AlexNet网络(开山之作)
ALexNet介绍
ALexNet来源论文 《ImageNet Classification with Deep Convolutional Neural Networks》 这篇文章是深度学习的祖师爷Geoffrey Hinton的团队所写的论文, 第一作者是Alex Krizhevsky,所以该网络名称为AlexNet,其是2012年ImageNet竞赛冠军获得者。该文章的重要意义在于其在ImageNet比赛中以巨大的优势击败了其它非神经网络的算法,在此之前,神经网络一直处于不被认可的状态。
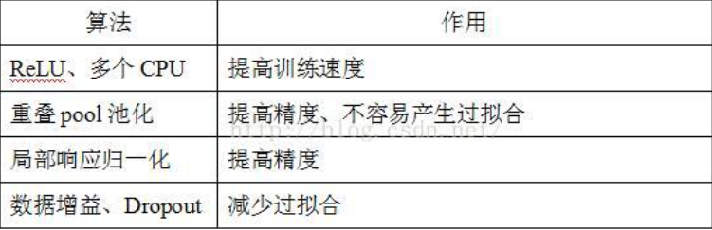
AlexNet由Alex Krizhevsky于2012年提出,夺得2012年ILSVRC比赛的冠军,top5预测的错误率为16.4%,远超第一名。 AlexNet采用8层的神经网络,5个卷积层和3个全连接层(3个卷积层后面加了最大池化层),包含6亿3000万个链接,6000万个 参数和65万个神经元。
在论文中内容和贡献
1、有大量的样本防止网络过拟合;
2、使用卷积和池化减少了参数量;
3、使用了反向传播得以训练参数;
4、使用了ReLU激活函数加速迭代;
5、使用了dropout防止网络过拟合;
6、使用了数据增强技术;
7、使用了GPU加速迭代。
这篇论文开启了深度学习在计算机视觉领域广泛应用的大门。通过这篇论文,我们看到了深度学习模型在重要的计算机视觉任务上取得了非常显著的效果。 具体来说,在 ImageNet 2012 年的比赛中,文章提到的模型比第二名方法的准确度要高出十多个百分点。能够达到这个效果,得益于在模型训练时的一系列重要技巧。这篇论文训练了到当时为止最大的卷积神经网络,而这些技巧使得训练大规模实用级别的神经网络成为可能。
创新点
- 成功使用ReLU作为CNN的激活函数,验证了其效果在较深的网络中超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
- 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合,一般在全连接层使用,在预测的时候是不使用Dropout的,即Dropout为1.
- 在CNN中使用重叠的最大池化(步长小于卷积核)。此前CNN中普遍使用平均池化,使用最大池化可以避免平均池化的模糊效果。
- 同时重叠效果可以提升特征的丰富性。 提出LRN(Local Response Normalization,即局部响应归一化)层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 使用CUDA加速神经网络的训练,利用了GPU强大的计算能力。
线性整流函数(ReLU)激活函数
- 在进行深层神经网络的时候,使用sigmoid与tanh函数作为激活函数,由于这两个激活函数都含有饱和区,会导致产生梯度爆炸和梯度消失。
- 反而而使用ReLU函数作为激活函数会缓解梯度消失和梯度爆炸这两个问题。 ReLU是线性的,且导数始终为1,计算量大大减少,收敛速度会比Sigmoid/tanh快很多。从而加快训练的速度。 但因为表达式中还有各层的权重,所以ReLU没有彻底解决梯度消失问题。
重叠池化(Overlapping Pooling)
- 一般的池化(Pooling)是不重叠的,池化区域的窗口大小与步长相同。
- 在AlexNet中使用的池化(Pooling)却是可重叠(Overlapping)的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。
- AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。
采用重叠池化的优点:
