VGGNet网络(走向深度)
简介
论文题目是《用于大规模图像识别的深度卷积网络》
(Very Deep Convolutional Networks for Large-Scale Image Recognition)[1]。
这篇文章的作者都来自于英国牛津大学的“视觉几何实验室” (Visual Geometry Group), 简称 VGG,所以文章提出的模型也被叫作 VGG 网络。到目前为止, 这篇论文的引用次数已经多达 1 万 4 千次。
AlexNet 在 2012 年发表之后,研究界对这个模型做了很多改进工作,使得这个模型得到了不断优化,特别是在 ImageNet 上的表现获得了显著提升。针对 AlexNet 模型的两个重要改进,分别是 VGG 和 GoogleNet。 VGG全称是Visual Geometry Group,因为是由Oxford的Visual Geometry Group提出的。AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。而VGG的作者们则选择了另外一个方向,即加深网络深度。 该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
主要贡献
- 一个重要贡献就是研究如何把之前的模型(例如 AlexNet)加深层次,从而能够拥有更好的模型泛化能力,最终实现更小的分类错误率。
- 为了更好地理解这篇文章的贡献,我们来回忆一下 AlexNet 的架构。 AlexNet 拥有 8 层神经网络,分别是 5 层卷积层和 3 层全联通层。 AlexNet 之所以能够有效地进行训练,是因为这个模型利用了“线性整流函数”(ReLu)、数据增强(Data Augmentation)以及 Dropout 等手段。这些方法让 AlexNet 能够达到 8 层。
- 从理论上看,神经网络应该是层数越多,泛化能力越好。而且在理论上,一个 8 层的神经网络完全可以加到 18 层或者 80 层。但是在现实中,梯度消失和过拟合等情况让加深神经网络变得非常困难。在这篇论文中,VGG 网络就尝试从 AlexNet 出发,看能否加入更多的神经网络层数,来达到更好的模型效果。
创新
总体来说,VGG 对卷积层的“过滤器”(Filter)进行了更改,达到了 19 层的网络结构。从结果上看,和 AlexNet 相比,VGG 在 ImageNet 上的错误率要降低差不多一半。可以说,这是第一个真正意义上达到了“深层”的网络结构。
简单来说,就是在卷积层中仅仅使用“3*3”的“接受域”(Receptive Field),使得每一层都非常小。我们可以从整个形象上来理解,认为这是一组非常“瘦”的网络架构。在卷积层之后,是三层全联通层以及最后一层进行分类任务的层。一个细节是,VGG 放弃了我们之前介绍的 AlexNet 中引入的一个叫“局部响应归一化”(Local Response Normalization)的技术,原因是这个技巧并没有真正带来模型效果的提升。 VGG 架构在训练上的一个要点是先从一个小的结构开始,我们可以理解为首先训练一个 AlexNet,然后利用训练的结果来初始化更深结构的网络。作者们发现采用这种“初始训练”(Pre-Training)的办法要比完全从随机状态初始化模型训练得更加稳定。
