南大ics-pa/PA1.1过程及感想
1.1
一、在红白模拟器上运行超级马里奥游戏
1、将游戏rom文件mario.nes移至~/ics2022/fceux-am/nes/rom文件下,并回到~/ics2022/fceux-am下执行make ARCH=native run mainargs=mario进行编译注意:在~/ics2022/fceux-am/nes/rom下放置ROM文件之后要返回到~/ics2022/fceux-am下再执行编译make ARCH=native run mainargs=mario !!!
(直接在/rom文件夹下编译,会出现make: *** No rule to make target 'run'. Stop.报错,因为Makefile文件在~/ics2022/fceux-am下,这错误真低级。。。)
执行make ARCH=native run mainargs=mario,效果如下:
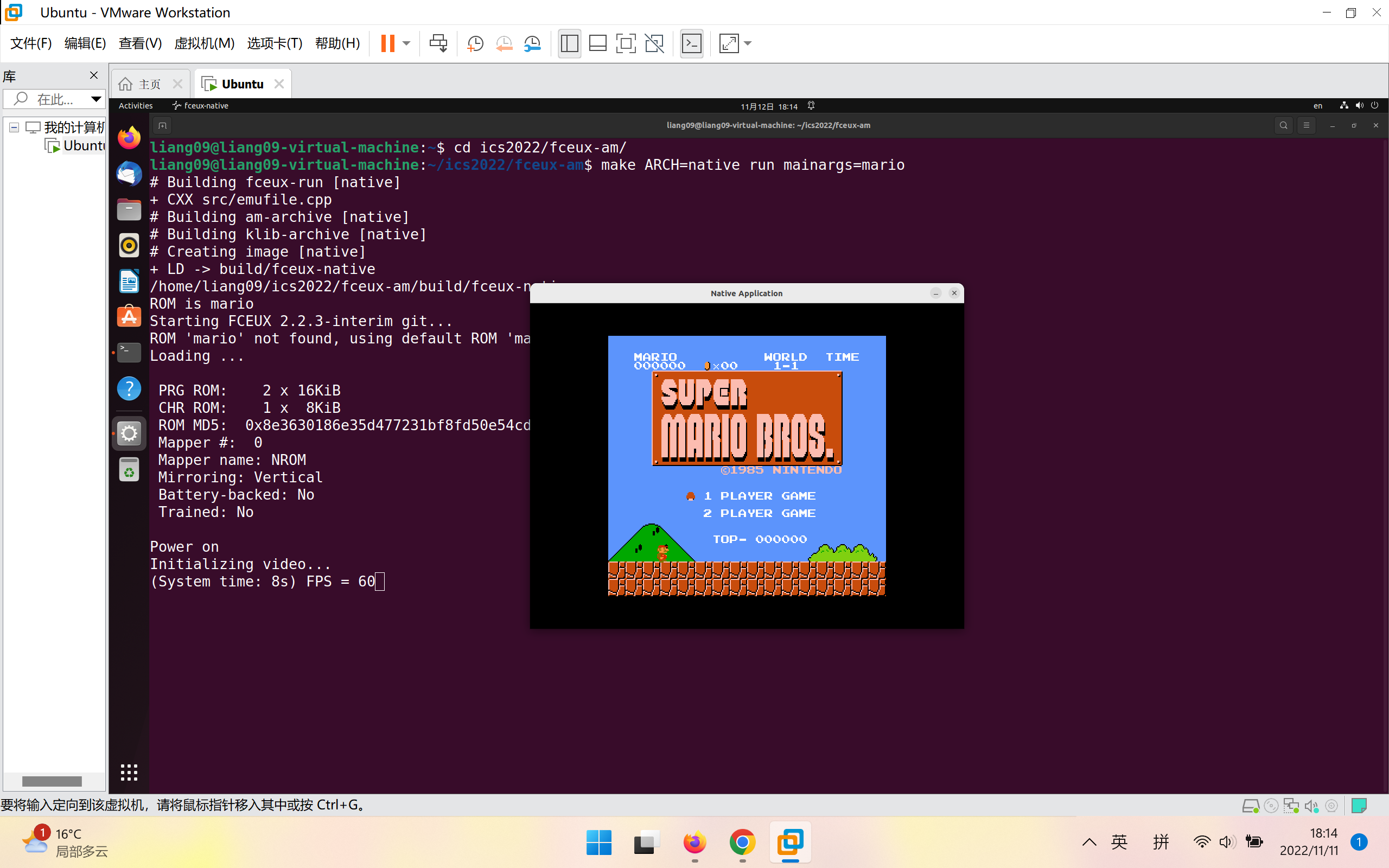
可以体验在计算机上玩super mario了!
2、通过lscpu命令可以显示系统CPU个数为4,之后在make命令后面添加-4可使4个线程调度到4个CPU上同时执行, 达到加速的效果。在命令前面加上time可以显示编译的时间,4个CPU同时执行确实会快许多。
3、ccache:
可以将编译之后的文件添加到ccache里面,下次编译的时候如果发现源文件没有变化, 就直接取出之前的目标文件作为编译结果, 从而跳过编译步骤来提高速度。
需要在.bashrc文件中改变PATH环境变量将which gcc的输出变为/usr/lib/ccache/gcc,在.bashrc文件下面加上一行命令:
export PATH="/usr/lib/ccache:$PATH"
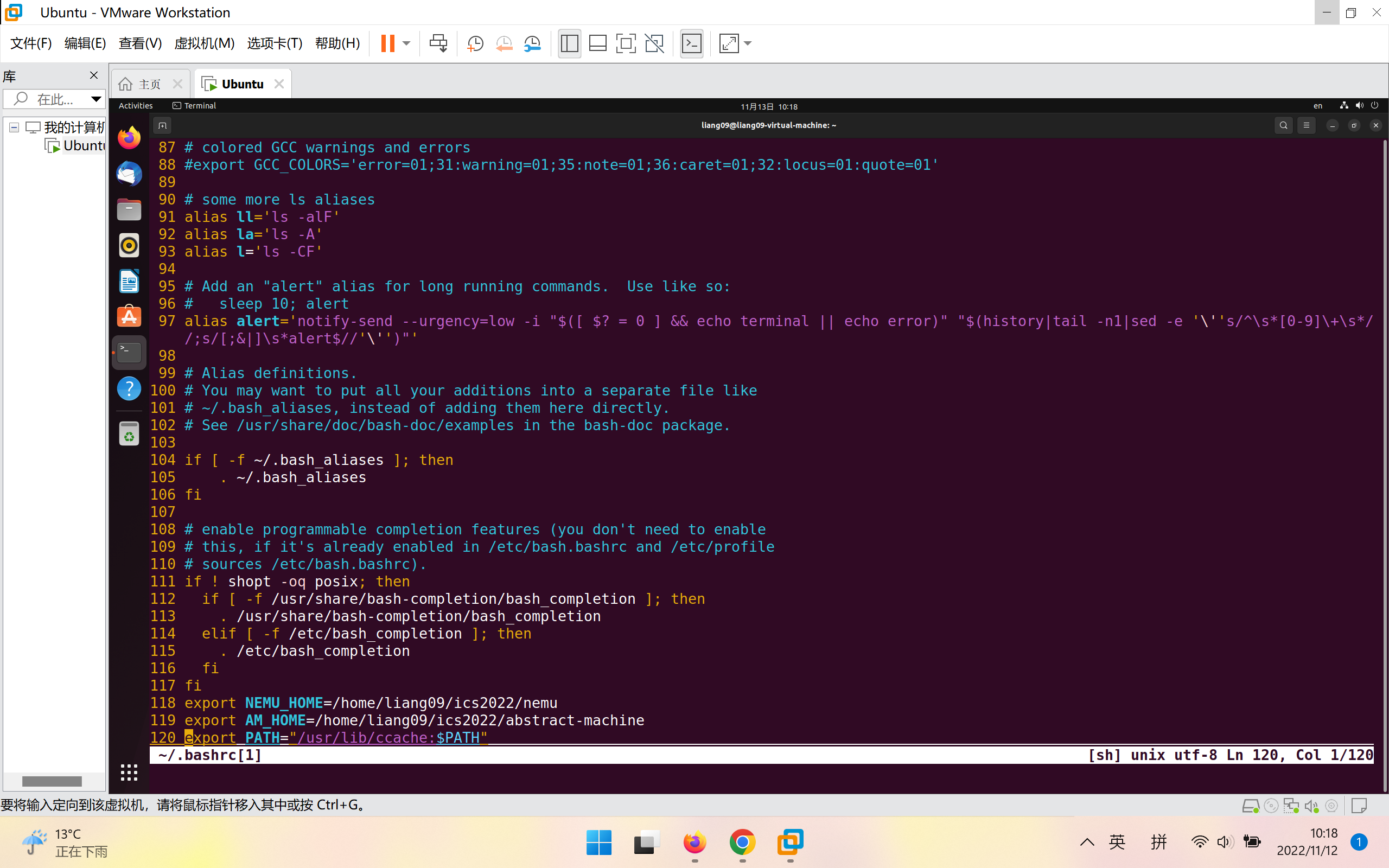
之后which gcc输出就变为/usr/lib/ccache/gcc了
退出并执行source ~/.bashrc
之后执行make clean命令清除编译结果, 然后重新编译并统计时间。这次编译时间反而比之前要更长一些, 这是因为除了需要开展正常的编译工作之外, ccache还需要花时间把目标文件存起来. 接下来再次清除编辑结果, 重新编译并统计时间, 第二次编译的速度有了非常明显的提升! 这说明ccache确实跳过了完全重复的编译过程, 发挥了加速的作用. 如果和多线程编译共同使用, 编译速度还能进一步加快!
二、一点疑惑:为什么github上面自己的远程仓库少了文件?
