redis-02 五种类型底层数据结构
redis有五种基本数据结构:字符串、hash、set、zset、list。但是你知道构成这五种结构的底层数据结构是怎样的吗? 今天我们来花费五分钟的时间了解一下。
1、string
这里不得不提动态字符串 SDS,即 ”simple dynamic string" 的缩写。redis 中所有场景中出现的字符串,基本都是由SDS来实现的。
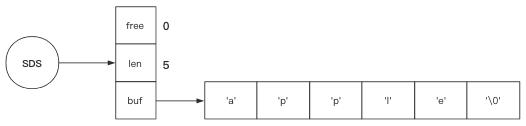
free:还剩多少空间; len:字符串长度; buf:存放的字符数组
空间预分配
为减少修改字符串带来的内存重分配次数,SDS 采用了 “一次管够” 的策略:
- 若修改之后 SDS 长度 < 1MB,则多分配现有 len长度 的空间
- 若修改之后 SDS 长度 >= 1MB,则扩充除了满足修改之后的长度外,额外多 1MB 空间
惰性空间释放
为避免缩短字符串时候的内存重分配操作,SDS 在数据减少时,并不立刻释放空间。

其中:embstr 和 raw 都是由 SDS 动态字符串构成的。
唯一区别是:raw 是分配内存的时候,redis object 和 SDS 各分配一块内存,而 embstr 是 redis object 和 raw 在一块儿内存中。
2、list(列表)

ziplist 称为 压缩列表;linkedlist 称为 双向列表;
在版本3.2之前,Redis 列表list使用两种数据结构作为底层实现:
- 压缩列表 ziplist
- 双向链表linkedlist
因为双向链表占用的内存比压缩列表要多,所以当创建新的列表键时,列表会优先考虑使用压缩列表,并且在有需要的时候,才从压缩列表实现转换到双向链表实现。
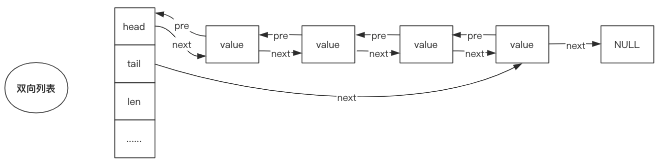
双向链表linkedlist
linkedlist是标准的双向链表,Node节点包含prev和next指针,可以进行双向遍历;
还保存了 head 和 tail 两个指针,因此,对链表的表头和表尾进行插入的复杂度都为 (1) —— 这是高效实现 LPUSH 、 RPOP、 RPOPLPUSH 等命令的关键。
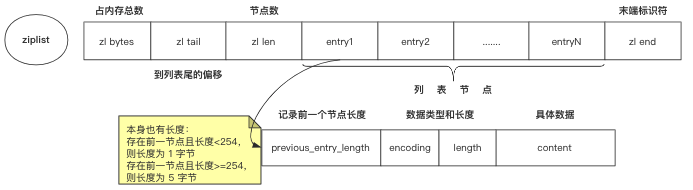
压缩列表 ziplist
它是为 Redis 节约内存而开发的。
ziplist 是由一系列特殊编码的内存块构成的列表(像内存连续的数组,但每个元素长度不同), 一个 ziplist 可以包含多个节点(entry)。
ziplist 将表中每一项存放在前后连续的地址空间内,每一项因占用的空间不同,而采用变长编码。由于内存是连续分配的,所以遍历速度很快。
redis3.2+ 之 list 的新实现 quickList
Redis 中的列表 list,在版本 3.2 之前,列表底层的编码是ziplist和linkedlist实现的,但是在版本3.2之后,重新引入 quicklist,列表的底层都由 quicklist 实现。
在版本3.2之前,当列表对象中元素的长度比较小或者数量比较少的时候,采用 ziplist 来存储,当列表对象中元素的长度比较大或者数量比较多的时候,则会转而使用双向列表 linkedlist 来存储。
这两种存储方式的优缺点
- 双向链表linkedlist便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝。
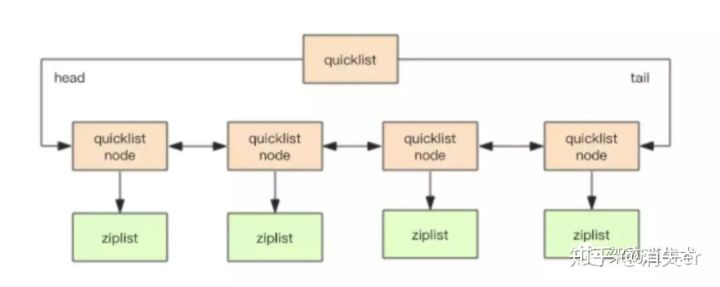
quickList
可以认为quickList,是ziplist和linkedlist二者的结合;quickList将二者的优点结合起来。
quickList是一个ziplist组成的双向链表。每个节点使用ziplist来保存数据。本质上来说,quicklist里面保存着一个一个小的 redisziplist。结构如下:
3、hash
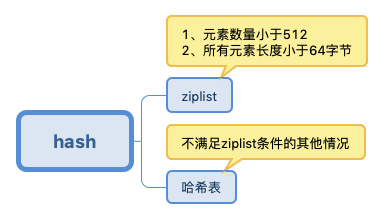
哈希表解决冲突的方法一般有两种,一种是:开放寻址法,一种是:拉链法。redis的哈希表解决冲突使用的是 拉链法。
整体结构如下图:
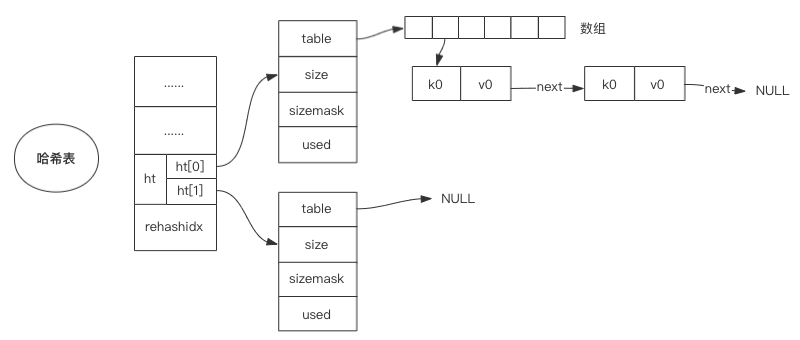
其中有两个关键的属性:ht 和 rehashidx。 ht是一个数组,有且只有俩元素 ht[0] 和 ht[1];其中,ht[0] 存放的是 redis 中使用的哈希表,而ht[1] 和 rehashidx 和 哈希表的 rehash有关。
且 ht[1] 后续的收缩和扩容要与 ht[0] 进行交换。且对应哈希表的扩容都是 2 倍增长的。
4、set
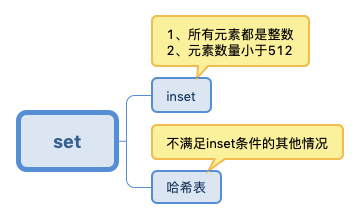
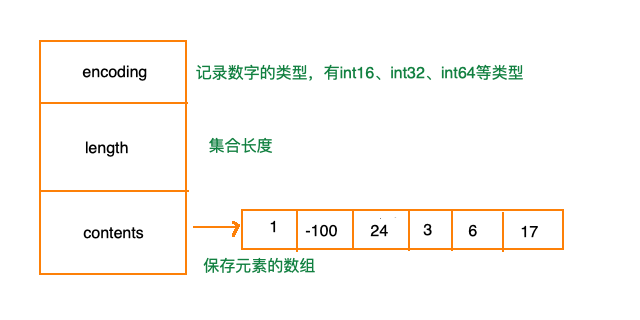
intset 即 整数集合是集合键的底层实现方式之一。类似于 ziplist 存储结构
5、zset

