


NoSql
为什么用
-
演进历程
大数据时代
单击MySQL时代
网站 更多的使用静态html时代, 服务压力不大
1. 如果数据量太大, 一个机器放不下了
2. 数据的索引(B + Tree), 一个机器内存也放不下
3. 访问量 (读写混合) 一个服务器承受不了
所以必须晋级
Memcached(缓存) + MySQL + 垂直拆分(读写分离)
网站80%都是在读 每次操作数据库就比较麻烦 所以希望减轻压力 演进缓存(解决读的过程)
发展过程: 优化数据结构和索引--->文件缓存(IO) --->Memcached(当时最热门技术)
分库分表 + 水平拆分 + MySQL集群
早些年MyISAM: 表锁( 查询某条时, 锁整张表, 其他不能执行, 效率低)
转变Innob: 行锁
慢慢的就开始使用分库分表来解决写的压力 ---> 推出表分区(很少使用)
MySQL的集群出现, 很好的满足当时的需求
如今:
削减MySQL数据库的压力
-
为什么要用NoSQL
用户的个人信息, 社交网络, 地理位置, 用户自己产生的数据, 用户日志等等爆发式增长
这时候我们就需要使用NoSQL数据库, 它可以更好的处理以上情况
是什么
-
Not Only SQL
-
关系型数据库: 表格, 行, 列
-
NoSql泛指非关系型数据库, 随着web2.0物联网的诞生 传统的关系型数据库难对付web2.0时代, 尤其是大规模的高并发的社区, 暴露出来很多难以克服的问题. NoSQL在当今大数据环境下发展十分迅速, Redis发展最快, 而且是我们当下必须掌握的一个技术
-
很多的数据类型用户的个人信息, 社交网络, 地理位置, 这些数据类型的存储不需要一个固定的模式, 不需要多余的操作就可以横向扩展的 就像Map<String,Object> 使用键值对控制
特点
-
方便扩展(数据之间没有关系, 很好扩展)
-
大数据量最高性能(Redis 一秒写8万次 读取11万 NoSQL缓存, 是一种细粒度的缓存,性能会比较高)
-
