


Dubbo 序列化最佳实践
序列化
序列化是将一个对象变成一个二进制流就是序列化, 反序列化是将二进制流转换成对象。
为什么要序列化?
1. 减小内存空间和网络传输的带宽
2. 分布式的可扩展性
3. 通用性,接口可共用。
dubbo RPC是dubbo体系中最核心的一种高性能、高吞吐量的远程调用方式,我喜欢称之为多路复用的TCP长连接调用,简单的说:
1. 长连接:避免了每次调用新建TCP连接,提高了调用的响应速度
2. 多路复用:单个TCP连接可交替传输多个请求和响应的消息,降低了连接的等待闲置时间,从而减少了同样并发数下的网络连接数,提高了系统吞吐量。
dubbo RPC主要用于两个dubbo系统之间作远程调用,特别适合高并发、小数据的互联网场景。
而序列化对于远程调用的响应速度、吞吐量、网络带宽消耗等同样也起着至关重要的作用,是我们提升分布式系统性能的最关键因素之一。
在dubbo RPC中,同时支持多种序列化方式,例如:
1、dubbo序列化:阿里尚未开发成熟的高效java序列化实现,阿里不建议在生产环境使用它
2、hessian2序列化:hessian是一种跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式
3、json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自己实现的简单json库,但其实现都不是特别成熟,而且json这种文本序列化性能一般不如上面两种二进制序列化。
4、java序列化:主要是采用JDK自带的Java序列化实现,性能很不理想。
在通常情况下,这四种主要序列化方式的性能从上到下依次递减。对于dubbo RPC这种追求高性能的远程调用方式来说,实际上只有1、2两种高效序列化方式比较般配,而第1个dubbo序列化由于还不成熟,所以实际只剩下2可用,所以 dubbo RPC默认采用hessian2序列化。
