YOLO V5
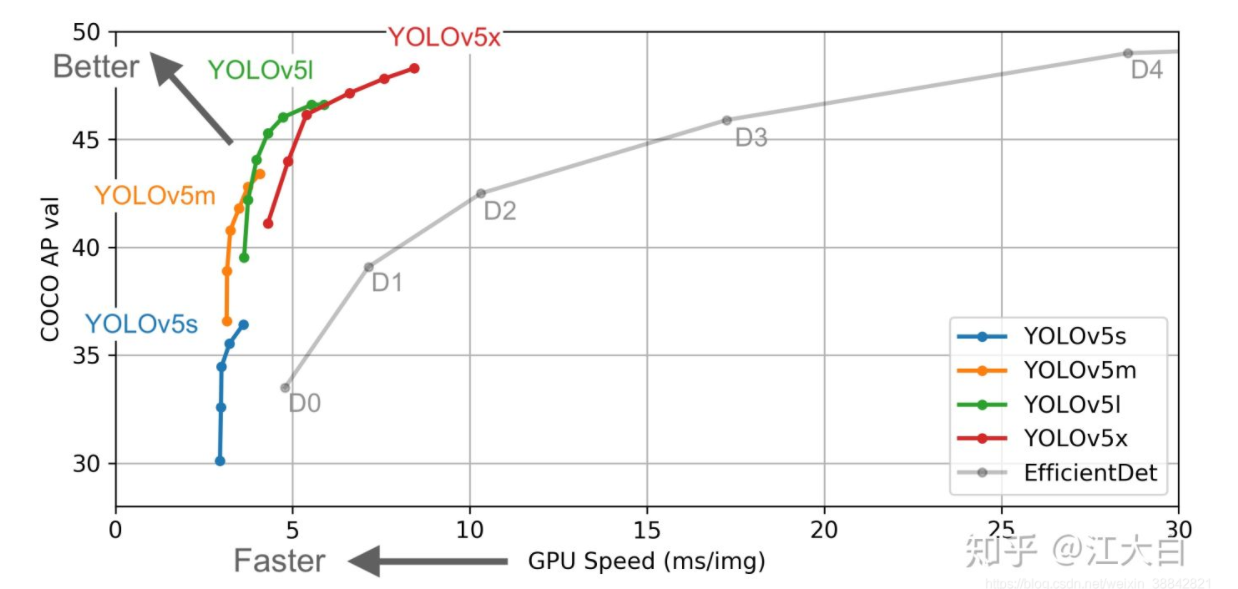
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。
YOLO v5四个版本的算法性能图
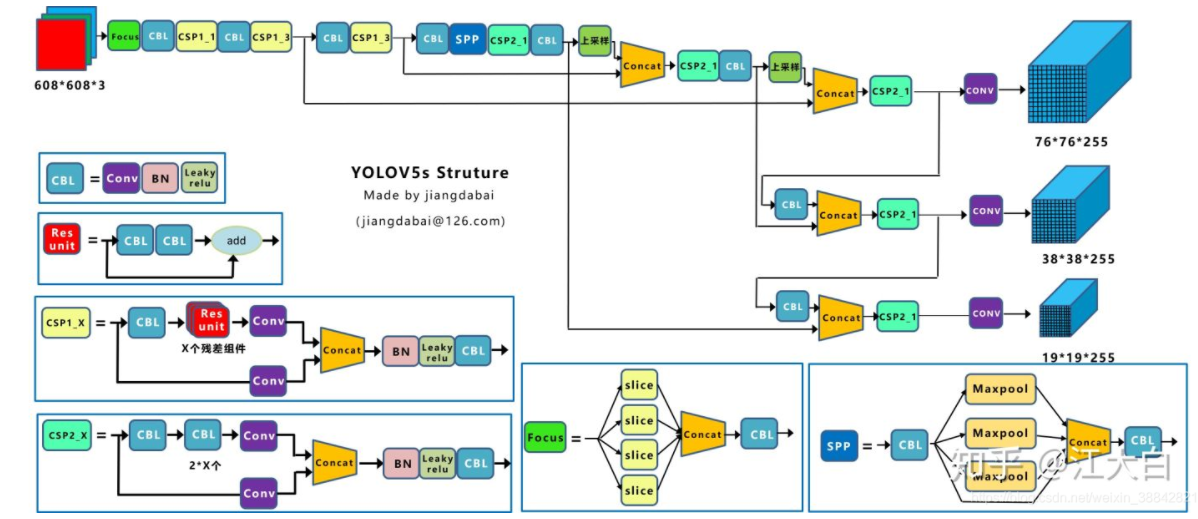
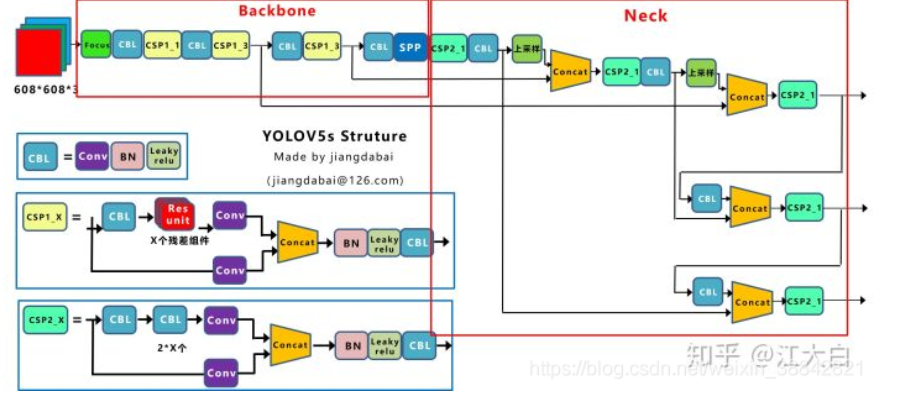
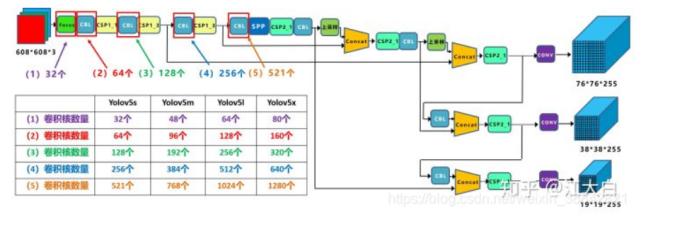
YOLO v5s的框架图
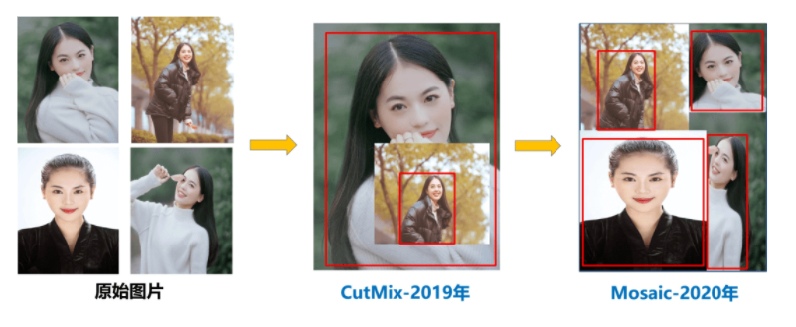
Mosaic数据增强
Mosaic是参考CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
1、每次读取四张图片。
2、分别对四张图片进行翻转、缩放、色域变化等,并且按照四个方向位置摆好。
3、进行图片的组合和框的组合
对于小目标的检测效果还是很不错的
自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但YOLOv5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中最佳锚框找值。
当然,如果计算锚框效果不是很好,也可以在代码中将西东计算锚框功能关闭,控制的代码中即train.py中上面一行代码,设计成FALSE,每次训练时,不会自动计算。
自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放。
Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

Focus结构