数据类型是多样型的(不需要事先设计数据库, 随去随用, 如果数据量十分大的表, 很多人无法设计(设计困难))
-
传统RDBMS(关系型数据库)和NoSQL
传统的 RDBMS
结构化组织
SQL
数据和关系都存在单独的表中
操作数据, 数据定义语言
严格的一致性
基本的事务
...
NoSQL
不仅仅是数据
没有固定的查询语法
键值对存储, 列存储, 文档存储, 图形数据库(社交关系)
最终一致性
CAP定理和BASE(异地多活) CAP: 一致性, 可用性, 分区容错性 BASE: 保证可用性或可靠性
高性能, 高可用, 高可扩
...
了解大数据时代的3V+3高
-
3V
-
海量
-
多样
-
试试
-
-
3高
-
高并发
-
高可拓
-
高性能
-
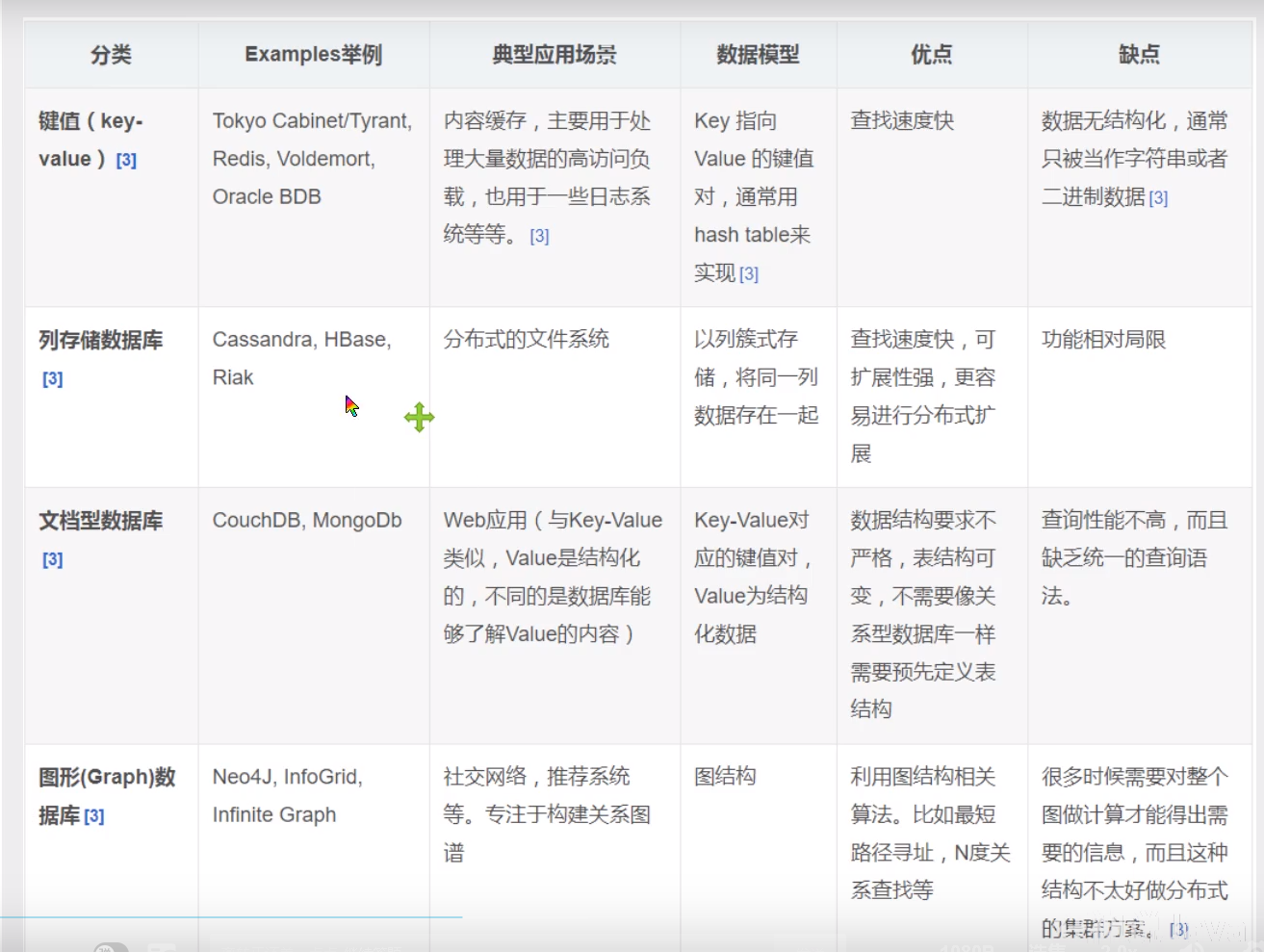
四大分类
KV键值对:
-
新浪: Redis
-
美团: Rdis + Tair
-
阿里, 百度:Redis + memecache
文档型数据库( bson格式 和 json一样)
-
MongoDB (一般必须要掌握)
-
MongoDB 是一个基于分布式文件存储的数据库, C++编写, 主要用于处理大量的文档
-
MongoDB是一个介于关系型数据库和芬关系数据中中间额产品. 是非关系型数据库中功能最丰富的,最像关系型数据库的
-
-
ConthDB
列存储数据库
-
HBase
-
分布式文件系统
图片系数据库
-
他不是存图形, 放的是关系 比如:朋友圈社交网络, 广告推荐
-
Neo4j, InfoGrid
对比
Redis入门
概述
-
(Remote Dictionary Server ) 远程字典服务
-
C编写 , 支持多种语言调用
-
内存存储, 持久化(edb, aof)
-
结构化数据库
-
效率高, 可用于高速缓存
-
发布订阅系统
-
地图信息分析
-
计时器, 计数器(浏览量)
特性
-
多样的数据类型
-
持久化
-
集群
-
事务
-
...