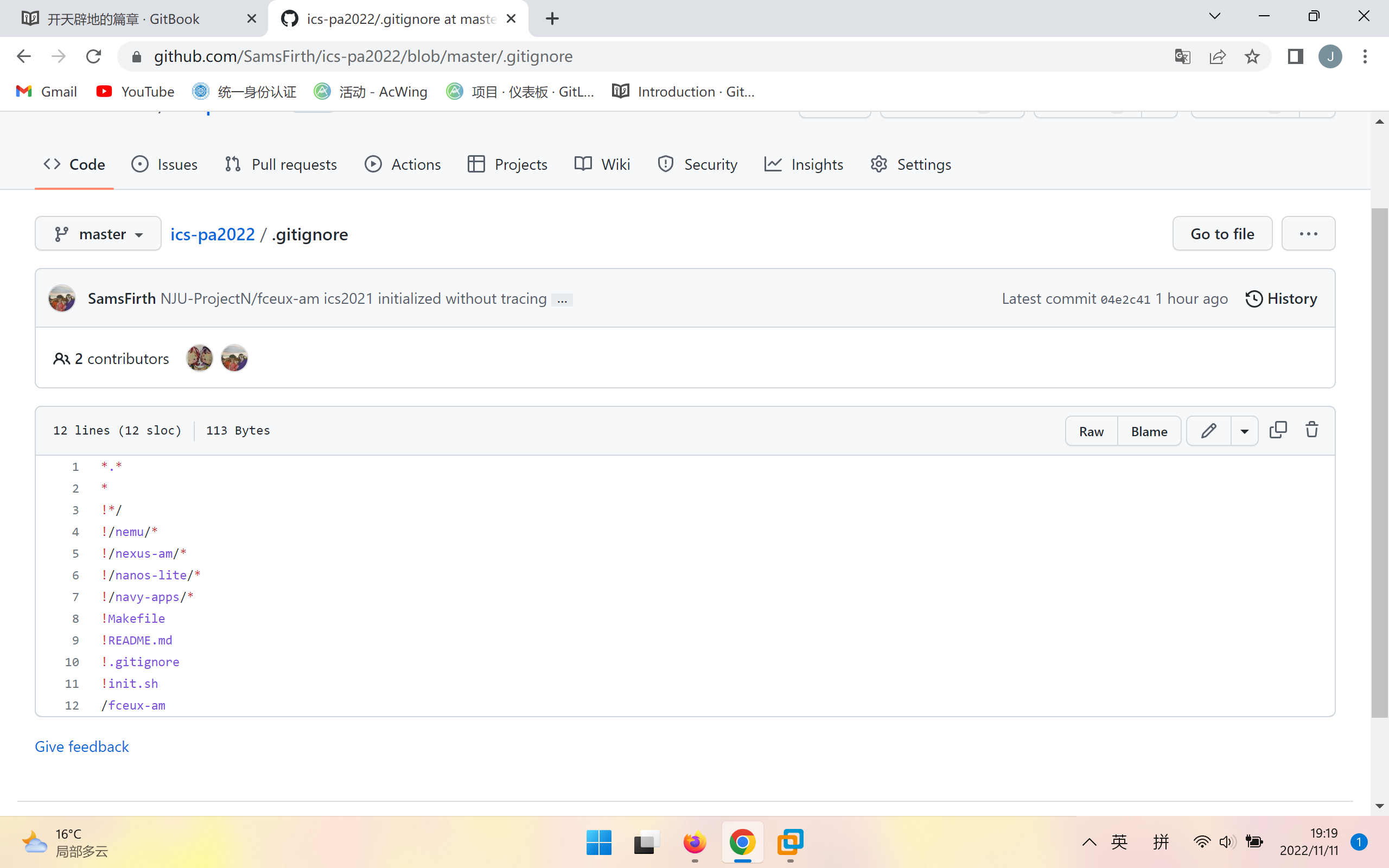
注意到执行git push之后添加mario游戏的fceux-am文件夹无法在github中显示,原来是在.gitignore文件中默认已有fceux-am的名字,注意到.gitignore文件中的文件将不会被上传到远程仓库。考虑了一下还是决定不做修改好了,毕竟是作者设置的。
1.2
一、计算机和程序都是状态机!!!
1、计算机是一个数组逻辑电路,可以把计算机划分成两部分, 一部分由所有时序逻辑部件(存储器, 计数器, 寄存器)构成, 另一部分则是剩余的组合逻辑部件(如加法器等)。在每个时钟周期到来的时候, 计算机根据当前时序逻辑部件的状态, 在组合逻辑部件的作用下, 计算出并转移到下一时钟周期的新状态。计算机正是通过执行指令的方式来改变自身状态的, 所以在状态机模型里面, 指令可以看成是计算机进行一次状态转移的输入激励。
2、通过状态机的视角来解释"程序在计算机上运行"的本质: 给定一个程序, 把它放到计算机的内存中, 就相当于在状态数量为N的状态转移图中指定了一个初始状态, 程序运行的过程就是从这个初始状态开始, 每执行完一条指令, 就会进行一次确定的状态转移. 也就是说, 程序也可以看成一个状态机! 这个状态机是上文提到的大状态机(状态数量为N)的子集.
3、两个互补的视角来看待同一个程序:
- 一个是以代码(或指令序列)为表现形式的静态视角, 大家经常说的"写程序"/"看代码", 其实说的都是这个静态视角. 这个视角的一个好处是描述精简, 分支, 循环和函数调用的组合使得我们可以通过少量代码实现出很复杂的功能. 但这也可能会使得我们对程序行为的理解造成困难.
- 另一个是以状态机的状态转移为运行效果的动态视角, 它直接刻画了"程序在计算机上运行"的本质. 但这一视角的状态数量非常巨大, 程序代码中的所有循环和函数调用都以指令的粒度被完全展开, 使得我们难以掌握程序的整体语义. 但对于程序的局部行为, 尤其是从静态视角来看难以理解的行为, 状态机视角可以让我们清楚地了解相应的细节.
1.3
一、框架代码:NEMU主要由4个模块构成: monitor, CPU, memory, 设备
1、项目结构:
ics2022
├── abstract-machine # 抽象计算机
├── am-kernels # 基于抽象计算机开发的应用程序
├── fceux-am # 红白机模拟器
├── init.sh # 初始化脚本
├── Makefile # 用于工程打包提交
├── nemu # NEMU
└── README.md2、为了支持不同的ISA, 框架代码把NEMU分成两部分: ISA无关的基本框架和ISA相关的具体实现. NEMU把ISA相关的代码专门放在nemu/src/isa/目录下, 并通过nemu/include/isa.h提供ISA相关API的声明. 这样以后, nemu/src/isa/之外的其它代码就展示了NEMU的基本框架
体现抽象的思想: 框架代码将ISA之间的差异抽象成API, 基本框架会调用这些API, 从而无需关心ISA的具体细节!
二、配置系统、构建项目(这部分不太懂,所有有的地方就摘抄较多了)
1、kconfig
NEMU中的配置系统位于nemu/tools/kconfig, 它来源于GNU/Linux项目中的kconfig
在"配置描述文件"中, 开发者可以描述:
- 配置选项的属性, 包括类型, 默认值等
- 不同配置选项之间的关系
- 配置选项的层次关系
目前我们只需要关心配置系统生成的如下文件:
nemu/include/generated/autoconf.h, 阅读C代码时使用nemu/include/config/auto.conf, 阅读Makefile时使用
2、Makefile
(1)与配置系统关联
kconfig定义了一套简单的语言, 开发者可以使用这套语言来编写"配置描述文件". 在"配置描述文件"中, 开发者可以描述:
- 配置选项的属性, 包括类型, 默认值等
- 不同配置选项之间的关系
- 配置选项的层次关系
(2)通过文件列表(filelist)决定最终参与编译的源文件
在nemu/src及其子目录下存在一些名为filelist.mk的文件, 它们会根据menuconfig的配置对如下4个变量进行维护:
SRCS-y- 参与编译的源文件的候选集合SRCS-BLACKLIST-y- 不参与编译的源文件的黑名单集合DIRS-y- 参与编译的目录集合, 该目录下的所有文件都会被加入到SRCS-y中DIRS-BLACKLIST-y- 不参与编译的目录集合, 该目录下的所有文件都会被加入到SRCS-BLACKLIST-y中
如图为nemu/src下filelist.mk的内容
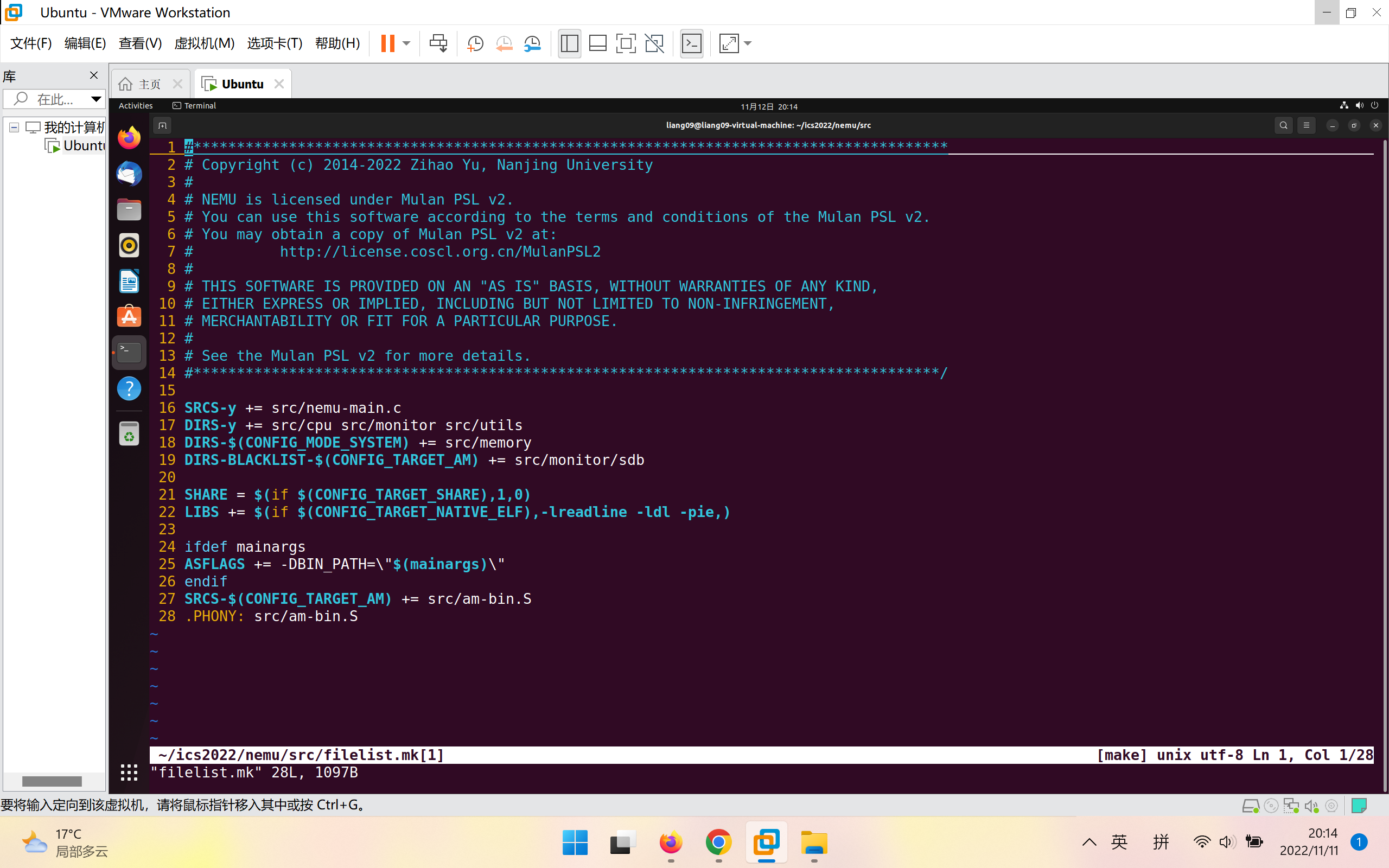
Makefile会包含项目中的所有filelist.mk文件, 对上述4个变量的追加定义进行汇总, 最终会过滤出在SRCS-y中但不在SRCS-BLACKLIST-y中的源文件, 来作为最终参与编译的源文件的集合.
上述4个变量还可以与menuconfig的配置结果中的布尔选项进行关联, 例如DIRS-BLACKLIST-$(CONFIG_TARGET_AM) += src/monitor/sdb, 当我们在menuconfig中选择了TARGET_AM相关的布尔选项时, kconfig最终会在nemu/include/config/auto.conf中生成形如CONFIG_TARGET_AM=y的代码, 对变量进行展开后将会得到DIRS-BLACKLIST-y += src/monitor/sdb; 当我们在menuconfig中未选择TARGET_AM相关的布尔选项时, kconfig将会生成形如CONFIG_TARGET_AM=n的代码, 或者未对CONFIG_TARGET_AM进行定义, 此时将会得到DIRS-BLACKLIST-n += src/monitor/sdb, 或者DIRS-BLACKLIST- += src/monitor/sdb, 这两种情况都不会影响DIRS-BLACKLIST-y的值, 从而实现了如下效果:在menuconfig中选中TARGET_AM时, nemu/src/monitor/sdb目录下的所有文件都不会参与编译.