VGG网络结构
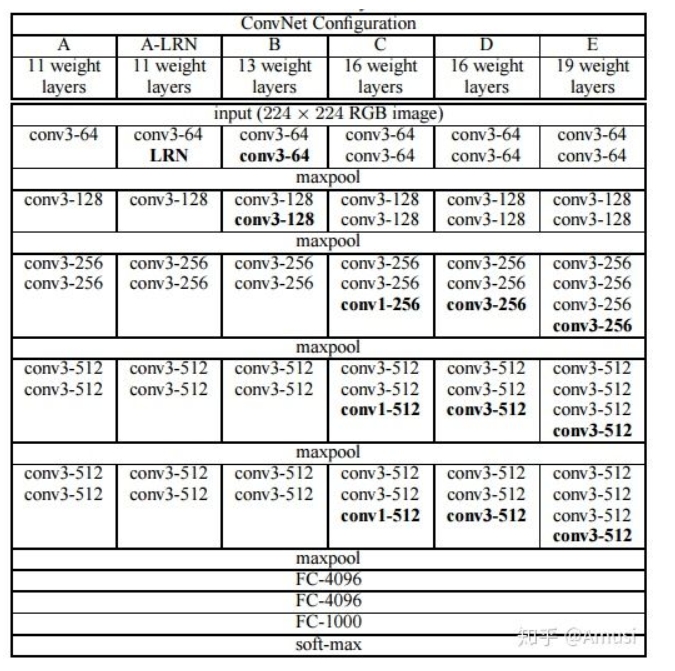
- - VGG16包含了16个隐藏层(13个卷积层和3个全连接层)
- - VGG19包含了19个隐藏层(16个卷积层和3个全连接层)
- - VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling
- - 如果你想看到更加形象化的VGG网络,可以使用经典卷积神经网络(CNN)结构可视化工具来查看高清无码的VGG网络
VGGNet网络结构组成如图3.12所示,一共有6个不同的版本,最常 用的是VGG16。从图中可以看出,VGGNet采用了五组卷积与三个 全连接层,最后使用Softmax做分类。VGGNet有一个显著的特点:每次 经过池化层(maxpool)后特征图的尺寸减小一倍,而通道数则增加一 倍(最后一个池化层除外)。
- A:没啥特别的。 A-LRN:加了LRN,这是AlexNet里提出来的,不需要怎么了解,基本很少使用了。
- B:加了两个卷积层。
- C: 进一步叠加了3个卷积层,但是加的是1 * 1的kernel。
- D:将C中1 * 1的卷积核替换成了3 * 3的,即VGG16。
- E:在D的基础上进一步叠加了3个3*3卷积层,即VGG19。
固定S:针对单尺寸图片进行训练。 Scale jittering:即对图片采用不同的Scale进行缩放,
VGG网络结构
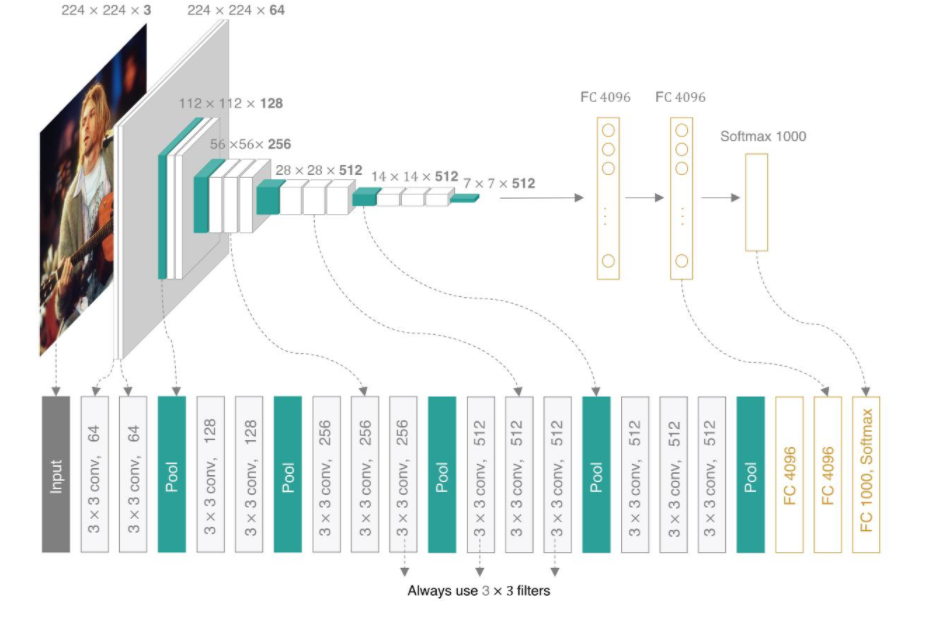
AlexNet中有使用到5×5的卷积核,而在VGGNet中,使用的卷积核基本都是3×3,而且很多地方出现了多个3×3堆叠的现象,这种结构的优点在于,首先从感受野来看,两个3×3的卷积核与一个5×5的卷积核是一样的; 3个3 * 3卷积叠加得到的理论感受野和一个7 * 7卷积的理论感受野是相同的。 因为每个卷积层后面都会跟着一个ReLU,3个3 * 3卷积就会有3个ReLU,但是一个7 * 7卷积只有一个,所以这么做可以使得模型的非线性拟合能力更强。减少了参数数量。
总结
- (1)层数深使得特征图更宽,更加适合于大的数据集,该网络可以解决1000类图像分类和定位问题。
- (2)卷积核的大小影响到了参数量,感受野,前者关系到训练的难易以及是否方便部署到移动端等,后者关系到参数的更新、特征图的大小、特征是否提取的足够多、模型的复杂程度。
- (3)池化层:从AlexNet的kernel size为33,stride为2的max-pooling改变为kernel size均为22,stride为2的max-pooling,小的池化核能够带来更细节的信息捕获
网络深,卷积核小,池化核小(与AlexNet的33池化核相比,VGG全部用的是22的池化层) 全连接转卷积。
VGG模型以较深的网络结构,较小的卷积核和池化采样域,使得其能够在获得更多图像特征的同时控制参数的个数,避免过多的计算量以及过于复杂的结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号