安装
-
windows
https://github.com/microsoftarchive/redis/releases
Redis-x64-3.2.100.zip
解压
开启: redis-server.exe
连接redis: redis-cli.exe
测试:
set name k
get name
-
Linux
https://redis.io/
解压:sudo tar -zxvf redis-6.0.5.tar.gz
进入目录安装程序:
环境gcc: sudo apt install build-essential
运行:sudo make命令
在运行sudo make
运行sudo make install
redis的默认安装路径: /usr/local/bin
新建目录kconfig: sudo mkdir kconfig
将redis.conf 复制到 当前目录下
sudo cp /opt/redis-6.0.5/redis.conf kconfig/
redis默认不是后台启动的, 修改配置文件的daemonize no 改为yes
修改文件权限: sudo chmod -R 777 redis.conf
daemonize yes
启动服务
通过自定义配置文件 启动服务 : redis-server kconfig/redis.conf
启动客户端: redis-cli -p 6379
测试: ping
set name "c"
get name
新窗口查看redis进程
ps -ef|grep redis
在客服端关闭进程: shutdown
退出exit
测试性能
-
redis-benchmark 压力测试工具
-
命令参数
-
| 选项 | 描述 | 默认值 |
|---|---|---|
| -h | 指定服务器主机名 | 127.0.0.1 |
| -p | 指定服务器端口 | 6379 |
| -s | 指定服务器socket | |
| -c | 指定并发连接数 | 50 |
| -n | 指定请求数 | 100 |
| -d | 以字节的形式指定SET/GET值的数据大小 | 2 |
| -k | 1=keep alive 0 =reconnect | 1 |
| r | SET / GET / INCR 使用随机值 | |
| -p | 通过管道传输<numreq> 请求 | 1 |
| -1 | 强制退出redis, 仅显示query / sec 值 | |
| -csv | 以CSV格式输出 | |
| -l | 生成循环, 永久执行测试 | |
| -t | 仅运行以逗号分隔的测试命令列表 | |
| -I | ldle模式.仅打开N个idle连接并等待 |
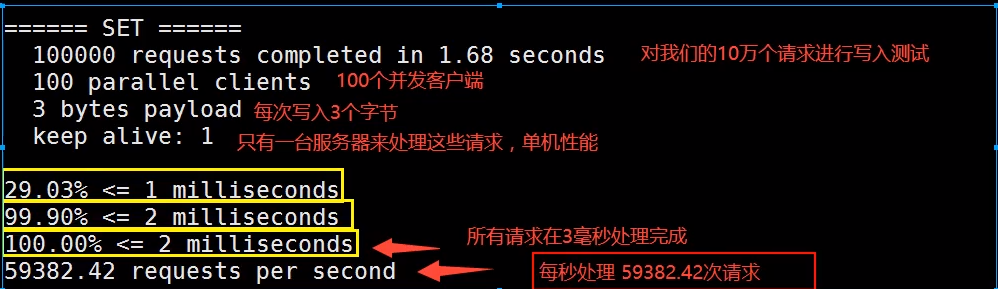
测试
测试: 100个并发连接, 100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
进人目录: cd /usr/local/bin
启动服务: redis-server kconfig/redis.conf
测试客户端连接: redis-cli -p 6379
测试: redis-benchmark -h localhost -p 6379 -c 100 -n 100000
redis基础知识
-
默认有16个数据库, 默认为第1个(0号数据库) (看配置文件)
-
切换数据库: select 3
-
查看数据库size: DBSIZE
-
查看数据库所有的key: keys *
-
清除当前数据库: flushdb
-
清除全部数据库: flushall
-
判断是否存在键: EXISTS name
-
在指定数据库删除key: move name 1
-
设置key有效时间: EXPIRE name 10(秒)
-
查看当前key的剩余时间: ttl name
-
查看key的类型: type name
redis是单线程的
-
基于内存操作, CPU不是redis的瓶颈, Redis的瓶颈是根据机器的内存网络带宽
为什么单线程还这么快
-
核心: redis是将所有的数据全部放在内存中, 所以用单线程去操作效率是最快的
-
多线程需要切换上下文,耗时操作, 对于内存系统来说, 如果没有上下文切换, 多次读写都在一个CPU上, 在内存情况下, 这是最佳方案
五大数据类型
String
-
可以是字符串, 数字, 对象
设值: set key1 v1
获取: get key1
是否存在: EXISTS key1