(3)编译和链接
Makefile的编译规则在nemu/scripts/build.mk中定义:
$(OBJ_DIR)/%.o: %.c
@echo + CC $<
@mkdir -p $(dir $@)
@$(CC) $(CFLAGS) -c -o $@ $<
$(call call_fixdep, $(@:.o=.d), $@)通过上网查找得知其中$@为目标文件,$<为第一个依赖文件,$^为所有依赖文件。
运行make -nB可以让make命令“只输出命令但不执行”从而可得
gcc -O2 -MMD -Wall -Werror -I/home/user/ics2022/nemu/include
-I/home/user/ics2022/nemu/src/engine/interpreter -I/home/use
r/ics2022/nemu/src/isa/riscv32/include -O2 -D__GUEST_ISA__
=riscv32 -c -o /home/user/ics2022/nemu/build/obj-riscv32-nem
u-interpreter/src/utils/timer.o src/utils/timer.c对比可得
$(CC) -> gcc
$@ -> /home/user/ics2022/nemu/build/obj-riscv32-nemu-interpreter/src/utils/timer.o
$< -> src/utils/timer.c
$(CFLAGS) -> 剩下的内容(也就是"-O2 -MMD -Wall -Werror"这一堆)注:通过Wiki有CFLAGS and CXXFLAGS are either the name of environment variables or of Makefile variables that can be set to specify additional switches to be passed to a compiler in the process of building computer software.也就是说它们是Makefile变量或者环境变量,可被传递给编译器作为一些选项的开关
