


GoogleNet网络(纵横交错)
论文
该篇论文的作者在ILSVRC 2014比赛中提交的报告中使用了GoogLeNet,这是一个22层的深度网络。在这里面提出了一种新的叫做Inception的结构。该网络具有很大的depth和width,但是参数数量却仅为AlexNet的1/12。
《更深层的卷积》(Going deeper with convolutions)[2]。因为这篇论文的作者基本都来自于谷歌,所以文章提出的模型有时候又被叫作 GoogleNet。这篇论文拥有 8 千多次的引用数。
GoogleNet 不仅和 VGG 一样在把架构做“深”上下文章,而且在模型的效率上比 AlexNet 更加优秀。作者们利用了比 AlexNet 少 12 倍的参数,在更深的架构上达到了更好的效果。
简介
GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,论文说是为了向“LeNet”致敬,因此取名为“GoogLeNet”。
inception(也称GoogLeNet)是2014年Christian Szegedy提出的一种全新的深度学习结构, 在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果, 但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
创新
GoogleNet 创新的重点是在网络架构上。和 AlexNet 以及 VGG 都不同的是,GoogleNet 的作者们认为更加合适的网络架构不是简单地把相同的卷积层叠加起来,然后再把相同的全联通层叠加。如果我们需要更深的架构,必须从原理上对网络架构有一个不同的理解。作者们认为,网络结构必须走向“稀疏化”(Sparsity),才能够达到更深层次、更高效的目的。
那么,能否直接用稀疏结构来进行网络的架构呢?过去的经验表明,这条路并不那么直观。
- 第一,直接利用稀疏的结构所表达的网络结构效果并不好,
- 第二,这样做就无法利用现代的硬件,特别是 GPU 的加速功能。现代的 GPU 之所以能够高效地处理视觉以及其他一系列类似的问题,主要的原因就是快速的紧密矩阵运算。所以,直接使用稀疏结构有一定的挑战。
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,但是这样会带来一些缺陷:
- 参数太多,容易过拟合
- 网络越大计算复杂度越大,难以应用
- 网络越深,梯度越往后越容易消失
于是GoogLeNet针对这些问题给出了两个解决方案:
- 深度方面:层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,GoogLeNet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
