redis-05 redis 持久化AOF&RDB
1、前言
Redis 的持久化分为 2 种,一种是 RDB(全量 redis database),一种是 AOF(增量 append only file)。
RDB 是旧的模式,现在基本上都使用 AOF。当然,今天两个都会一起聊聊。
2、RDB
RDB 流程图:
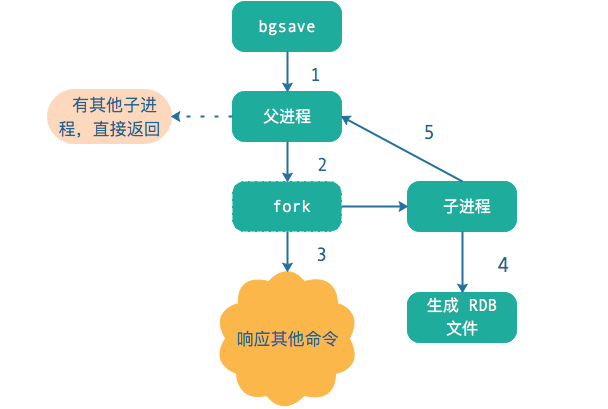
RDB 特点:
-
RDB 是一种快照模式,即保存的是 key-value 数据内容。
-
RDB 有 2 种持久方式,同步 save 模式 和 异步 bgsave 模式。由于 save 是同步的,所以可以保证数据一致性,而 bgsave 则不能。
-
save 可以在客户端显式触发,也可以在 shutdown 时自动触发;bgsave 可以在客户端显式触发,也可以通过配置由定时任务触发,也可以在 slave 节点触发。
-
save 导致 redis 同步阻塞,基本已经废弃。bgsave 则不会导致阻塞,但也有缺点:在 fork 时,需要增加内存服务器开销,因为当内存不够时,将使用虚拟内存,导致阻塞 Redis 运行。所以,需要保证空闲内存足够。
-
默认执行 shutdown 时,如果没有开启 AOF,则自动执行 bgsave。
-
每次的 RDB 文件都是替换的。
-
redis 会压缩 RDB 文件,使用 LZF 算法,让最终的 RDB 文件远小于内存大小,默认开启,但会消耗 CPU。
RDB 缺点:
1. 无法秒级持久化
2. 老版本 redis 无法兼容新版本 RDB
RDB 优点:
1. 文件紧凑,适合备份,全量复制场景。例如每 6 小时执行 bgsave,保存到文件系统之类的。
2. redis 加载 RDB 恢复数据远远快于 AOF
3、AOF
由于 RDB 的数据实时性问题,AOF 是目前 Redis 持久化的主流方式。
AOF 特点:
-
默认文件名是 appendonly.aof。和 RDB 一样,保存在配置中 dir 目录下。
-
AOF 相比较于 RDB,每次都会保存写命令,数据实时性更高。
-
AOF 由于每次都会记录写命令,文件会很大,因此需要进行优化,称之为“重写机制”(下面详细说)。
-
AOF 每次保存的写命令都放在一个缓冲区,根据不同的策略(下面详细说)同步到磁盘。
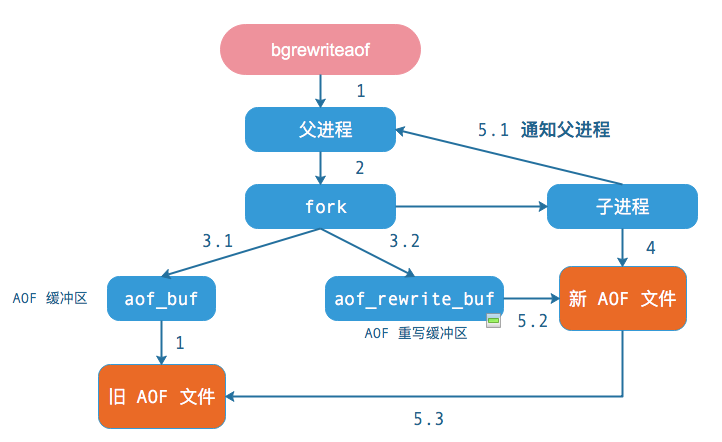
"重写机制" 细节:
-
fork 子进程(类似 bgsave)
-
主进程会写到2个缓冲区,一个是原有的 “AOF 缓存区”,一个是专门为子进程准备的 “AOF 重写缓冲区”;
-
子进程写到到新的 AOF 文件中,批量的,默认 32m;写完后通知主进程。
-
主进程把 “AOF 重写缓冲区” 的数据写到新 AOF 文件中。
-
将新的 AOF 文件替换老文件。
重写流程图:
缓冲区同步策略,由参数 appendfsync 控制,一共3种:
-
always:调用系统 fsync 函数,直到同步到硬盘返回;
严重影响 redis 性能。 -
everysec:先调用 OS write 函数, 写到缓冲区,然后 redis 每秒执行一次 OS fsync 函数。
推荐使用这种方式。 -
no: 只执行 write OS 函数,具体同步硬盘策略由 OS 决定;
不推荐,数据不安全,容易丢失数据。
4、持久化恢复
AOF 和 RDB 文件都可以用于服务器重启时的数据恢复,具体流程如下图: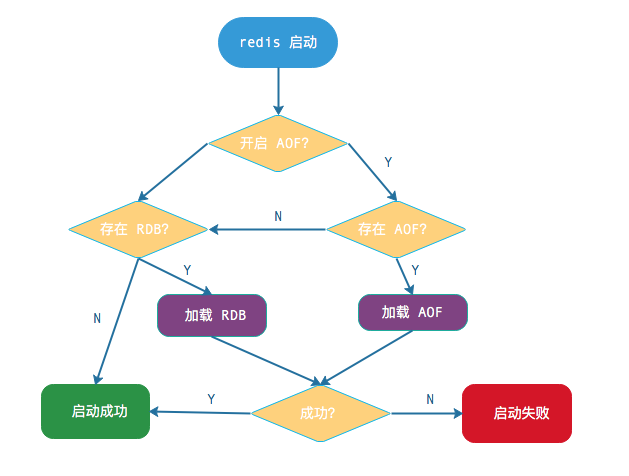
5、问题排查和性能优化
Redis 持久化是影响 Redis 性能的高发地,也是面试中常问的问题。
