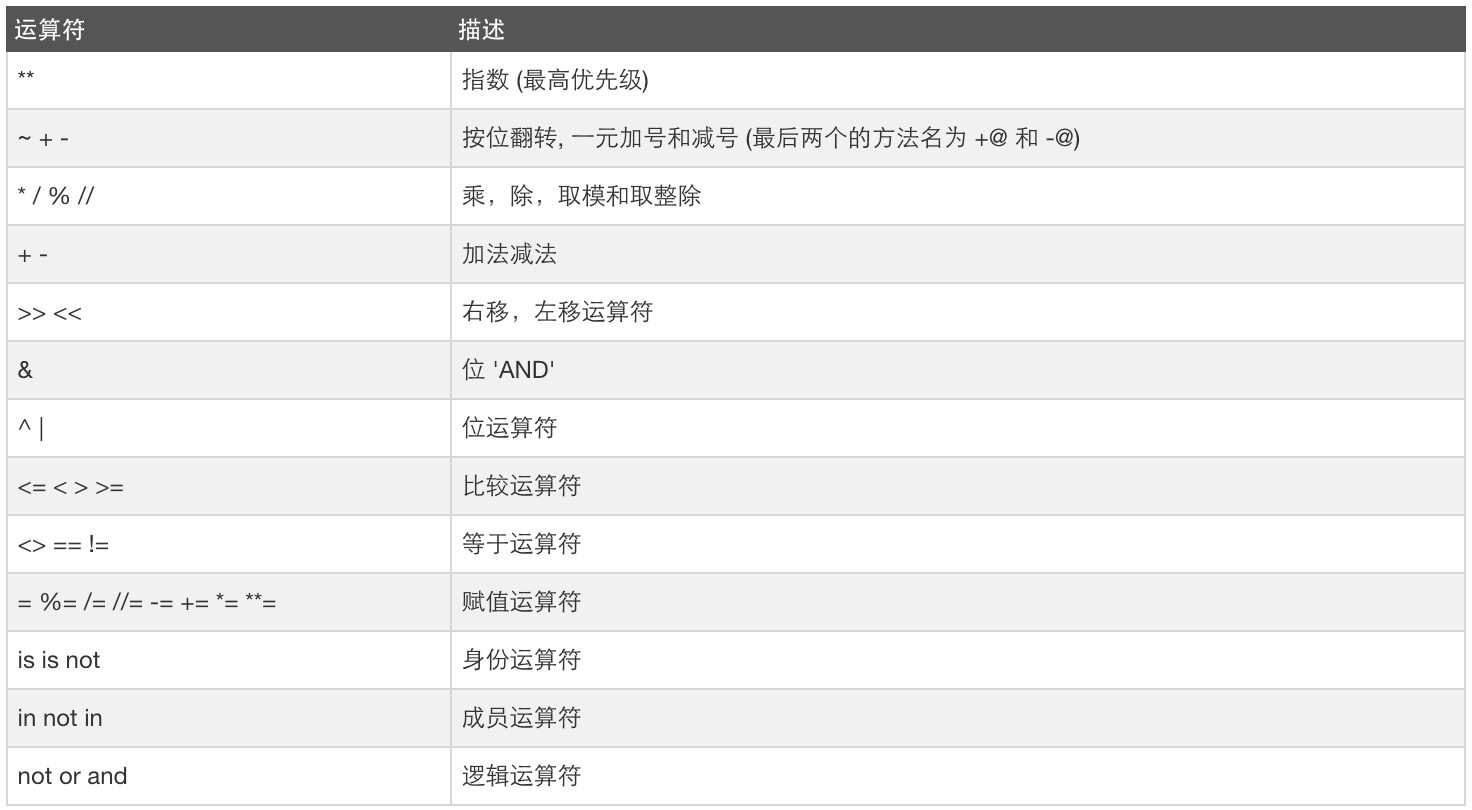
三元运算
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
三、进制
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF 二进制到16进制转换http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
计算机内存地址和为什么用16进制?