- 宽度方面:采用了Inception结构,这是一种网中网(Network In Network)的结构,即原来的结点也是一个网络。
初步inception结构
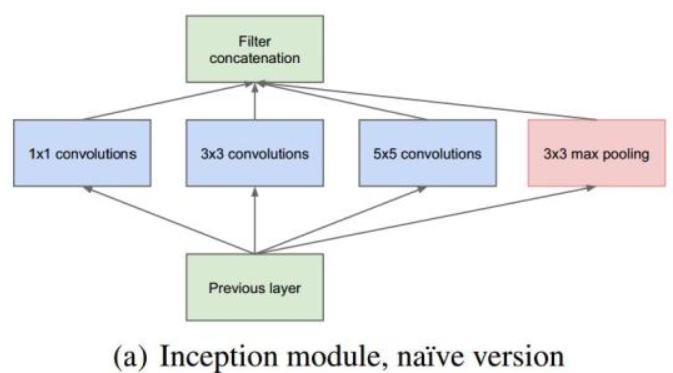
初始结构的主要思想是找出卷积视觉网络中的最优局部稀疏结构是如何被容易获得的稠密分量逼近和覆盖的。
用分层结构,分析最后一层的相关统计数据,并将其聚类成高相关的单元组。这些簇构成下一层的单元,并连接到上一层的单元。
当时的Inception体系结构仅限于1×1、3×3和5×5大小的过滤器。体系结构是所有这些层及其输出滤波器组的组合,这些滤波器组连接成一个输出向量,形成下一阶段的输入。
结构存在问题:即使是少量的5×5卷积,在具有大量滤波器的卷积层上也会非常昂贵,至少在这种简单的形式下是这样。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。这也就形成了以下改进后的inception结构。
改进inceptionv0结构
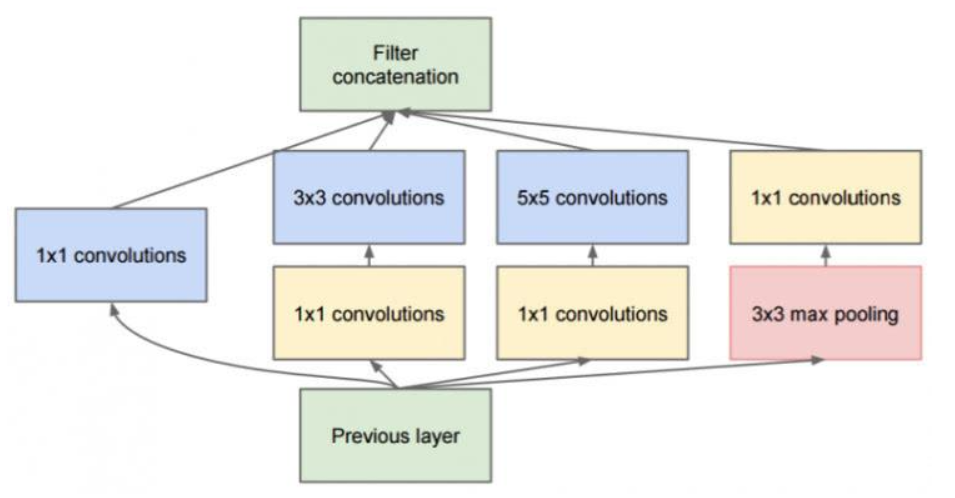
在分支2,3,4上加入了卷积核大小为1x1的卷积层,目的是为了降维(减小深度),减少模型训练参数,减少计算量。
在上述模块的基础上,为进一步降低网络参数量,Inception又增加了多个1×1的卷积模块。如图所示,这种1×1的模块可以先将特征图降维,再送给3×3和5×5大小的卷积核,由于通道数的降低,参数量也有了较大的减少。值得一提的是,用1×1卷积核实现降维的思想,在后面的多个轻量化网络中都会使用到。
Inception v1网络一共有9个上述堆叠的模块,共有22层,在最后的Inception模块处使用了全局平均池化。为了避免深层网络训练时带来的梯度消失问题,作者还引入了两个辅助的分类器,在第3个与第6个Inception模块输出后执行Softmax并计算损失,在训练时和最后的损失一并回传。
改进inception结构
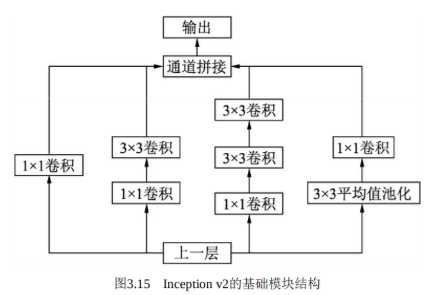
在Inception v1网络的基础上,随后又出现了多个Inception版本。 Inception v2进一步通过卷积分解与正则化实现更高效的计算,增加了 BN层,同时利用两个级联的3×3卷积取代了Inception v1版本中的5×5卷积,如图3.15所示,这种方式既减少了卷积参数量,也增加了网络的非线性能力
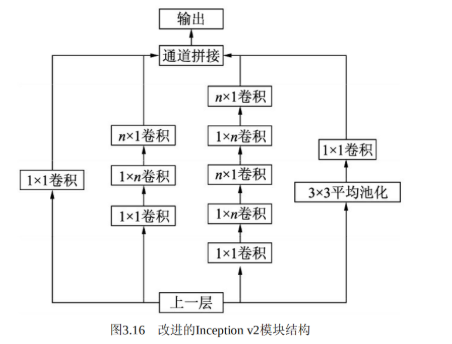