1. fork 操作
当 Redis 做 RDB 或者 AOF 重写时,必然要进行 fork 操作,对于 OS 来说,fork 都是一个重量级操作。而且,fork 还会拷贝一些数据,虽然不会拷贝主进程所有的物理空间,但会复制主进程的空间内存页表。对于 10GB 的 Redis 进程,需要复制大约 20MB 的内存页表,因此 fork 操作耗时 和 进程总内存量 息息相关,再加上,如果使用虚拟化技术,例如 Xen 虚拟机,fork 会更加耗时。
一个正常的 fork 耗时大概在 20ms 左右。为什么呢,假设一个 Redis 实例的 QPS 在 5 万以上,如果 fork 操作耗时在秒级,那么将拖慢几万条命令的执行,对生产环境影响明显。
我们可以在 Info stats 统计中查询 latest_fork_usec 指标获取最近一次 fork 操作耗时,单位微秒。
如何优化呢?
1. 优先使用物理机 或 高效支持 fork 的虚拟化技术,避免使用 Xen。
2. 控制 redis 实例最大内存,尽量控制在 10GB 以内。
3. 合理配置 Linux 内存分配策略,避免内存不足导致 fork 失败。
4. 降低 fork 的频率,如适度放宽 AOF 自动触发时机,避免不必要的全量复制。
2. 子进程开销
CPU
写入文件的过程是 CPU 密集的过程,通常子进程对单核 CPU 利用率接近 90%。
2. 不要和其他 CPU 密集型服务在一个机器上。
3. 如果部署了多个 Redis 实例,尽力保证同一时刻只有一个子进程执行重写工作。
内存
如果重写过程中存在内存修改操作,父进程负责创建所修改内存页的副本。这里就是内存消耗的地方。
如何优化呢?
1. 尽量保证同一时刻只有一个子进程在工作
2. 避免大量写入时做重写操作
硬盘
硬盘开销分析:子进程主要职责是将 RDB 或者 AOF 文件写入硬盘进行持久化,势必对硬盘造成压力,可通过工具例如 iostat,iotop 等,分析硬盘负载情况。
如何优化呢?
1. 不要和其他高负载硬盘的服务放在一台机器上,例如:MQ,存储等
2. AOF 重写时会消耗大量硬盘 IO,可以开启配置 no-appendfsync-on-rewrite,默认关闭。表示在 AOF 重写期间不做 fsync 操作
3. 当开启 AOF 的 Redis 在高并发场景下,如果使用普通机械硬盘,每秒的写速率是 100MB左右,这时,Redis 的性能瓶颈在硬盘上,建议使用 SSD
4. 对于单机配置多个 Redis 实例的情况,可以配置不同实例分盘存储 AOF 文件,分摊硬盘压力
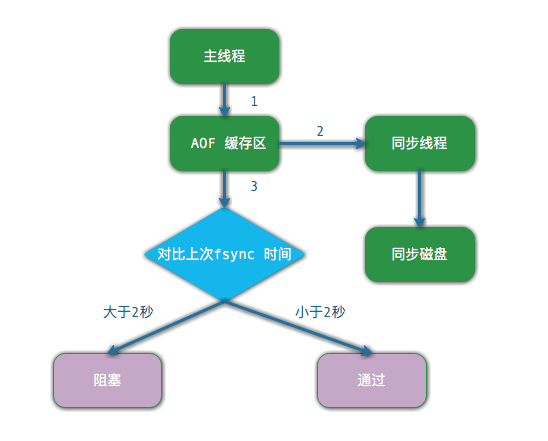
3. AOF 追加阻塞
当开启 AOF 持久化时,常用的同步硬盘的策略是“每秒同步” everysec,用于平衡性能 和 数据安全性,对于这种方式,redis 使用另一条线程每秒执行 fsync 同步硬盘,当系统资源繁忙时,将造成 Redis 主线程阻塞。
4. 单机多实例部署
Redis 单线程架构无法充分利用多核CPU,通常的做法是一台机器上部署多个实例,当多个实例开启 AOF 后,彼此之间就会产生 CPU 和 IO 的竞争。
如何解决呢?
让所有实例的 AOF 串行执行。我们通过 info Persistence 中关于 AOF 的信息写出 Shell 脚本,然后串行执行实例的 AOF 持久化。
整个过程如图:

通过不断判断 AOF 的状态,手动执行 AOF 重写,保证 AOF 不会存在竞争。具体的 Shell 编写以及 info 信息判断,可以查看下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号