三、准备并运行客户程序
kconfig会根据配置选项的结果在 nemu/include/generated/autoconf.h中定义一些形如CONFIG_xxx的宏,在nemu/include/macro.h中定义了一些专门用来对宏进行测试的宏. 例如IFDEF(CONFIG_DEVICE, init_device());表示, 如果定义了CONFIG_DEVICE, 才会调用init_device()函数; 而MUXDEF(CONFIG_TRACE, "ON", "OFF")则表示, 如果定义了CONFIG_TRACE, 则预处理结果为"ON"("OFF"在预处理后会消失), 否则预处理结果为"OFF".
补充:宏是如何工作的?
- #define is a preprocessor directive(预处理指令) that is used to define macros in a C program.
- #define is also known as a macros directive.
- #define directive is used to declare some constant values or an expression with a name that can be used throughout our C program.
- Whenever a #define directive is encountered, the defined macros name replaces it with some defined constant value or an expression
也就是程序在预处理阶段用define定义的将内容进行了替换
问题又来了,预处理指令是什么:即在编译之前对原文件进行加工的指令,在对一个源文件进行编译时,系统自动调用预处理程序对预处理部分进行处理,之后进行源程序的编译。可以处理#开头的指令,如#define,#include,#if,#elif等
1、将客户程序读入到客户计算机中, 这件事是monitor来负责的。
NEMU在开始运行的时候, 首先会调用init_monitor()函数(在nemu/src/monitor/monitor.c中定义) 来进行一些和monitor相关的初始化工作,init_monitor()函数的代码里面全部都是函数调用。这样做为了将函数具体内容封装,方便阅读与修改。
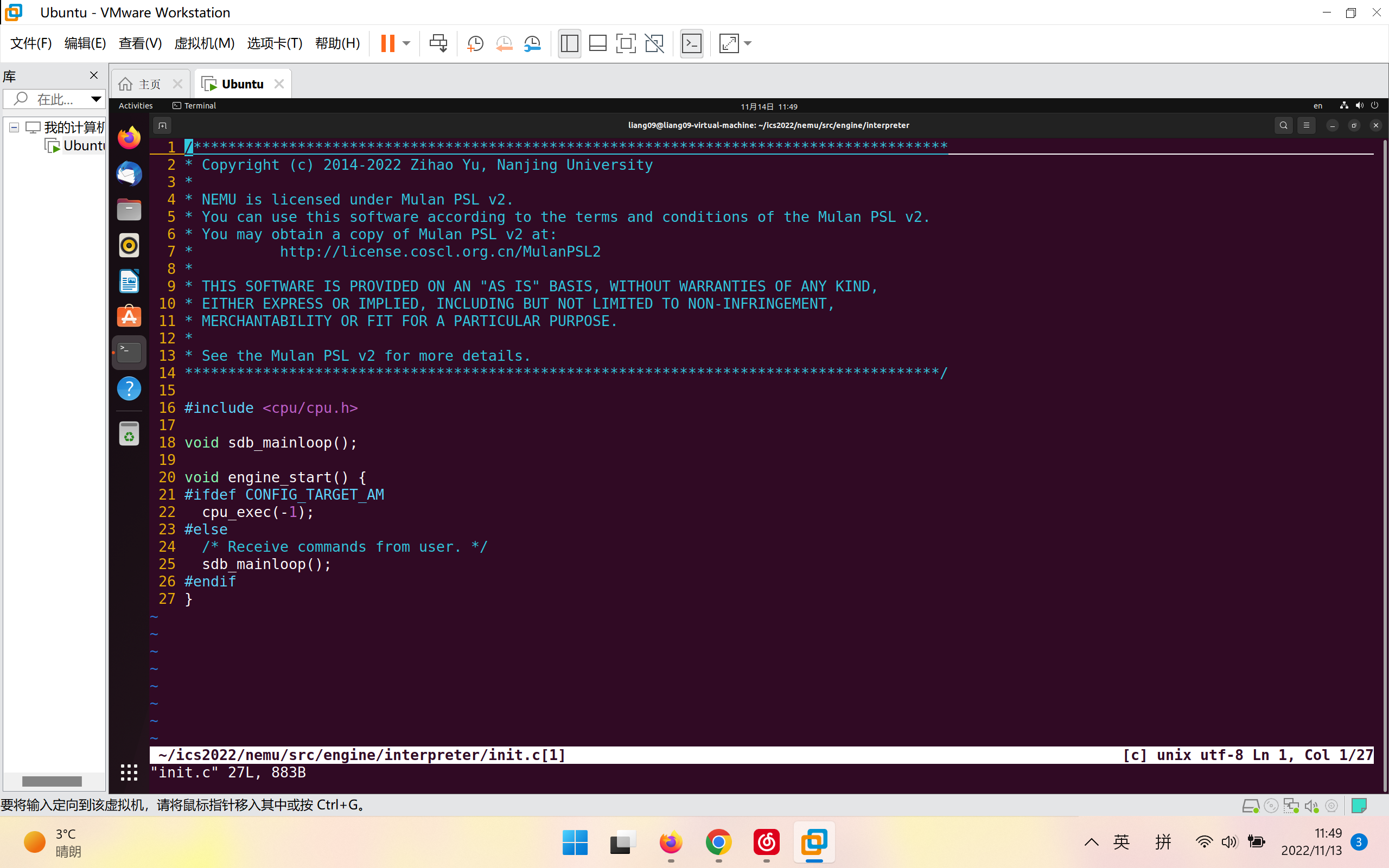
Monitor的初始化工作结束后, main()函数会继续调用engine_start()函数 (在nemu/src/engine/interpreter/init.c中定义). 代码会进入简易调试器(Simple Debugger)的主循环sdb_mainloop() (在nemu/src/monitor/sdb/sdb.c中定义), 并输出NEMU的命令提示符:、
(nemu)
简易调试器是monitor的核心功能, 我们可以在命令提示符中输入命令, 对客户计算机的运行状态进行监控和调试. 框架代码已经实现了几个简单的命令, 它们的功能和GDB是很类似的.
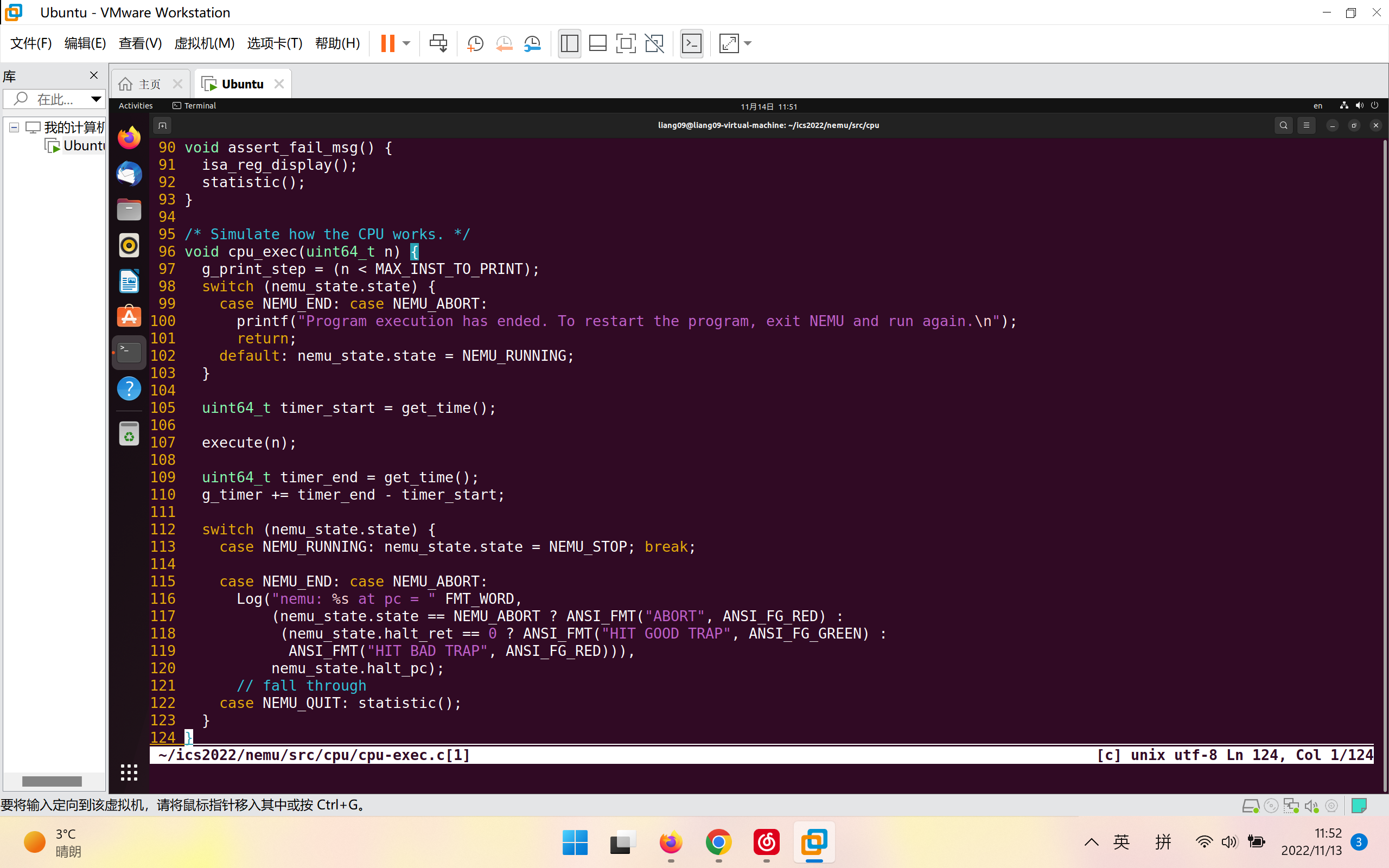
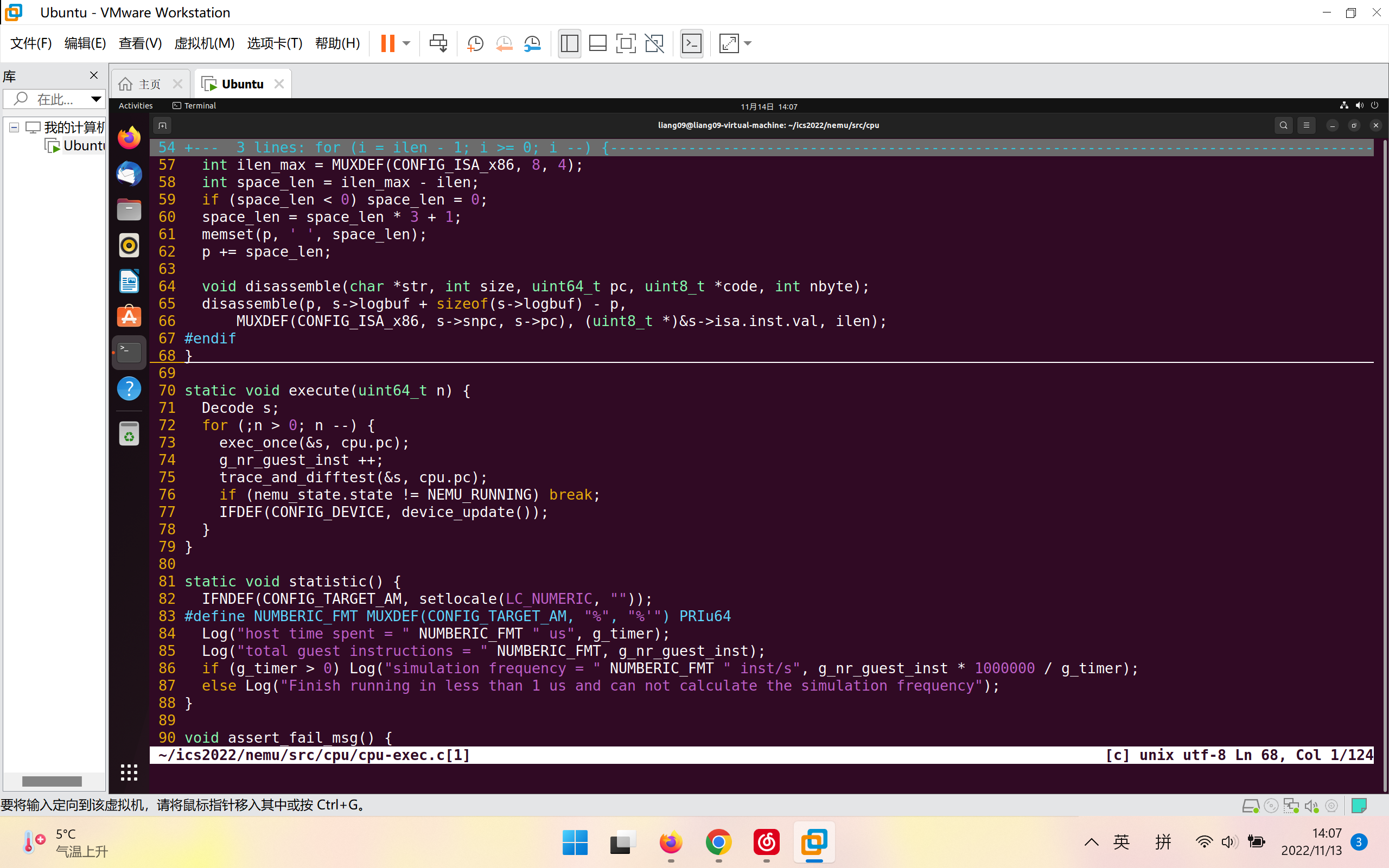
在命令提示符后键入c后, NEMU开始进入指令执行的主循环cpu_exec() (在nemu/src/cpu/cpu-exec.c中定义). cpu_exec()又会调用execute(), 后者模拟了CPU的工作方式: 不断执行指令. 具体地, 代码将在一个for循环中不断调用exec_once()函数, 这个函数的功能就是: 让CPU执行当前PC指向的一条指令, 然后更新PC.