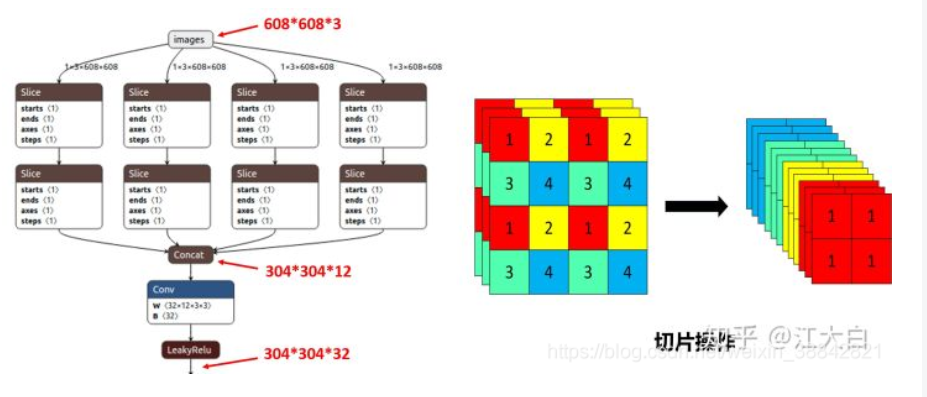
Focus是Yolov5新增的操作,右图就是将443的图像切片后变成2212的特征图。
以Yolov5s的结构为例,原始6086083的图像输入Focus结构,采用切片操作,先变成30430412的特征图,再经过一次32个卷积核的卷积操作,最终变成30430432的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加。
CSP结构
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
CSPNet(Cross Stage Partial Network):跨阶段局部网络,以缓解以前需要大量推理计算的问题。
- 增强了CNN的学习能力,能够在轻量化的同时保持准确性。
- 降低计算瓶颈。
- 降低内存成本。
CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。
CSPNet和PRN都是一个思想,将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。
neck部分
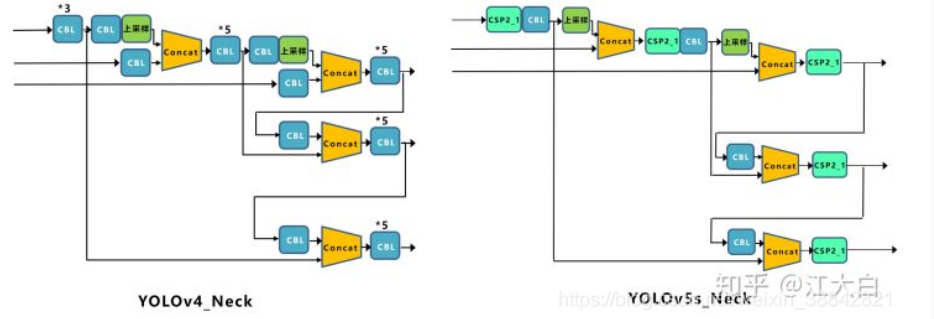
Yolov5的Neck和Yolov4中一样,都采用FPN+PAN的结构。
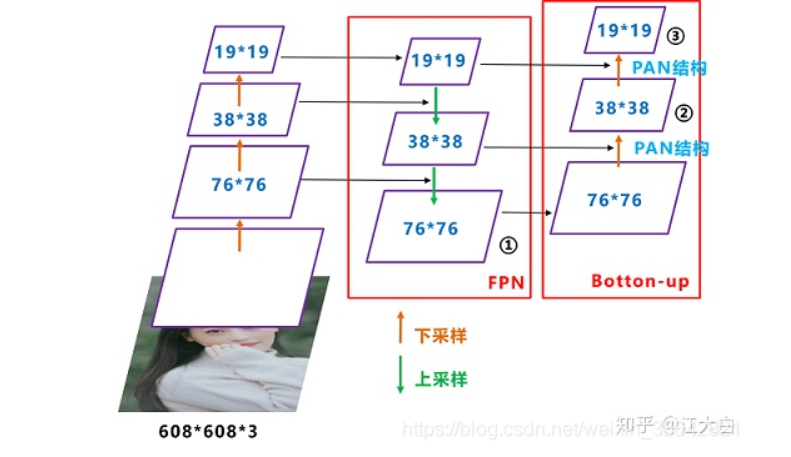
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
输出端
主要是IOU的不同计算方法,这一块要重点理解,对于目标检测的输出结果有很大的影响(重叠)
GIOU
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。
