
redis17- MMAP内存映射 与 零拷贝sendFile
开篇
例如我们常见的 kafka、nginx 以及 tomcat 等底层都用的这类技术,这里暂且用 kafka 来列举案例。
当我们从 kafka 读取数据的时候,我们会调用 read 方法读取指定的内容,然后调用 write 方法,将字节流写到 socket 中,那么,我们调用这两个方法,在 OS 底层发生了什么呢?我这里画了一个图,尝试解释这个过程。
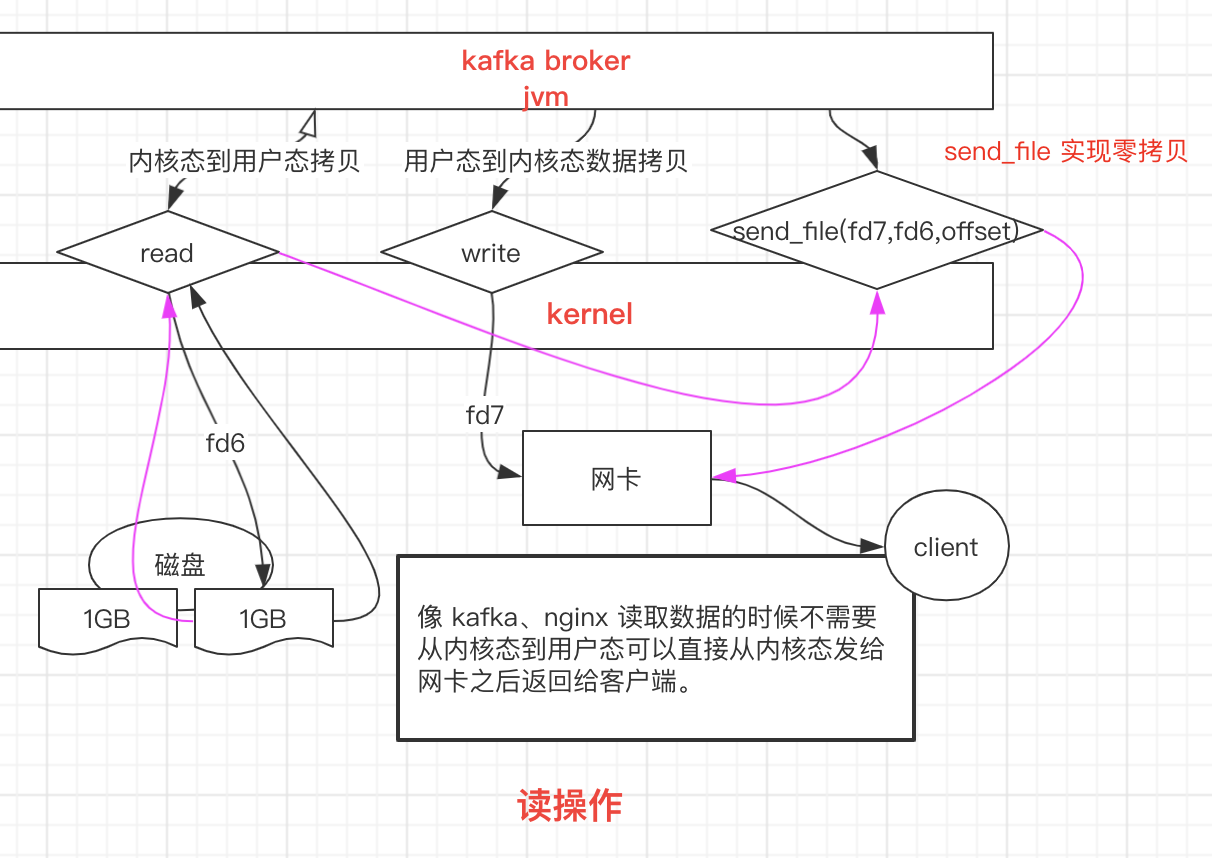
以下步骤都是黑色线条标识的路线:
-
read 调用导致 用户态 到 内核态 的一次变化,同时,第一次复制开始:DMA(Direct Memory Access,直接内存存取,即不使用 CPU 拷贝数据到内存,而是 DMA 引擎传输数据到内存,用于解放 CPU) 引擎从磁盘读取指定内容,并将数据放入到内核缓冲区。
-
发生第二次数据拷贝,即:将内核缓冲区的数据拷贝到用户缓冲区,同时,发生了一次 内核态 到 用户态 的上下文切换。
-
发生第三次数据拷贝,我们调用 write 方法,系统将 用户缓冲区 的数据拷贝到 Socket 缓冲区。此时,又发生了一次 用户态 到 内核态 的上下文切换。
-
第四次拷贝,数据异步的从 Socket 缓冲区,使用 DMA 引擎拷贝到网络协议引擎。这一段,不需要进行上下文切换。
-