问题:在调用cpu_exec()的时候传入了参数-1,代表什么?
cpu_exec()和execute()中可以看到其形参类型为uint_64,为无符号整数,所以-1在execute函数的for循环中代表执行MAX次数!
如图为cpu_exec()、execute()内容
补充:传入参数为-1是否是未定义行为:
6.3.1.3 Signed and unsigned integers
- Otherwise, if the new type is unsigned, the value is converted by repeatedly
adding or subtracting one more than the maximum value that can be
represented in the new type until the value is in the range of the new type.
也就是说传入 -1 的时候究竟执行多少次取决于无符号形参的类型
2、在nemu/目录下编译并运行NEMU:
make run会出现如下信息:
[src/monitor/monitor.c:20 welcome] Exercise: Please remove me in the source code and compile NEMU again.
riscv32-nemu-interpreter: src/monitor/monitor.c:21: welcome: Assertion `0' failed.只需要在src/monitor/monitor.c中删除对应代码即可
如图为执行结果:
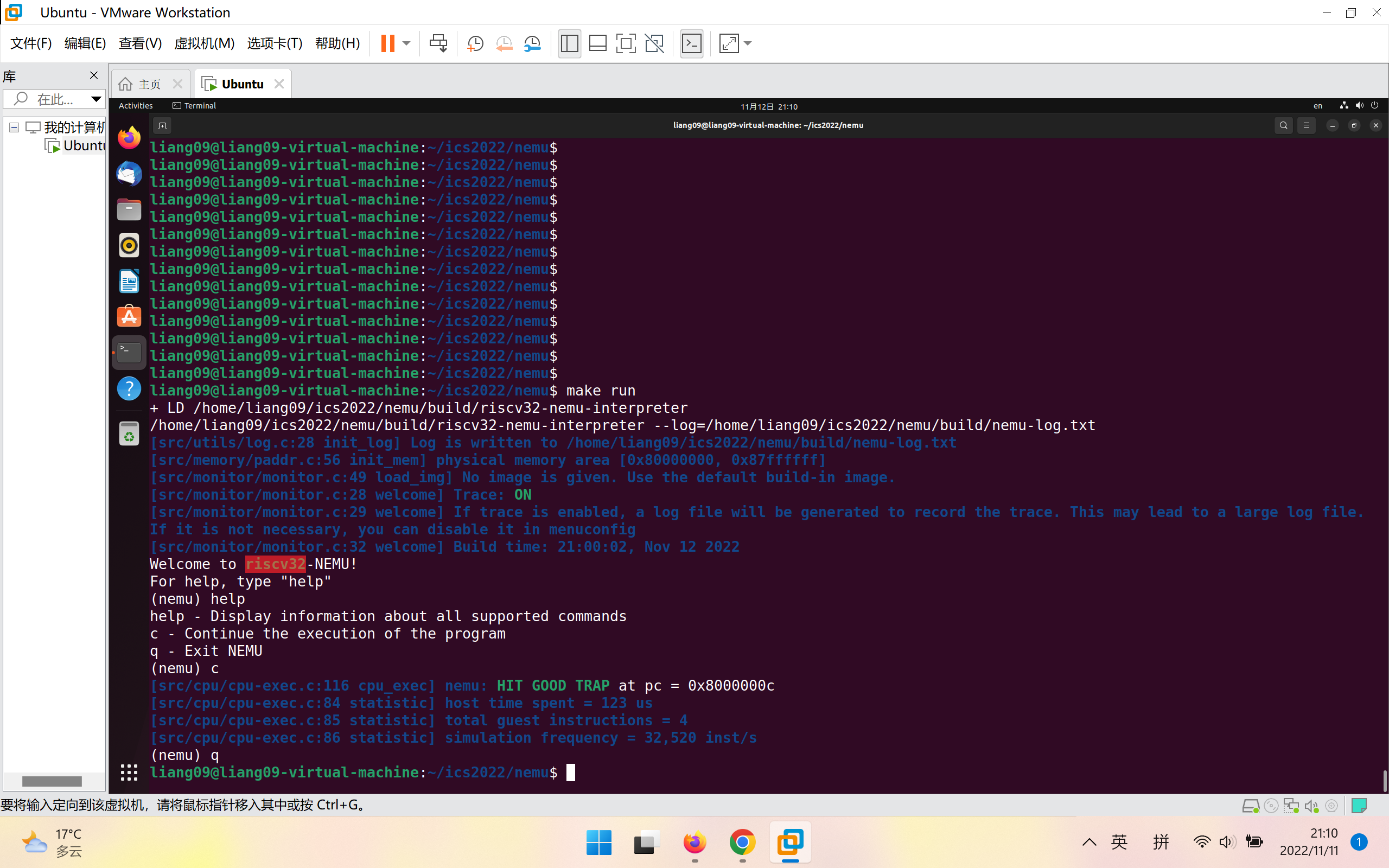