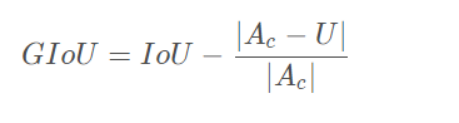
上面公式的意思是:先计算两个框的最小闭包区域面积 [公式] (通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
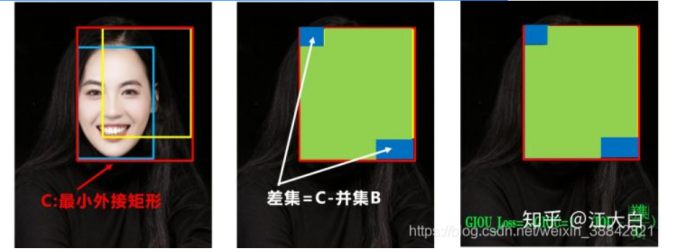
用图片来进行理解就是:
- 两个框的最小闭包区域面积 = 红色矩形面积
- IoU = 黄色框和蓝色框的交集 / 并集
- 闭包区域中不属于两个框的区域占闭包区域的比重 = 蓝色面积 / 红色矩阵面积
- GIoU = IoU - 比重
DIoU
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。
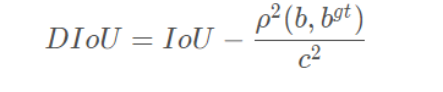
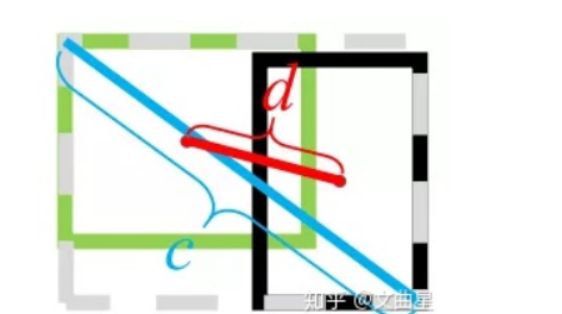
其中  分别代表了预测框和真实框的中心点,且 ρ 代表的是计算两个中心点间的欧式距离。c 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
分别代表了预测框和真实框的中心点,且 ρ 代表的是计算两个中心点间的欧式距离。c 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
优点:
- 与GIoU loss类似,DIoU loss(LDIoU=1−DIoU)在与目标框不重叠时,仍然可以为边界框提供移动方向。
- DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
- 对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快,而GIoU损失几乎退化为IoU损失。
- DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
CIOU
作者考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。
Yolov4中采用CIOU_Loss作为目标Bounding box的损失。
完整的 CIoU 损失函数定义:
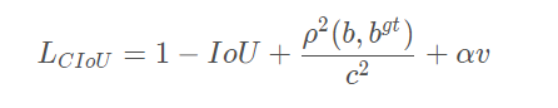
其中α 是权重函数,而 v vv 用来度量长宽比的相似性,定义为


nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。
因为CIOU_Loss中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。
所以Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中采用加权nms的方式。
不同的nms,会有不同的效果,采用了DIOU_nms的方式,在同样的参数情况下,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,确实会有一些改进。
比如下面黄色箭头部分,原本两个人重叠的部分,在参数和普通的IOU_nms一致的情况下,修改成DIOU_nms,可以将两个目标检出。
虽然大多数状态下效果差不多,但在不增加计算成本的情况下,有稍微的改进也是好的。
 Yolov5四种网络的深度
Yolov5四种网络的深度

Yolov5四种网络的宽度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号