为什么用16进制
1、计算机硬件是0101二进制的,16进制刚好是2的倍数,更容易表达一个命令或者数据。十六进制更简短,因为换算的时候一位16进制数可以顶4位2进制数,也就是一个字节(8位进制可以用两个16进制表示)
2、最早规定ASCII字符集采用的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用2个16进制直接就能表达出来,不管阅读还是存储都比其他进制要方便
3、计算机中CPU运算也是遵照ASCII字符集,以16、32、64的这样的方式在发展,因此数据交换的时候16进制也显得更好
4、为了统一规范,CPU、内存、硬盘我们看到都是采用的16进制计算
16进制用在哪里
1、网络编程,数据交换的时候需要对字节进行解析都是一个byte一个byte的处理,1个byte可以用0xFF两个16进制来表达。通过网络抓包,可以看到数据是通过16进制传输的。
2、数据存储,存储到硬件中是0101的方式,存储到系统中的表达方式都是byte方式
3、一些常用值的定义,比如:我们经常用到的html中color表达,就是用的16进制方式,4个16进制位可以表达好几百万的颜色信息。
四、bytes类型
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
字符串可以编码成字节包,而字节包可以解码成字符串。
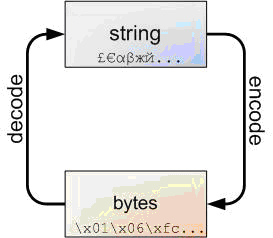
字符串可以编码成字节包,而字节包可以解码成字符串。
c='€20'.encode('utf-8') print(c) c2=b'\xe2\x82\xac20' c3=c2.decode() print(c3)
再举一个例
msg="我爱北京天安门" print(msg.encode(encoding="utf-8").decode(encoding="utf-8")) #encode 字符串转换bytes编码,decode 是bytes转换为str
这个问题要这么来看:字符串是文本的抽象表示。字符串由字符组成,字符则是与任何特定二进制表示无关的抽象实体。在操作字符串时,我们生活在幸福的无知之中。我们可以对字符串进行分割和分片,可以拼接和搜索字符串。我们并不关心它们内部是怎么表示的,字符串里的每个字符要用几个字节保存。只有在将字符串编码成字节包(例如,为了在信道上发送它们)或从字节包解码字符串(反向操作)时,我们才会开始关注这点。
传入encode和decode的参数是编码(或codec)。编码是一种用二进制数据表示抽象字符的方式。目前有很多种编码。上面给出的UTF-8是其中一种,下面是另一种:
>>>'€20'.encode('iso-8859-15') b'\xa420' >>> b'\xa420'.decode('iso-8859-15') '€20'
编码是这个转换过程中至关重要的一部分。离了编码,bytes对象b'\xa420'只是一堆比特位而已。编码赋予其含义。采用不同的编码,这堆比特位的含义就会大不同:
>>> b'\xa420'.decode('windows-1255') '₪20'
5.列表、元组操作
列表的定义
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: liang #list tables names=['liang','ccc','cc','we','ca','ca','ca','ccc','liang','liang','ccc'] ################### 查########################### #取出第一个 print(names[0],names[2]) #取出第一个到倒数第二个 # 0:-1 只会取出第一个到最后一个前面的一个 #只会取头不取尾 print(names[0:-1]) #切片 print(names[-1]) #取出最后一位,倒数第二个-2 #取出最后两个值 print(names[-2:]) #取出最后一个值-2: 如果后面是-1 可以忽略 print(names[:3]) #如果前面是0 可以忽略 ########################### 增 #################### #列表中添加值,放在最后一位 names.append("liangkaiqiang") print(names) #添加到指定位置上去 names.insert(1,"kai") print(names) ########################## 改 ####################### names[2]="123456" print(names[2]) ########################## 删 ####################### #两种方法: # 1 delete # 2 remove # 另外一种 pop # pop 不输入下标的话默认是删除最后一位 names.remove("123456") print(names) del names[1] print(names) names.pop() names.pop(1) # = del names[1] print(names) ############################### 查询列表中的下标 ######################## print(names.index("ca")) #直接打印 print( names[names.index("ca")] ) #统计同名的数量 print(names.count("ca")) #names.clear() #清空列表 #names.reverse() 反转列表 ##排序 顺序为特殊符号 数字、大写、小写 #names.sort() #print(names) # 列表扩展 names2=[1,3,4,5,212,6,112] names.extend(names2) #del names2 print(names,names2)
列表的copy参数(浅层复制)