NEMU输出nemu: HIT GOOD TRAP at pc = 0x8000000c 说明程序成功运行
NEMU会在cpu_exec()函数的最后打印执行的指令数目和花费的时间,退出cpu_exec()之后, NEMU将返回到sdb_mainloop(), 等待用户输入命令。
四、实现单步执行、打印寄存器、扫描内存
在monitor中实现一个简易调试器
1、单步执行格式为: si N 代表让程序单步执行N条指令后暂停执行,当N没有给出时, 缺省为1
观察~/ics2022/nemu/src/monitor/sdb/sdb.c中的代码
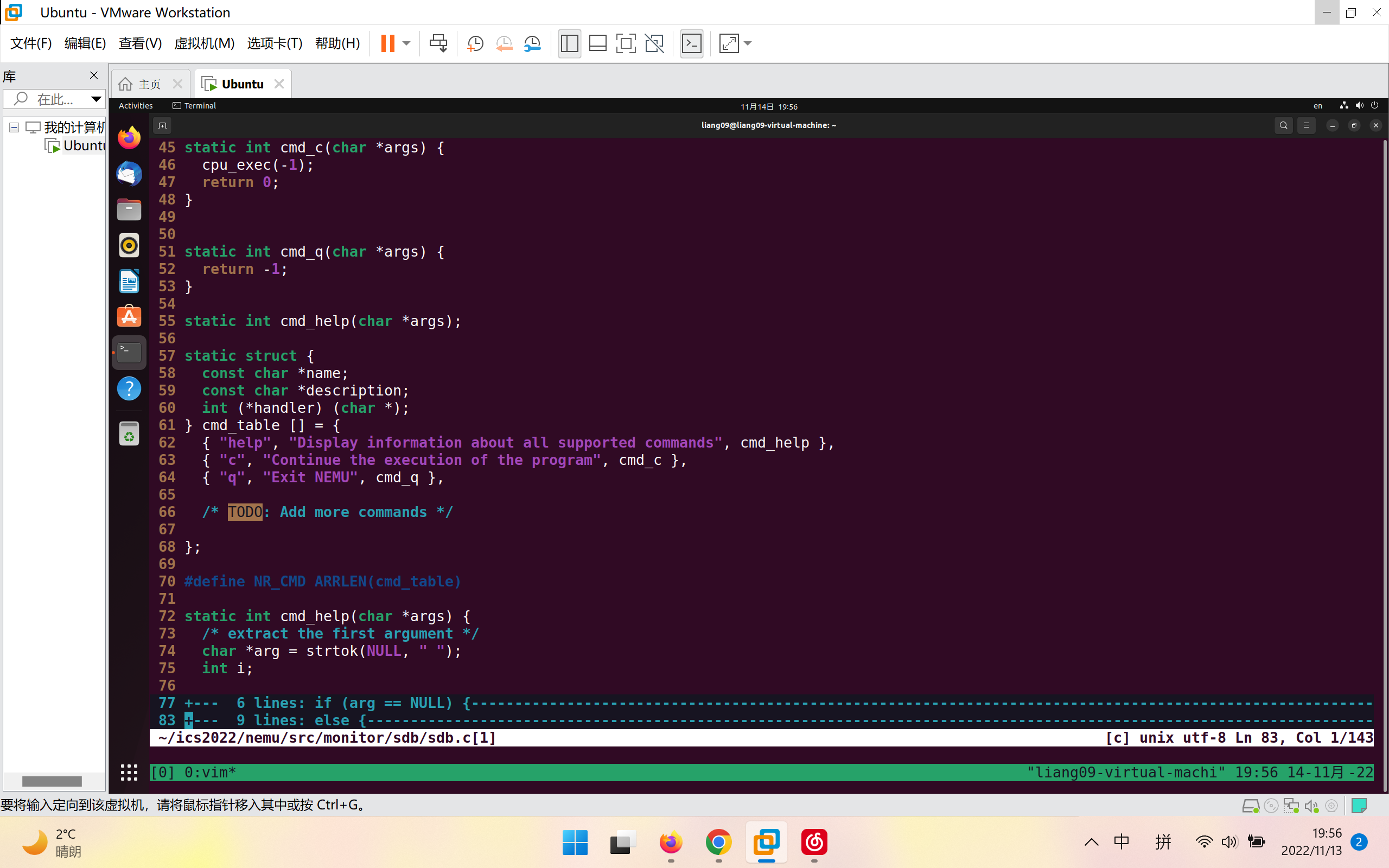
这里注意cmd_c(char *args)函数中调用cpu_exec传入参数为-1,对应无符号数为MAX,所以单步执行只需要改变函数执行的次数即可
加入一个cmd_si(char *args)函数,并在下面对应的cmd_table[]中增加一个"si"选项就好了
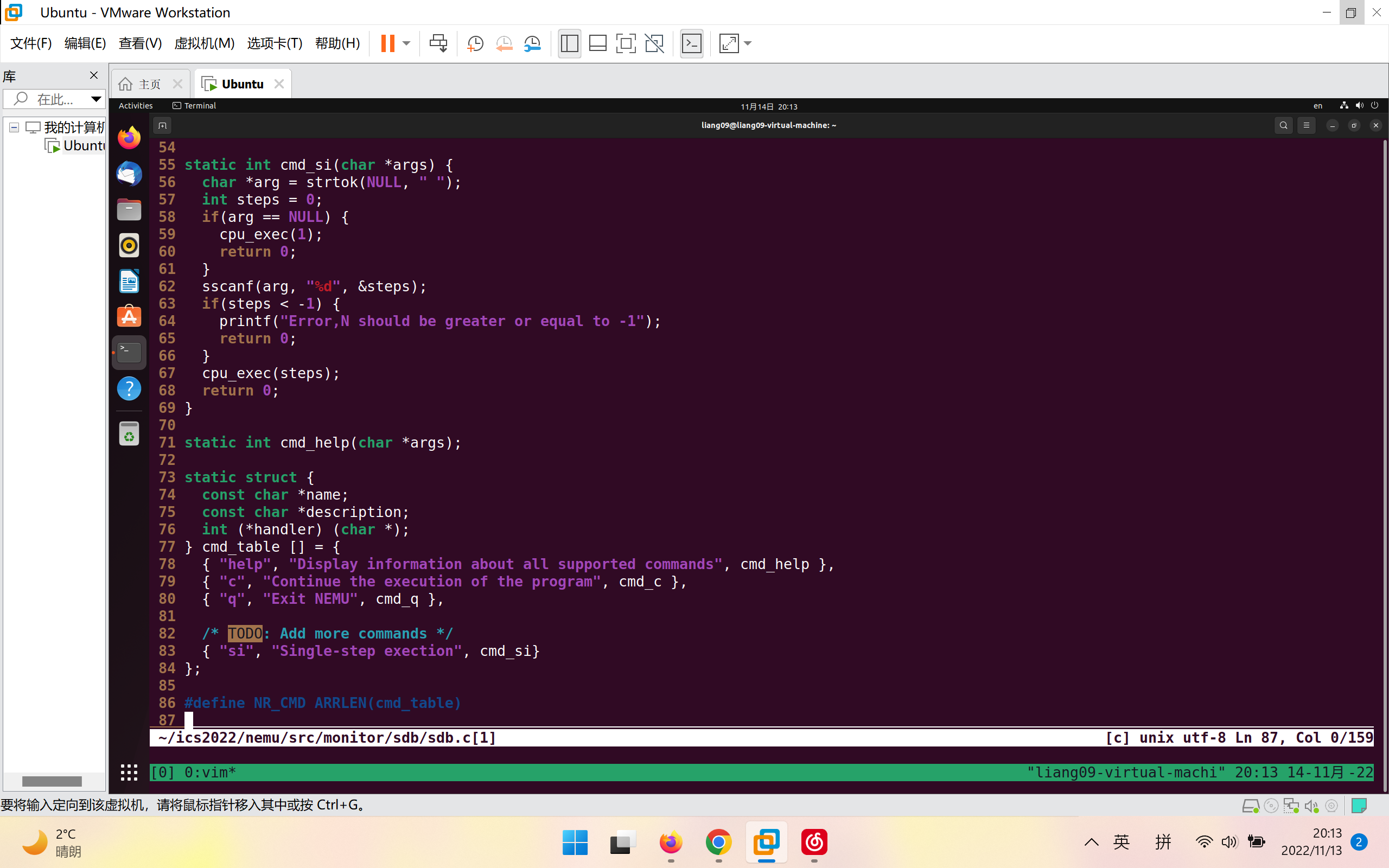
注意:cmd_si(char *args)函数中步数的值不应小于-1,并且默认为1;另外不要忘记增加一个命令提示符"si"!
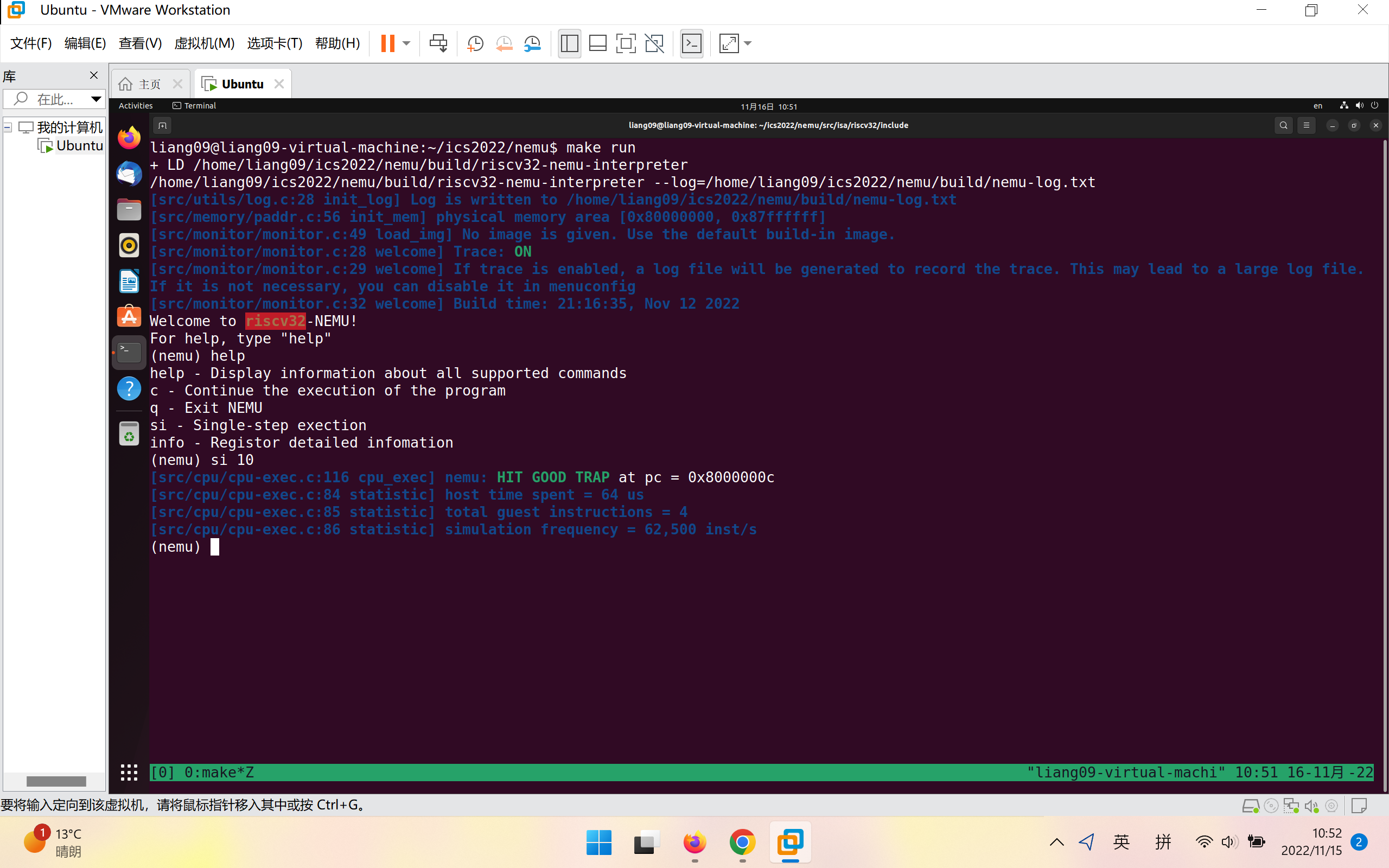
如图为运行si 10后的结果:
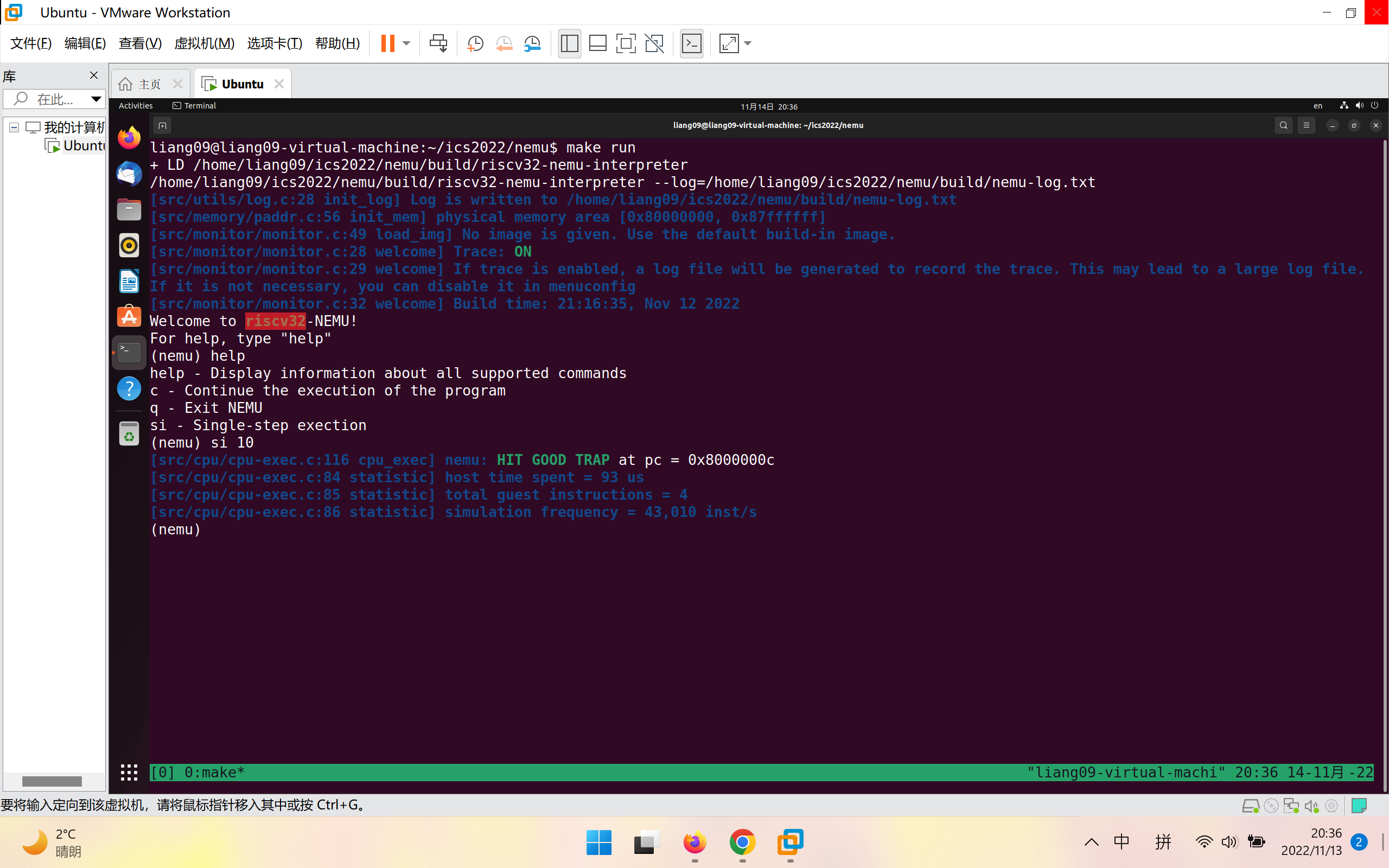
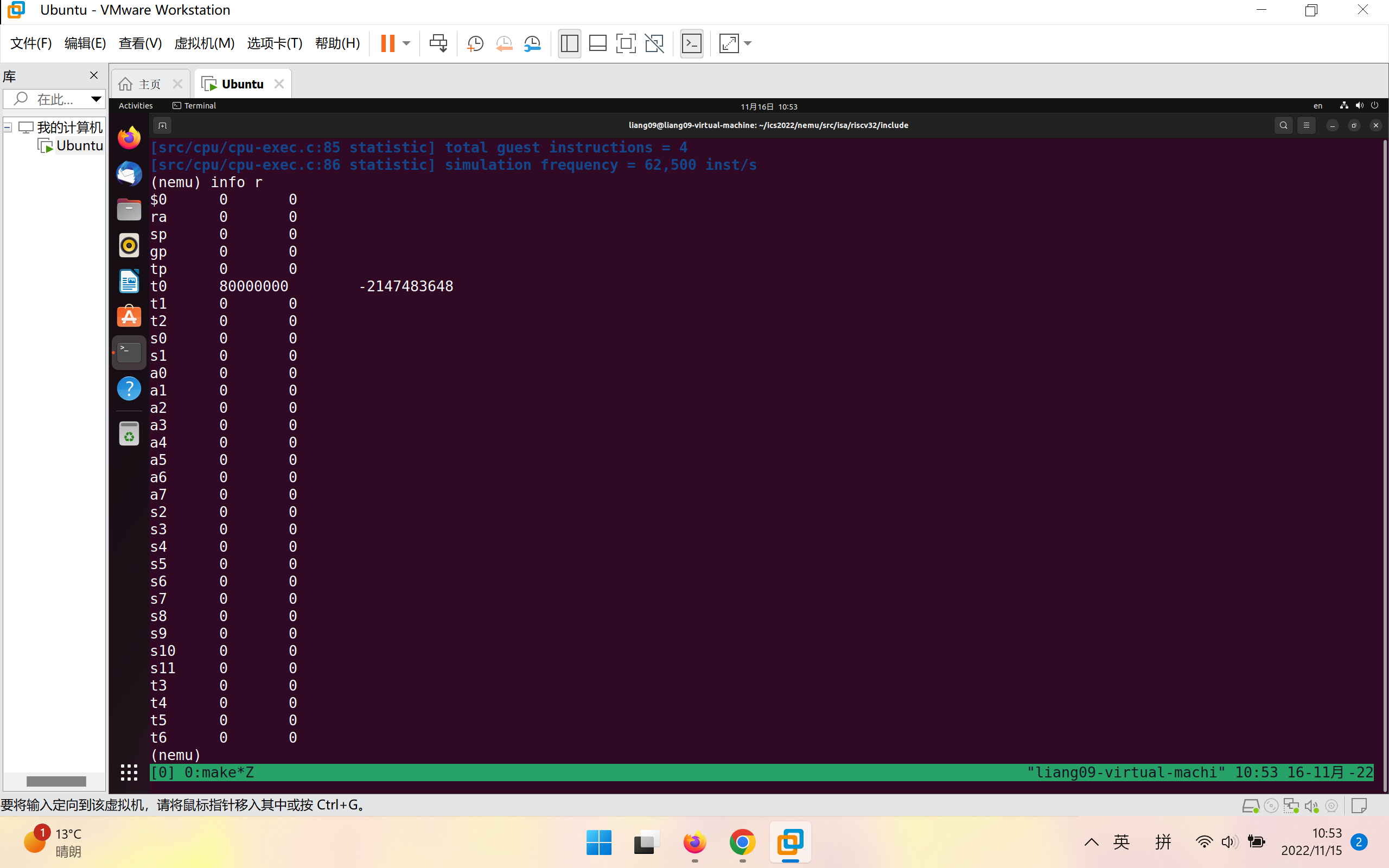
2、打印寄存器格式为:info r 代表打印寄存器状态
如图为寄存器结构体定义:
如图为寄存器名字:
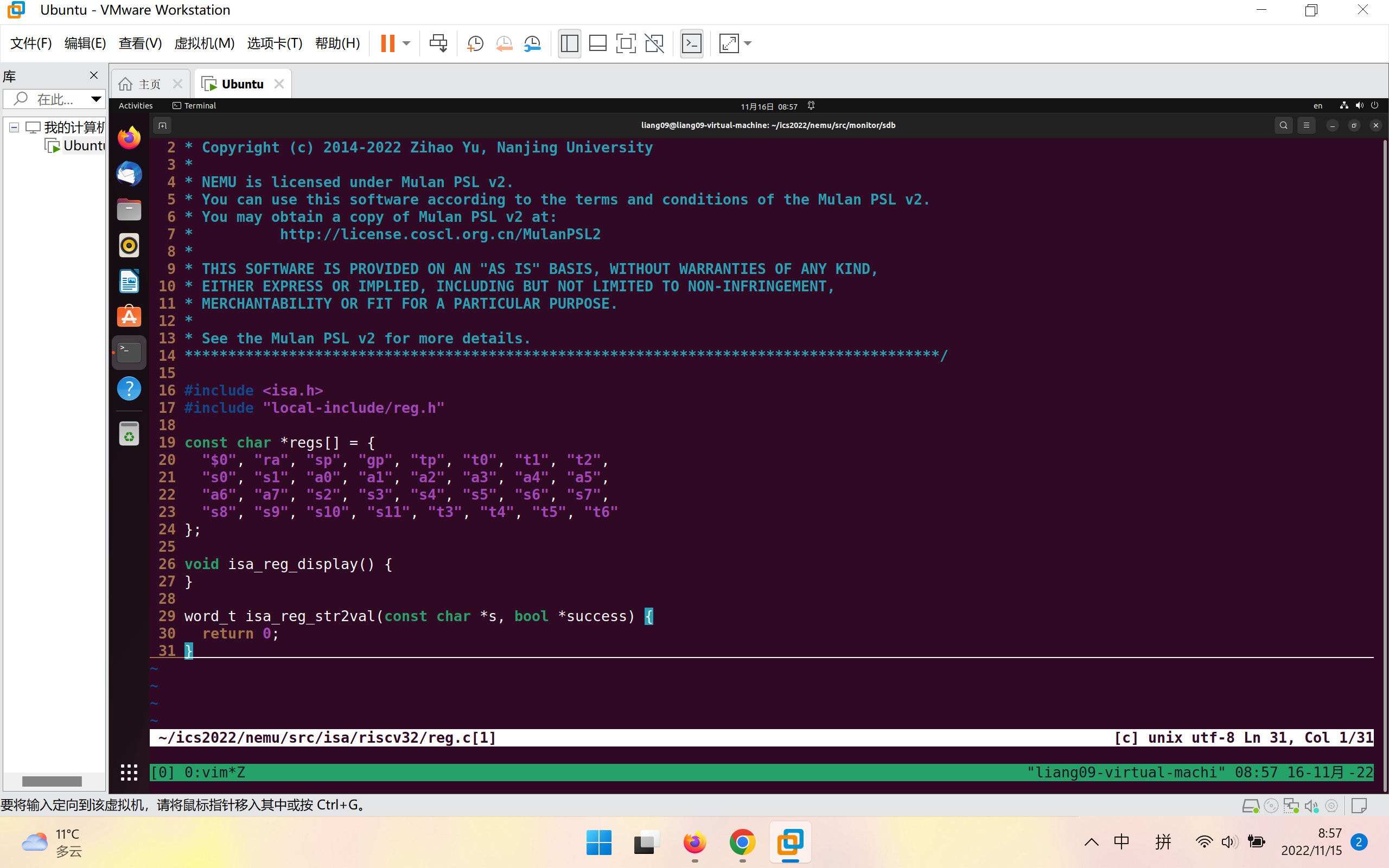
在isa_reg_display()中打印寄存器的值,在~/ics2022/nemu/src/monitor/sdb/sdb.c中添加对应的打印函数并在cmd_table[]中加入对应选项