write 方法返回,再次从 内核态 切换 到用户态。
mmap 内存映射优化
mmap 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少 内核空间 到 用户空间 的拷贝次数。
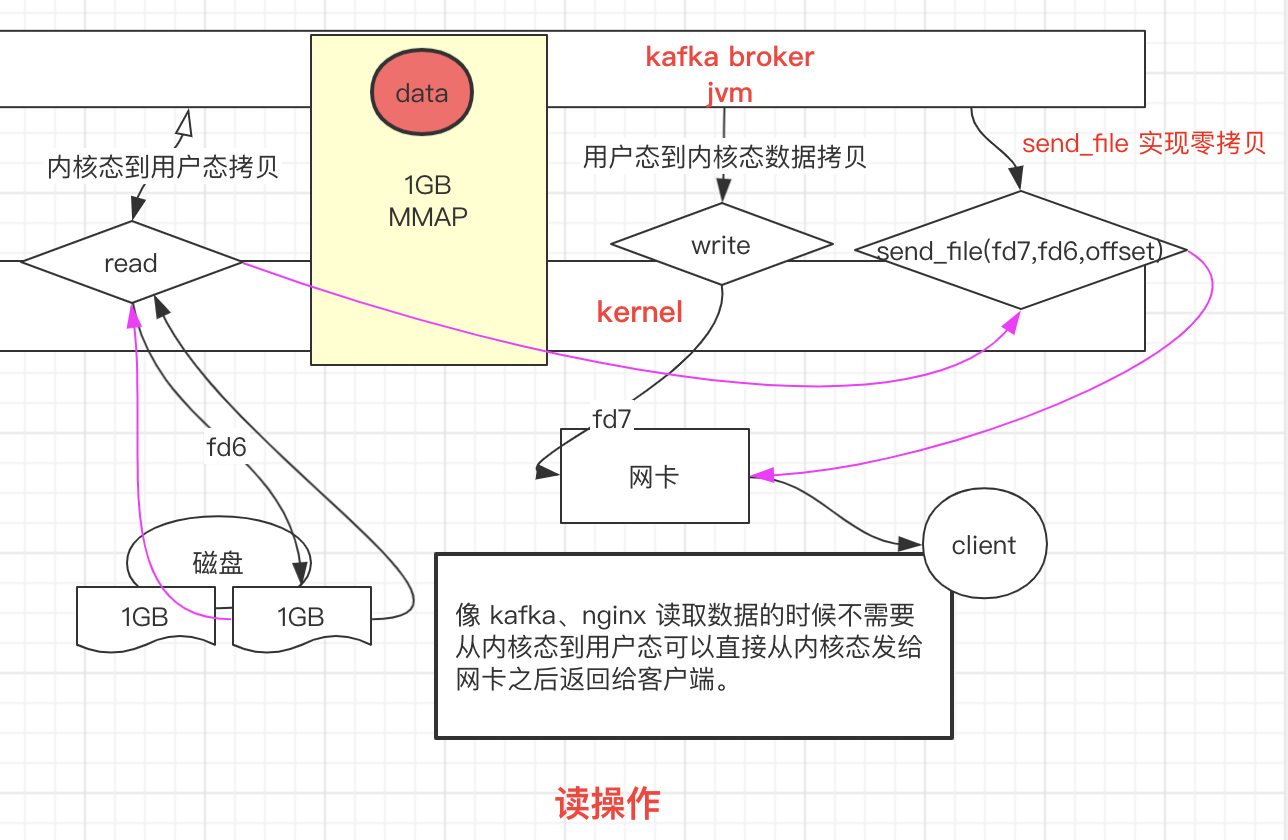
如上图,user buffer 和 kernel buffer 共享 data 数据。如果你想把硬盘的 data 数据传输到网络中,再也不用拷贝到用户空间,再从用户空间拷贝到 Socket 缓冲区。
现在,你只需要从 内核缓冲区 拷贝到 Socket 缓冲区即可,这将减少一次内存拷贝(从 4 次变成了 3 次),但不减少上下文切换次数。(这块需要大家再根据前面的讲解好好理解一下)
sendFile 零拷贝优化
其基本原理如下:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,同时,由于和用户态完全无关,就减少了一次上下文切换。看粉色的线条标识。如上图,我们进行 sendFile 系统调用时,数据被 DMA 引擎从文件复制到内核缓冲区,然后可以直接从内核缓冲区进入到 Socket,这时,是没有上下文切换的,因为在一个空间。
最后,数据从 Socket 缓冲区进入到协议栈。
此时,数据经过了 2 次拷贝,即:
第一次使用 DMA 引擎从文件拷贝到内核缓冲区,第二次从内核缓冲区将数据拷贝到网络协议栈;内核缓存区只会拷贝一些 offset 和 length 信息到 SocketBuffer,基本无消耗。
再稍微讲讲 mmap 和 sendFile 的区别。
- mmap 适合小数据量读写,sendFile 适合大文件传输。
- mmap 需要 4 次上下文切换,3 次数据拷贝;sendFile 需要 3 次上下文切换,最少 2 次数据拷贝。
- sendFile 可以利用 DMA 方式,减少 CPU 拷贝,mmap 则不能(必须从内核拷贝到 Socket 缓冲区)。
在这个选择上:rocketMQ 在消费消息时,使用了 mmap。kafka 使用了 sendFile。(可以思考下为什么 kafka 适合使用 sendFile?因为 kafka 大部分场景是使用消息队列,基本上没有复杂场景,就是一个数据的流转,所以适合数据进来直接被消费方读取走了,在这期间不需要做其他内部业务逻辑)
Java 世界的例子
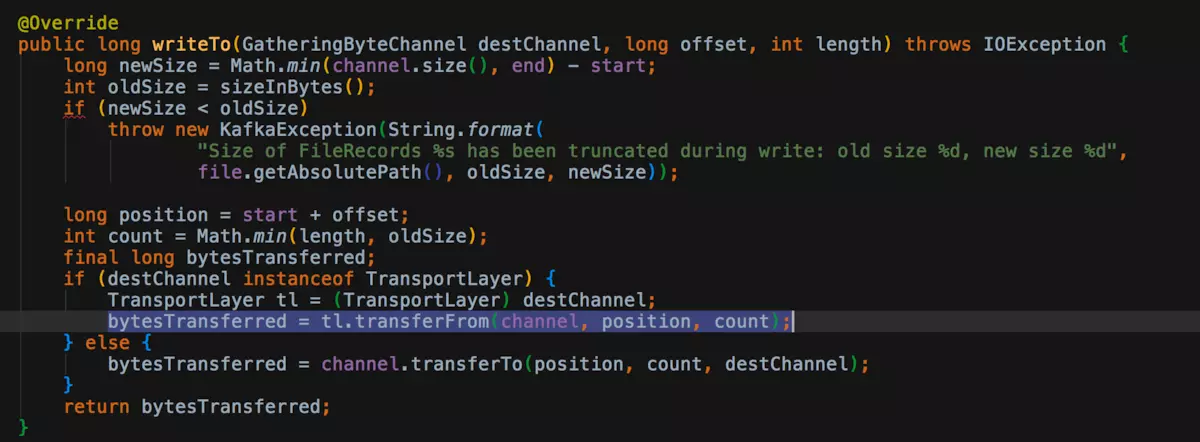
kafka
tomcat
tomcat 内部在进行文件拷贝的时候,也会使用 transferto 方法。

tomcat 在处理一下心跳保活时,也会调用该 sendFile 方法。

所以,如果你需要优化网络传输的性能,或者文件读写的速度,请尽量使用零拷贝。他不仅能较少复制拷贝次数,还能较少上下文切换,缓存行污染。