更进一步,Inceptionv2将n×n的卷积运算分解为1×n与n×1两个卷积,如图3.16所示,这种分解的方式可以使计算成本降低33%。
Inception v3在Inception v2的基础上,使用了RMSProp优化器,在辅助的分类器部分增加了7×7的卷积,并且使用了标签平滑技术。
Inception v4则是将Inception的思想与残差网络进行了结合,显著提升了训练速度与模型准确率,这里对于模块细节不再展开讲述。至于残差网络这一里程碑式的结构,正是由下一节的网络ResNet引出的。
GoogLeNet网络结构
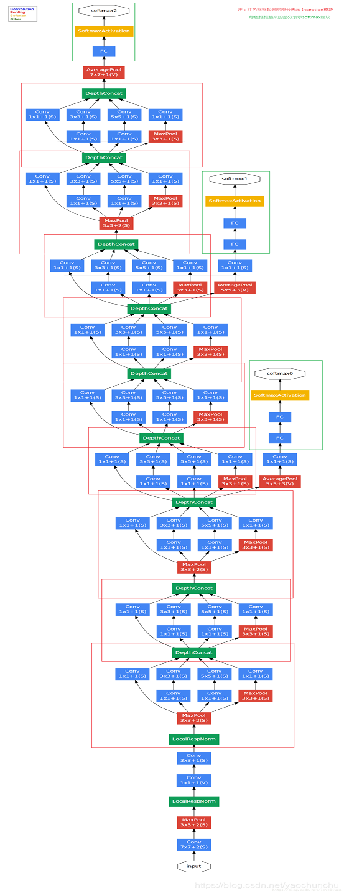
- 具有128个滤波器的1×1卷积,用于降维和校正线性。
- 具有1024个单元和整流线性**的完全连接层。
- 输出下降率为70%的辍学层。
- 一个全连接层,具有1024个单元和修正线性。
- 以softmax损耗为分类器的线性层(预测与主分类器,但在推断时移除)
网络主干右边的 两个分支 就是 辅助分类器,其结构一模一样。 在训练模型时,将两个辅助分类器的损失乘以权重(论文中是0.3)加到网络的整体损失上,再进行反向传播。
辅助loss函数
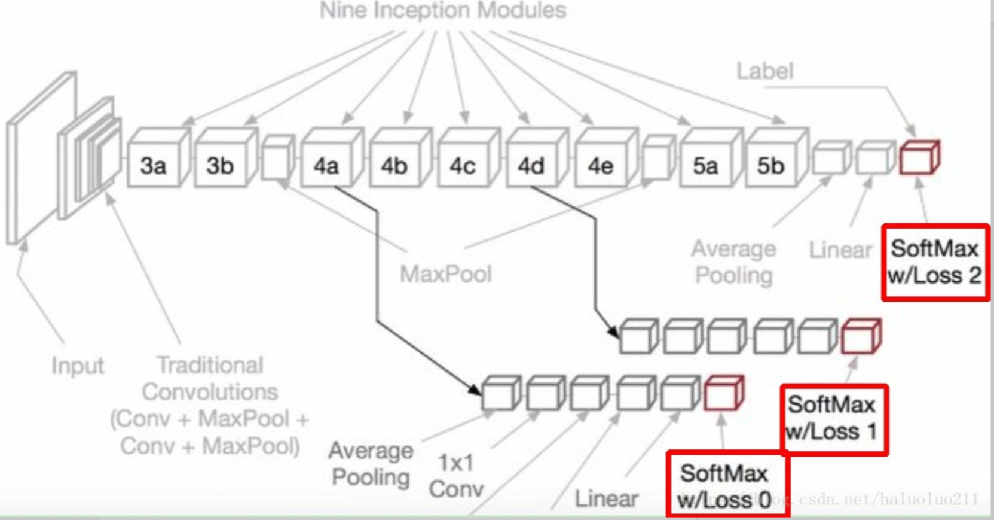
- 为防止网络中间部分不会「梯度消失」,作者引入了 2 个辅助分类器,它们本质上对 2 个 inception 模块的输出执行 softmax,并计算对同一个标签的 1 个辅助损失值。
- 辅助损失值纯粹是为训练构建,分类推断时将被忽略。辅助分类器促进了更稳定的学习和更好的收敛。辅助分类器往往在接近训练结束时,辅助分支网络开始超越没有任何分支的网络的准确性,达到了更高的稳定水平。
- 作用一:可以把他看做inception网络中的一个小细节,它确保了即便是隐藏单元和中间层也参与了特征计算,他们也能预测图片的类别,他在inception网络中起到一种调整的效果,并且能防止网络发生过拟合。
- 作用二:给定深度相对较大的网络,有效传播梯度反向通过所有层的能力是一个问题。通过将辅助分类器添加到这些中间层,可以期望较低阶段分类器的判别力。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是0.3)加到网络的整个损失上。
总结
- 使用1x1卷积(进一步融合各个通道的特征;降维减少计算量)
- 使用Inception结构(使用四种方式对特征进行提取;使用1x1卷积降维,减少计算量)
- 结构优化(辅助loss1,loss2,目的让低层特征也有很好的区分能力;使用全局最大池化和一层全连接层代替原来的两层全连接层)
- 批规一化(使用BN操作优化均值大小和方差使得训练模型时数据尽量贴近所有数据的分布,可以用来作为对抗梯度消失的一种手段。)