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: liang # 列表的copy参数 names=['liang','ccc','cc',["kai","qiang"],'we','ca','ca','ca','ccc','liang','liang','ccc'] names2=names.copy() print(names) print(names2) #修改names 查看names2的列表 names[1]="梁" names[3][0]="KAI" print(names) #names修改后,names只是复制列表的第一层 #如果names 里面有子列表。那么如果names修改了其列表 #那么names2 也会随着改变。因为子列表。内存地址。如果说names或names2 #修改了。那么都会改变。 print(names2) 那么如果我想深深的copy一份呢? 就可以用到copy模块了。如下: import copy names=['liang','ccc','cc',["kai","qiang"],'we','ca','ca','ca','ccc','liang','liang','ccc'] names2=copy.deepcopy(names) print(names) print(names2)
总结一下
########查询############
names.extend() #列表扩展
names.sort() #列表排序
names.reverse() #反转列表
names.clear() #清空列表
names.count() #统计同名
names.index() #查询列表中的下标
names.pop() #添加数据
names.append() #添加数据
names.copy() #复制列表(浅层复制)
names.remove() #删除数据
names[0:-1] #切片
###深copy
import copy
names2=copy.deepcopy(names)
## 步长切片
print(names[::2])
补充:浅层copy 的三种方式
import copy
person=['name',['liang',100]]
p1=copy.copy(person)
p2=person[:]
p3=list(person)
print(person)
print(p2)
print(p1)
print(p3)
copy建立联合账户
#浅层copy的用处是创建一个联合账号
person=['name',['liang',100]]
p1=person[:]
p2=person[:]
p1[0]='alex'
p2[0]='fengjie'
p1[1][1]=50
print(p1)
print(p2)
2. 元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index,完毕。
程序练习
请闭眼写出以下程序。
程序:购物车程序
需求:
- 启动程序后,让用户输入工资,然后打印商品列表
- 允许用户根据商品编号购买商品
- 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
- 可随时退出,退出时,打印已购买商品和余额
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: liang import sys,os ##### 定义一个列表。里面包含商品 product_list=[ ('Iphone',5800), ('Mac Pro',9800), ('Watch',1600), ('Bike',800), ('coffee',31), ('Alex python',120) ] salary=input("Input your salary:") #定义一个空列表。存储购买的商品 shopping_list=[] #判断salary是否输入的是数字。如果是就改为int if salary.isdigit(): salary=int(salary) while True: #### enumerate 函数调出列表中的下标 for index,item in enumerate(product_list): #print(product_list.index(item),item) #index 表示的是下标 后面是列表 print(index,item) ###用户输入数字购买商品 user_choice =input("选择要买吗?>>>>>:") #判断用户是否输入的是数字。如果是就改为int if user_choice.isdigit(): user_choice=int(user_choice) #判断用户输入的数字是否是大于列表中的数字。范围应该是大于0 小于列表中的最大下标 if user_choice < len(product_list) and user_choice >=0: #获取商品价格 p_item=product_list[user_choice] if p_item[1] <= salary: ##买的起 ###买的起之后就把商品信息存入空列表中 shopping_list.append(p_item) #付款之后扣除余额 salary -= p_item[1] print("Added %s into shopping cart,your current balance is %s" %(p_item,salary) ) else: print("你的余额只剩下[%s],还买个毛线啊"%(salary)) else: print("商品不存在!!!!") #如果用户输入的Q 就退出 elif user_choice == 'q': #print('exit.......') print("你购买了如下商品请查看余额为%s"%(salary)) for index,item2 in enumerate(shopping_list): print(index,item2) sys.exit("Bey Bey!!!!!!") #如果输入的其他就输出。一个错误 else: print("INvalid option") else: print("你输入的不是数字!!")