跳表这种数据结构长这样:

redis中把跳表抽象成如下所示:
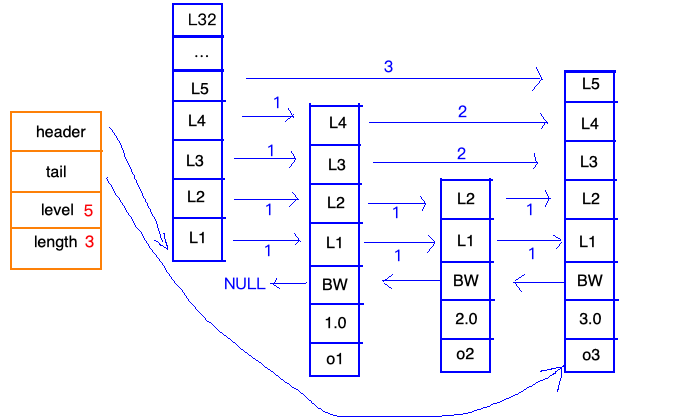
看这个图,左边“统筹”,右边实现。 统筹部分有以下几点说明:
- header: 跳表表头
- tail:跳表表尾
- level:层数最大的那个节点的层数
- length:跳表的长度
实现部分有以下几点说明:
- 表头:是链表的哨兵节点,不记录主体数据。
- 是个双向链表
- 分值是有顺序的
- o1、o2、o3 是节点所保存的成员,是一个指针,可以指向一个SDS值。
- 层级高度最高是32。没每次创建一个新的节点的时候,程序都会随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是“高度”
可参考微博:https://juejin.im/post/5de3e841f265da05d03826ca#heading-26

 浙公网安备 33010602011771号
浙公网安备 33010602011771号