- 不仅可以提升预测精度,同时一定程度上可以减缓过拟合。
- 相比于正常池化(步长s=2,窗口z=2) 重叠池化(步长s=2,窗口z=3) 可以减少top-1, top-5分别为0.4% 和0.3%;
- 重叠池化可以避免过拟合。
防止过拟合
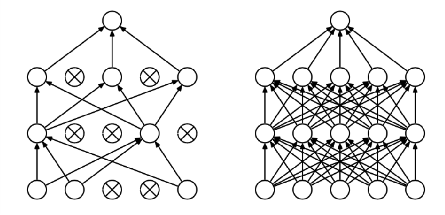
在AlexNet中防止过拟合的方法有两种,一种是dropout、一种是数据增强
AlexNet最后2个全连接层中使用了Dropout,因为全连接层容易过拟合,而卷积层不容易过拟合。
dropout:
- 有效的防止了过拟合,随机删除网络中的一些隐藏神经元,保持输入输出神经元不变;
- 使用这个函数之后,前向和后向不会受到影响; 相对于训练大量模型耗费大量时间,dropout在AlexNet中只需花费2倍的训练时间。
- 引入稀疏性。因为部分神经元被删除,原来有些特征可能会依赖于固定关系的隐含节点的共同作用,
- 通过Dropout的话,就有效地阻止了某些特征在其他特征存在下才有效果的情况
数据增强:
- 最简单和最常用的方法是在不改变图片核心元素(即不改变图片的分类)的前提下对图片进行一定的变换,
- 比如在垂直和水平方向进行一定的唯一,翻转等。如果没有数据增强,模型会陷入过拟合中,使用数据增强可以增大模型的泛化能力。
LRN局部响应归一化
局部响应归一化(Local Response Normalization,LRN),提出于2012年的AlexNet中。首先要引入一个神经生物学的概念:侧抑制(lateral inhibitio),即指被激活的神经元抑制相邻的神经元。LRN仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制)。归一化(normaliazation)的目的就是“抑制”,LRN就是借鉴这种侧抑制来实现局部抑制,尤其是我们使用RELU的时候,这种“侧抑制”很有效 ,因而在Alexnet里使用有较好的效果。
优点有以下两点:
- 归一化有助于快速收敛;
- 对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN一般是在激活、池化后进行的一中处理方法。 LRN函数类似DROPOUT和数据增强作为relu激励之后防止数据过拟合而提出的一种处理方法。这个函数很少使用,基本上被类似DROPOUT这样的方法取代
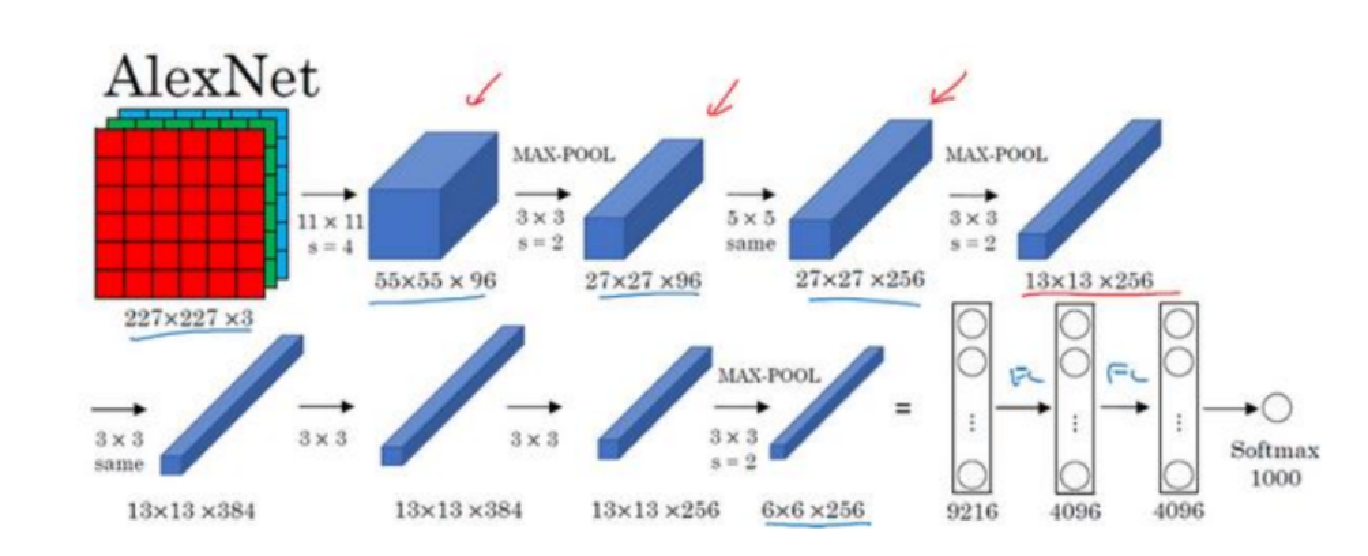
该网络总共有8层网络,前五层网络是卷积层,后3层网络为全连接层
该网络总共有8层,前5层为卷积层,后3层为全连接层,输入为224 × 224 × 3 大小的RGB图片,池化层都是用的最大池化,最后的输出为一个1000 个分类的softmax层。
- 第一个卷积层用96 9696个大小为11 × 11 × 3 的步长为4 44的卷积核对224 × 224 × 3 的输入图像进行卷积操作然后最大池化;
- 第二个卷积层用256 256256个大小为5 × 5 × 48 的步长为1 的卷积核对第一个卷积层的输出进行卷积操作然后最大池化;
- 第三个卷积层用384 384384个大小为3 × 3 × 256 的步长为1 的卷积核;
- 第四个卷积层用384 384384个大小为3 × 3 × 192 的步长为1 的卷积核;
- 第五个卷积层用256 256256个大小为3 × 3 × 192 的步长为1 的卷积核对第四个卷积层的输出进行卷积操作然后最大池化;
- 第六个全连接层有4096个神经元;
- 第七个全连接层有4096个神经元;
- 最后一层是输出层,为1000个分类的softmax层。 总共有6000万个参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号