如图为isa_reg_display()实现:
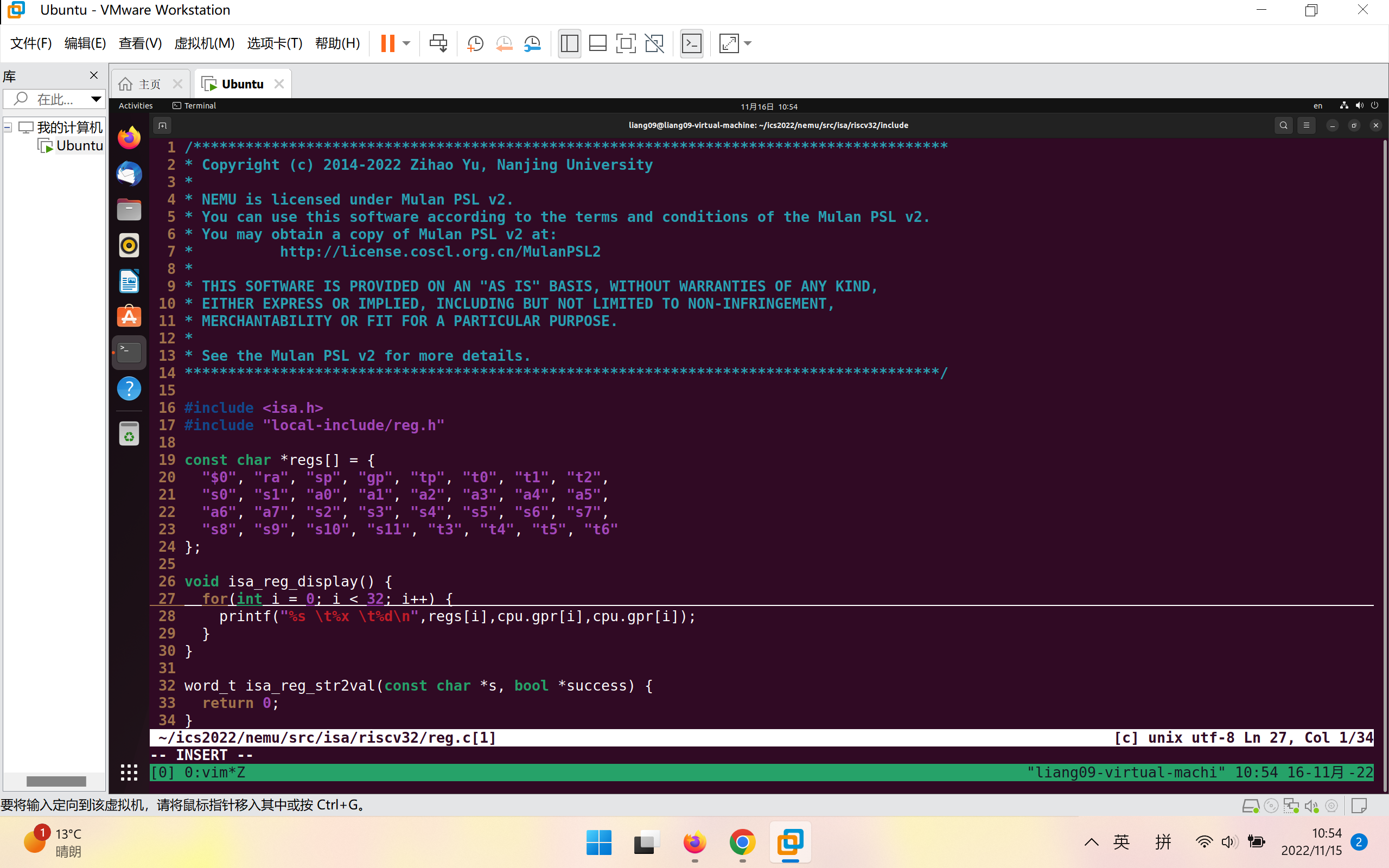
添加cmd_info(char *args)并在cmd_table[]中进行选项的添加:
先执行指令si 10,再执行info r
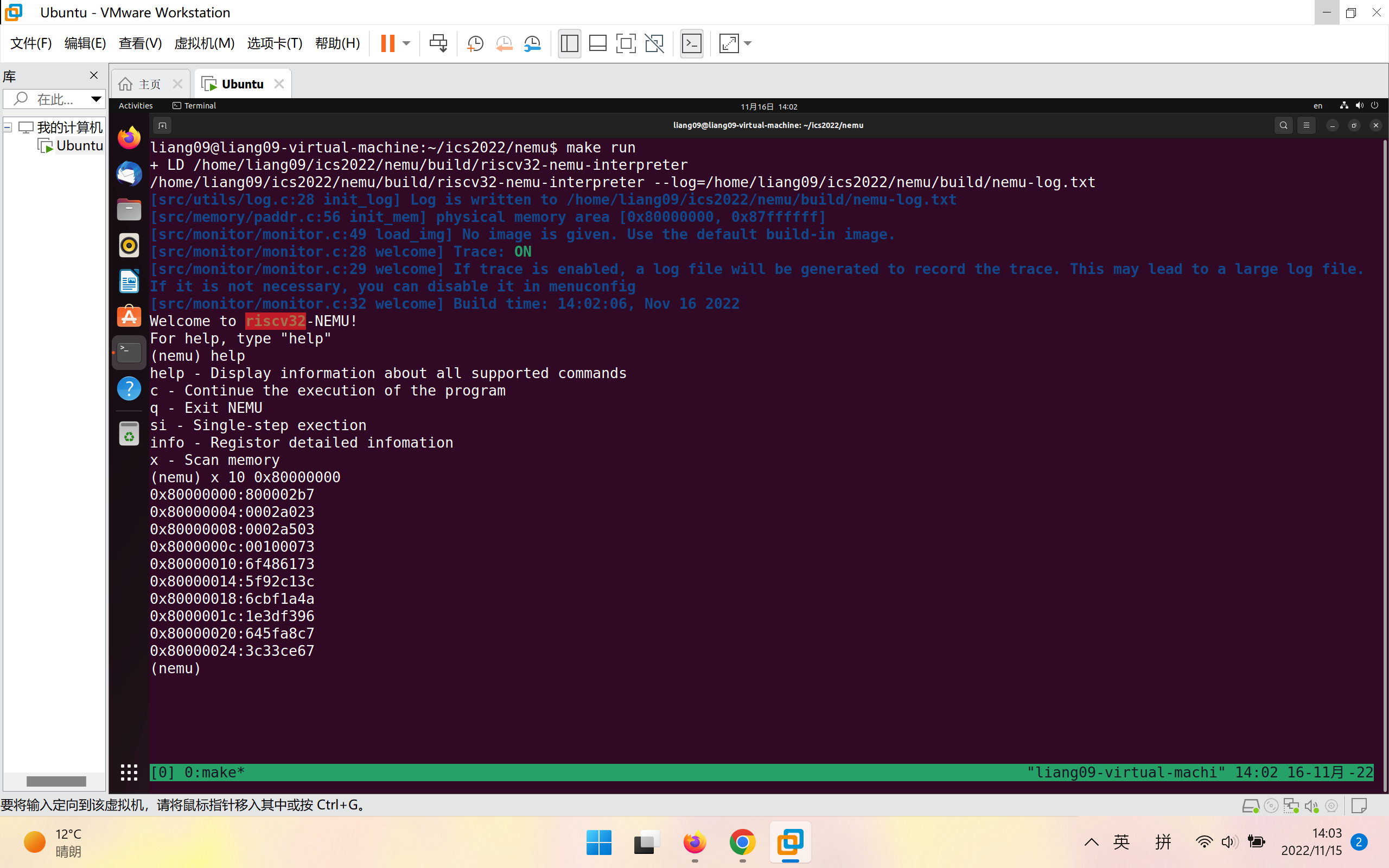
3、扫描内存命令格式为:x N EXPR N代表扫描长度,EXPR代表要扫描的起始内存地址
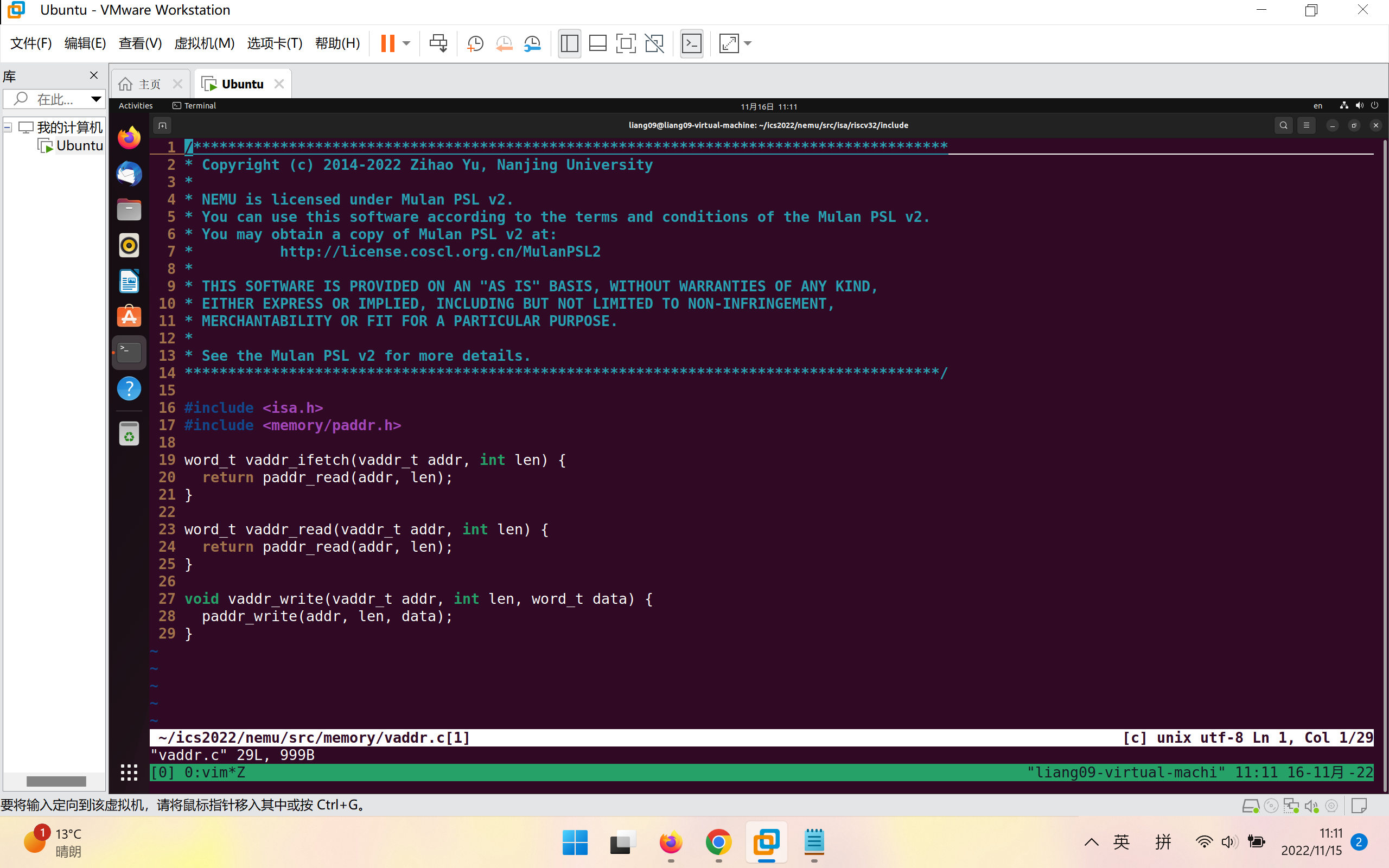
在~/ics2022/nemu/src/memory/vaddr.c中定义了内存读取函数内存读取函数vaddr_read(),需要输入的参数为起始地址、扫描长度,实现如下:
写出cmd_x(char *args)并在cmd_table[]中进行选项的添加:
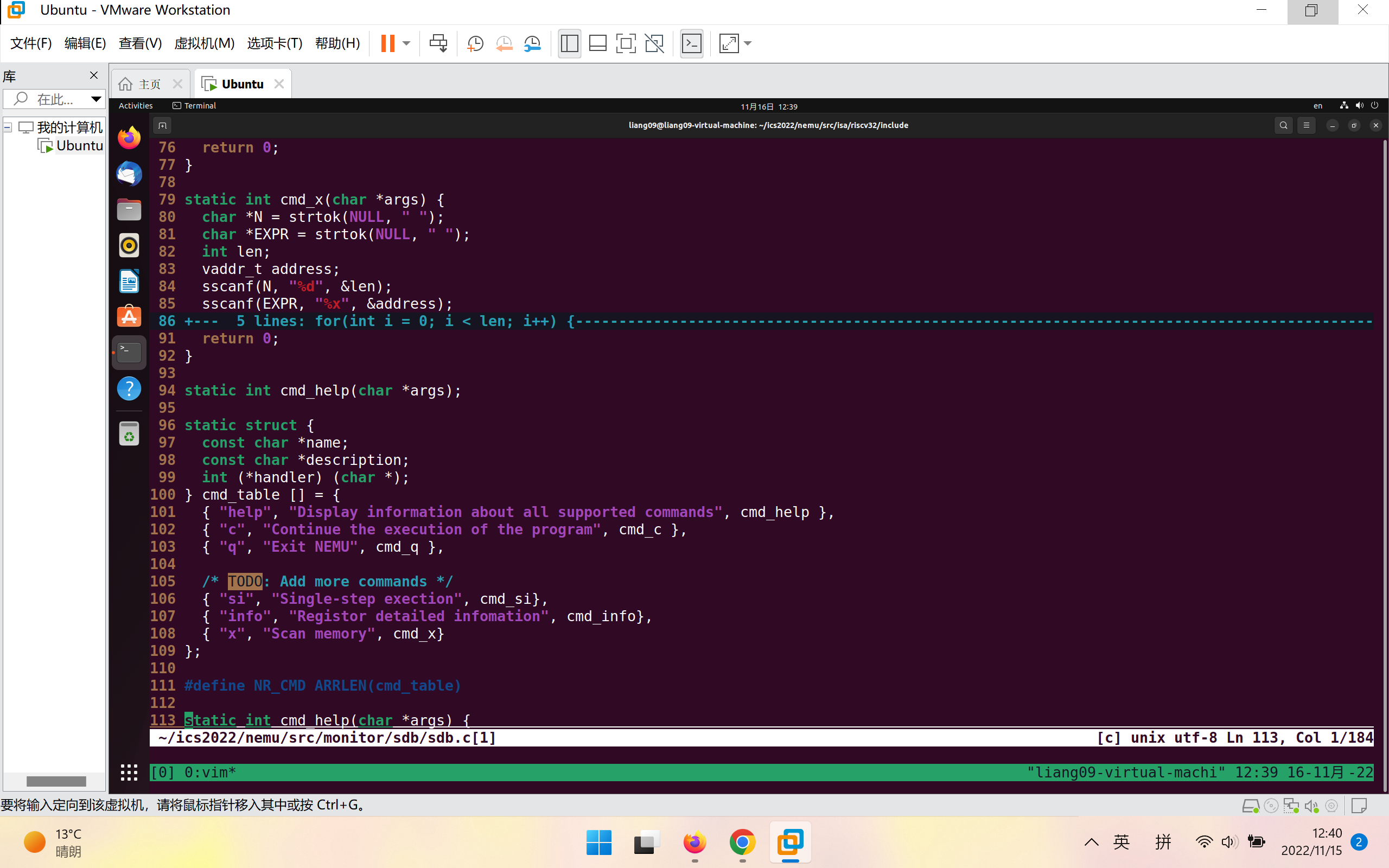
先用strtok()得到N,EXPR的字符串,再用sscanf()得到N的十进制len,EXPR转换为十六进制address
每次将address和4传入vaddr_read函数,然后address自增4
运行发现编译出错:
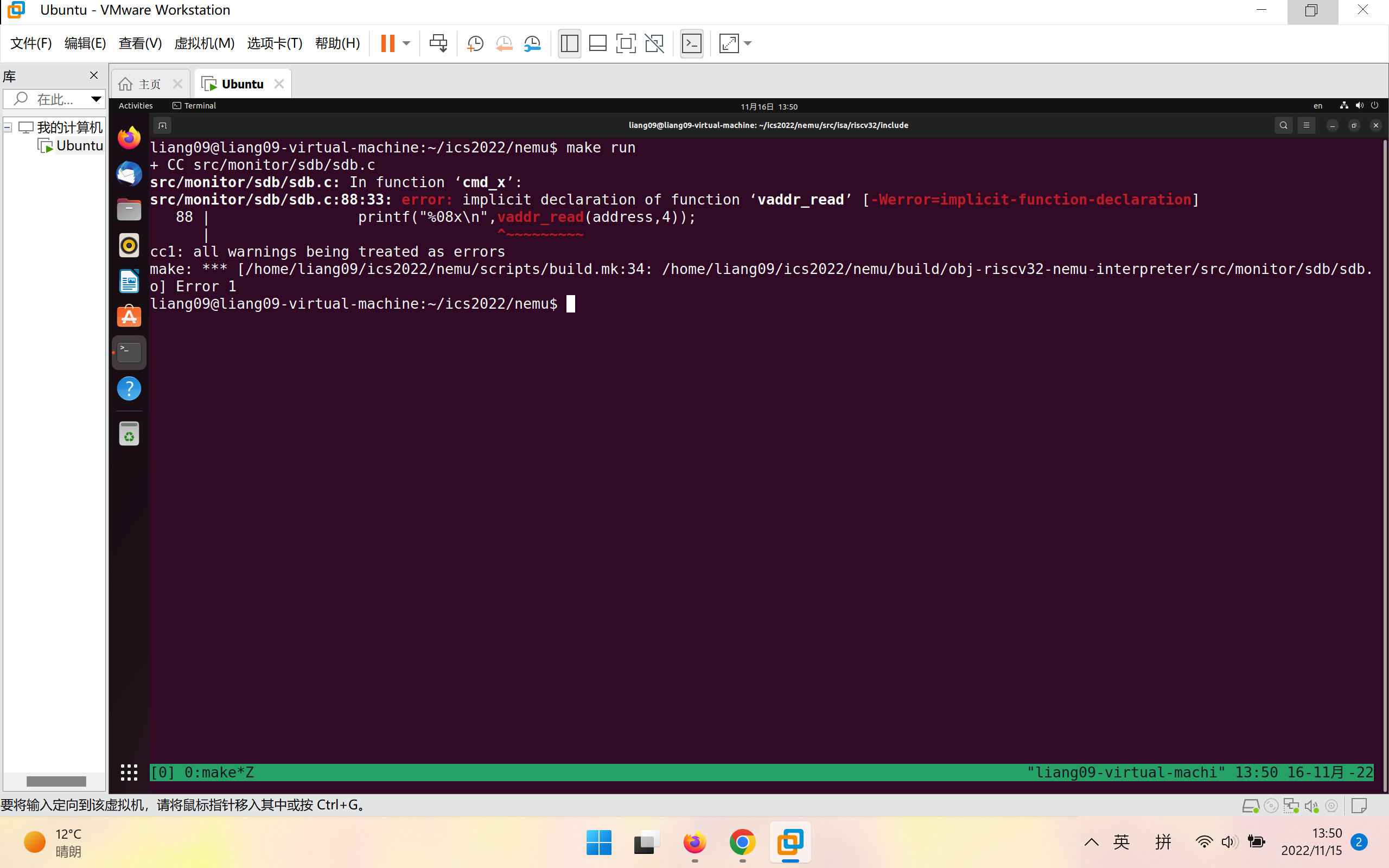
vaddr_read函数的声明在~/ics2022/nemu/include/memory/vaddr.h中
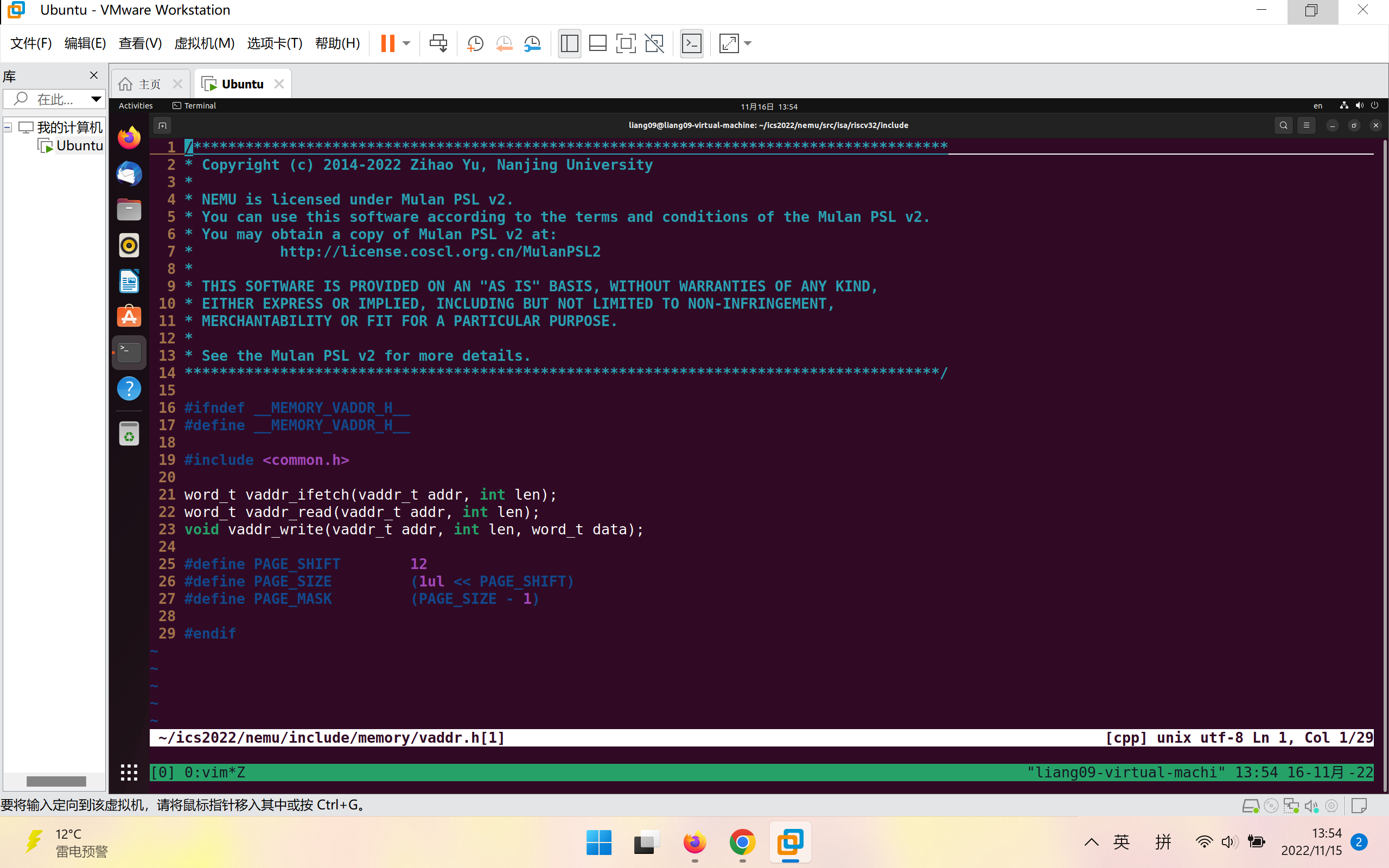
在sdb.c中包含该头文件再次编译

这次编译成功!
如图为执行x 10 0x80000000后的结果
注意:内存范围为[0x80000000, 0x87ffffff]!命令中内存地址不在这里面会报错
PA1.1阶段结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号