索引
索引是什么
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构
他能干什么
增快查询速度
底层
b+tree。所有的关键字全部存储在叶子节点上;
具体流程转载于https://www.cnblogs.com/tilamisu007/p/9293713.html
二、B-Tree
m阶B-Tree满足以下条件:
1、每个节点至多可以拥有m棵子树。
2、根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
3、非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,如5阶B树,每个节点至少有3个子树,也就是至少有3个叉)。
4、非叶节点中的信息包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。
5、从根到叶子的每一条路径都有相同的长度(叶子节点在相同的层)
B-Tree特性: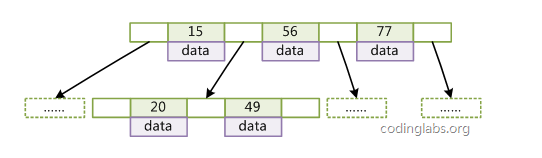
1、关键字集合分布在整颗树中;
2、任何一个关键字出现且只出现在一个节点中;
3、每个节点存储date和key;
4、搜索有可能在非叶子节点结束;
5、一个节点中的key从左到右非递减排列;
6、所有叶节点具有相同的深度,等于树高h。
B-Tree上查找算法的伪代码如下:
三、B+Tree
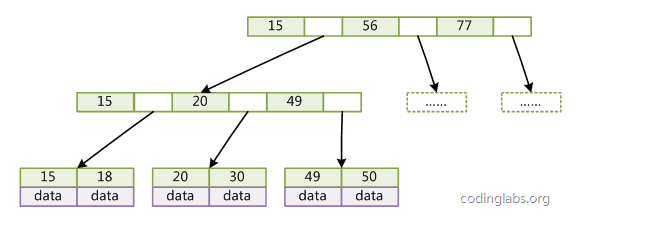
B+Tree与B-Tree的差异在于:
1、B+Tree非叶子节点不存储data,只存储key;
2、所有的关键字全部存储在叶子节点上;
3、每个叶子节点含有一个指向相邻叶子节点的指针,带顺序访问指针的B+树提高了区间查找能力;
4、非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字;
四、B/B+树索引的性能分析
依据:使用磁盘I/O次数评价索引结构的优劣
主存和磁盘以页为单位交换数据,将一个节点的大小设为等于一个页,因此每个节点只需一次I/O就可以完全载入。
根据B树的定义,可知检索一次最多需要访问h个节点
渐进复杂度:O(h)=O(logdN)
dmax=floor(pagesize/(keysize+datasize+pointsize))
一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3,3层可存大约一百万数据)
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存)
B+Tree内节点不含data域,因此出度d更大,则h更小,I/O次数少,效率更高,故B+Tree更适合外存索引。
索引的种类
1.普通索引
2.唯一索引(可以null)
3.主键索引(特殊唯一索引,非空,每个表只有一个)
4.组合索引(多个列组合而成,遵循”最左前缀”原则)
5.反向索引也叫倒排索引 ES 重点 开源全文检索方案基于反向索引
Lucene和ES的区别
定义:
Lucene是一个java信息检索程序库。您可以将其包含在项目中,并使用函数调用来参考其功能。
Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎(搜索引擎和检索程序库不完全等同)。
Elasticsearch是基于JSON的,分布式的,基于Lucene的Web服务。
关系:
Elasticsearch基于Lucene构建,Elasticsearch利用Lucene做实际的工作
ELasticsearch中的每个分片都是一个分离的Lucene实例.
Elasticsearch在Lucene基础上(即利用Lucene的功能)提供了一个分布式的、基于JSON的REST API 来更方便地使用 Lucene的功能。
Elasticsearch提供其他支持功能,如线程池,队列,节点/集群监控API,数据监控API,集群管理等
反向索引:从词到文档。
反向索引方向则是正向索引的逆向,建立从单词 (word) 到文档 (document lsit) 的映射关系。
Word Documents
the Document_1, Document_3, Document_4, Document_5, Document_7
cow Document_2, Document_3, Document_4
says Document_5
moo Document_6
6.正向索引
从文档到单词
假如有三个 txt 文档,
Document_1: The cow says moo.
Document_2: The cat and the hat.
Document_3: The dish ran away with the spoon.
解析每个文档出现的单词,然后建立从文档 (document) 到词组 (words) 的映射关系,这就是正向索引。
Document Words
Document_1 the,cow,says,moo
Document_2 the,cat,and,the,hat
Document_3 the,dish,ran,away,with,the,spoon
索引缺点:
1、降低更新表的速度(update,insert和delete操作),因为更新时也会保存索引文件
2、占用磁盘空间,一般情况问题不大,但是在一个大表建立多种组合索引时,索引文件会膨胀很快。
什么情况下不推荐使用索引?
1.数据唯一性差(一个字段的取值只有几种时)的字段不要用
2.频繁更新的字段不要用索引
3.字段不在where语句出现时不要加索引,如果where 后含 IS NULL/IS NOT / LIKE %"",等不要使用,因为会使其失效
4.where子句里对索引列使用不等于(<>) 使用索引效果一般
什么时候会导致索引失效?
1.有or的时候
2.符合索引未使用左列字段
3.like 以%‘ ’开头
4.需要类型转换
5.where中索引列有运算
6.where中所以使用了函数
7.如果myql觉得全表扫描更快的时候(当数据少)