但hessian是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对java进行优化的。最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括:
- 专门针对Java语言的:Kryo,FST等等
- 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等
这些序列化方式的性能多数都显著优于hessian2(甚至包括尚未成熟的dubbo序列化)
其中,Kryo是一种非常成熟的序列化实现,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。而FST是一种较新的序列化实现,目前还缺乏足够多的成熟使用案例,但我认为它还是非常有前途的。
序列化性能分析与测试
使用两台相同的服务器配置,相同的 jvm 启动参数,通过配置不同数量的多线程以及传输文本大小进行压测
序列化生成字节码的大小是一个比较有确定性的指标,它决定了远程调用的网络传输时间和带宽占用。
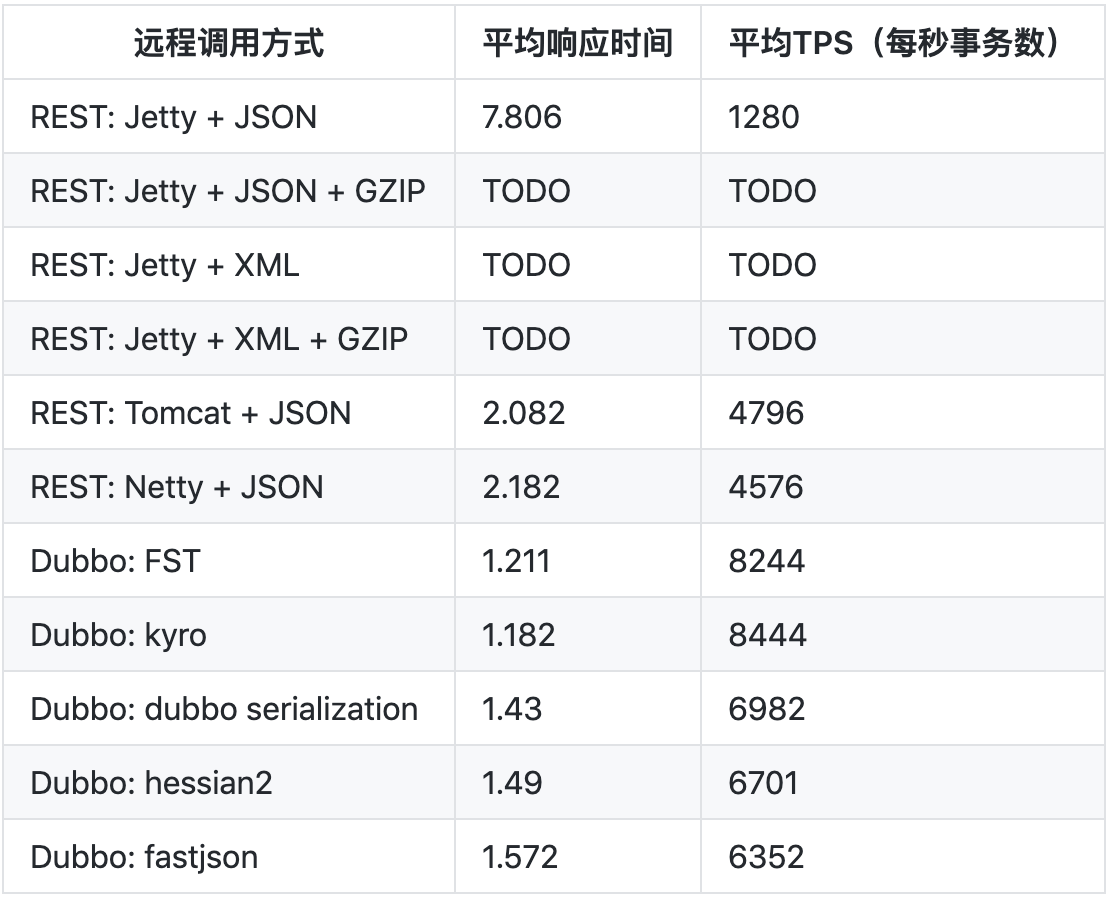
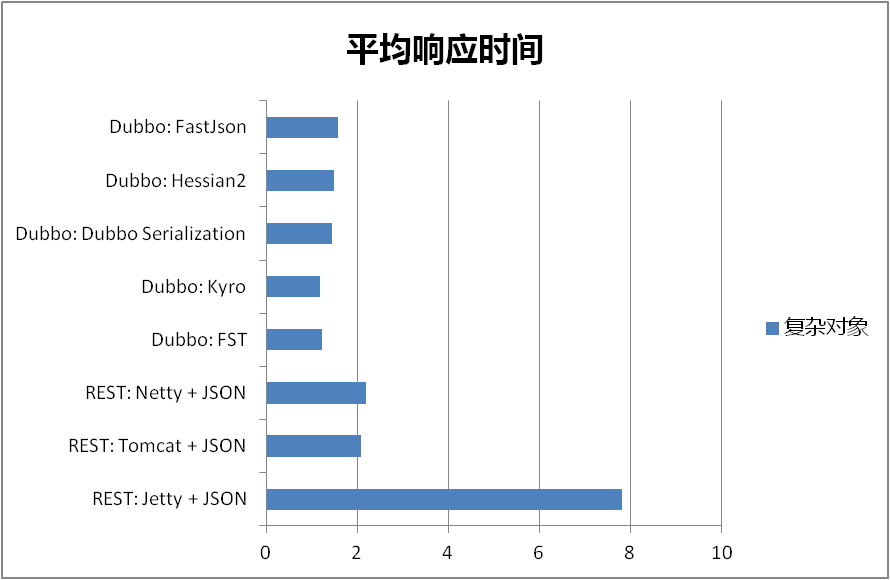
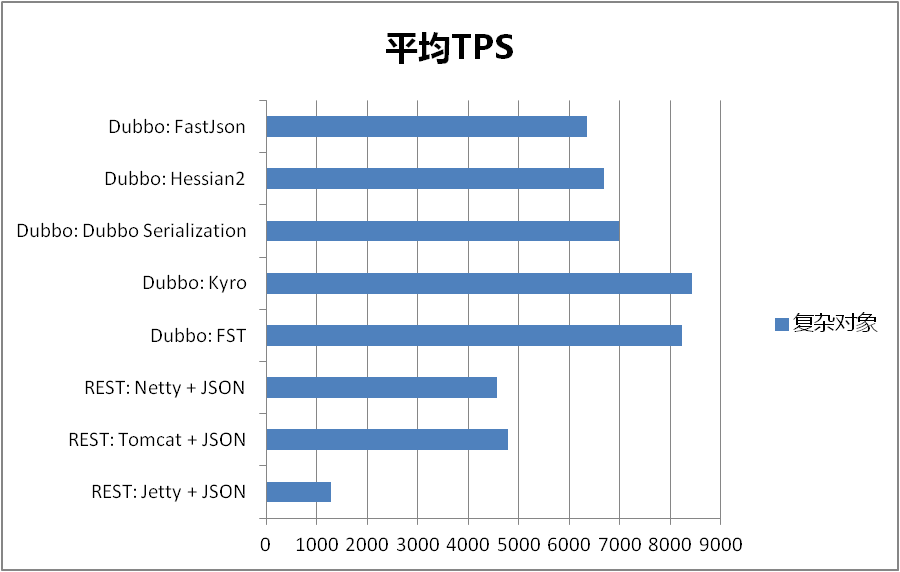
针对复杂对象的结果如下(数值越小越好):


Dubbo RPC 中不同序列化响应时间和吞吐量对比:
测试总结
就目前结果而言,我们可以看到不管从生成字节的大小,还是平均响应时间和平均TPS,Kryo 和 FST 相比 Dubbo RPC 中原有的序列化方式都有非常显著的改进。如果只是 java to java 且是线上使用,建议使用序列化协议:kryo。
有篇博文自己写代码压测发现 fst 比 kryo 效率更高,但是有高手评论说写法有问题,经过更改最后可能还是 kryo 效率更高,具体博文地址:https://www.iteye.com/blog/liuyieyer-2136240
有兴趣的同学可以自己研究一下。