6.字符串操作
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: liang #############字符串操作##################### ##定义字符串 name='liang {name} or {old} old' ###name.capitalize 首字母大写 print(name.capitalize()) #name.countc 查询变量中有几个重名 print(name.count("a")) #name.center(50,-) 美化输出 print(name.center(50,"-")) #字符串转为bytes print(name.encode()) #判断一个字符串以什么结尾。如果成功为TRUE 错误为False print(name.endswith("ng")) #特殊字符转为空格 例如:tabsize=30 print(name.expandtabs()) # name.find() 查找 print(name.find("a")) #字符串的切片 print(name[name.find("a"):]) #format 用法 (name='kai',old=20) print(name.format(name='kai',old=20)) # format_map 字典传值 print(name.format_map({'name':'liang','old':'20'})) #index判断里面是否存在这个数值 print(name[name.index("a")]) #判断变量是否是阿拉伯数。数字和英文 print(name.isalnum()) #判断是否是一个纯英文字符 print(name.isalpha()) #判断是否是一个小数 print(name.isdecimal()) #判断是否是一个整数 print(name.isdigit()) #判断是不是一个合法的标识符。是不是一个合法的变量名 print('aaa'.isidentifier()) #判断是不是一个数字。但是值是判断整数字。 print('12.00'.isnumeric()) #是不是一个空格 print(' '.isspace()) #判断首字母是不是大写 print('My Name Is '.istitle()) #判断是否能打印的。在linux中只有终端设备不能被打印 print('My Name Is '.isprintable()) #判断是否是大写 print('My '.isupper()) #join的作用可以拆分列表 比如把列表改为字符串 print('+'.join(['1','2','4'])) #如果字符串长度没有大于定义的长度就会在后面添加自定义的符号 print(name.ljust(50,'*')) ##如果字符串长度没有大于定义的长度就会在前面添#加自定义的符号 print(name.rjust(50,'*')) #lower 把大写变成小写 print('ABC'.lower()) #把小写变成大写 print('ABc'.upper()) #从左边去掉空格和回车 print('\nABc'.lstrip()) #从右边去掉空格和回车 print('ABc\n'.rstrip()) #去掉左右两边的空格和回车 print('\nABc\n'.strip()) #maketrans 的用法 数字对应!!! p=str.maketrans("abcdef","123456") print('alex li'.translate(p)) # 字符串替换 print('alex'.replace('a','L',1)) #从左往右查询,查询最右的一个值 print('alex x x x '.rfind('x')) #把字符串分成列表。默认是按照空格分。也可以自定义 print('1+2+3+4+5'.split('+')) #按照空格来分成列表 print('1+2+\n3+4+5'.splitlines()) #大写变小写。小写变大写 print('Liang Kai'.swapcase()) #不够长度补位 print('liang'.zfill(50))
常用的总结一下:
print(name.center(50,"-")) #美化输出
print(name.encode())#字符串转为bytes
print(name.find("a")) # name.find() 查找
print(name.format(name='kai',old=20))
print(name[name.index("a")]) #index判断里面是否存在这个数值
print(name.isalnum())#判断变量是否是阿拉伯数。数字和英文
print(name.isdigit())#判断是否是一个整数
print('+'.join(['1','2','4'])) #join的作用可以拆分列表 比如把列表改为字符串
print('\nABc\n'.strip())#去掉左右两边的空格和回车
#maketrans 的用法 数字对应!!!
p=str.maketrans("abcdef","123456")
print('alex li'.translate(p))
print('alex'.replace('a','L',1)) # 字符串替换
print('1+2+3+4+5'.split('+')) #按照空格来分成列表
print('Liang Kai'.swapcase())#大写变小写。小写变大写