追加值: APPEND key1 "hello" 返回长度 如果当前key不存在 则创建
获取长度: STRLEN key1
截取字符串: GETRANGE key1 0 3 截取全部: GETRANGE key1 0 -1
替换字符串: SETRANGE key1 0 xx 指定位置开始替换指定字符串长度
设置过期时间: setex key3 30 "hello"
不存在则设置: setnx key "redis" (分布式锁中常使用) 存在就不设置, 直接set如果存在会覆盖
批量设置: mset k1 v1 k2 v2 k3 v3
批量获取: mget k1 k2 k3
批量判断存在设置: msetnx k1 v1 k4 4v 注意这里是需要保持原子性的 都成功才成功
设置对象: set user:1 {name:chen,aeg:3}
巧妙设置对象: mset user:1:name chen user:1:age:3
获取: mget user:1:name user:1:age
组合命令:
获取加设置: getset db reids 返回设置前的值并设置新值: 不存在返回nil,并设置新值
set views 0
自增: incr views 键不存在, 则创建默认值为1
自减: decr views 键不存在, 则创建默认值为-1
指定步长自增: INCRBY views 10
指定步长自减: DECRBY views 10
List
-
在redis里, 我们可以把list玩成 栈, 队列, 阻塞队列
-
实际上是一个链表
-
如果key不存在, 创建新的链表
-
如果key存在, 新增内容
-
如果移除了所有值, 空链表, 也代表不存在
-
在两边插入或者改动值, 效率最高, 中间元素,相等效率低些
添加: LPUSH list one 先进的在最左边 允许存重复的值
截取全部: LRANGE list 0 -1 从左往右取
截取指定范围: LRANGE list 0 1 不该变原来的值
从右边存: Rpush list right 插入到队列右边
从左边移除第一个: Lpop list
从右边移除第一个: Rpop list
通过下标获取值: lindex list 0
获取列表长度: llen list
移除指定的值: lrem list 1 one 移除个数 移除值
截取指定长度: ltrim list 1 2 指定位置开始, 截取指定长度 改变原来的值
移动列表最后一个元素到另一个列表中: RPOPLPUSH list myotherlist
替换指定下标的值(已存在的): lset list 0 item 相当于更新 不存在则报错
插入某个具体值到列表中:
world前: linsert before "world" "other"
world后: linsert after "world" "other"
Set
-
无序的值不允许重复
存值: sadd myset "hello" 查看成员: smembers myset 查看是否存在: sismember myset "hello" 获取元素个数: scard myset 移除指定元素: srem myset hello 随机抽取指定个数的元素: Srandmember myset 一个 Srandmember myset 2 两个 随机删除: spop myset 移动指定成员: smove myset myset2 "hello" 差集,交集, 并集: key1: a,b,c key2: c,d,e SDIFF key1 key2 结果: a,b SINTER key1 key2 结果: c Sunion key1 key2 结果: a,b,c,d,e
Hash
-
Map集合 键值对 值为map集合
存值: hset myhash field1 chen 取值: hget myhash fiedl1 添加逗哥: hmset myhash field1 chen field2 world 获取多个: hmget myhash field1 field2 获取所有:hgetall myhash 删除指定的key: hdel myhash field1 查询长度: hlen myhash 查字段数量 判断key是否存在: HEXISTS mybash field1 查询所有的key: hkeys myhash 获取所有的值: hvals myhash 自增: hincrby myhash field1 1 不存在才存: hsetnx myhash field1 hello 存对象: hset user:1 name chen
-
用在变更的值: user
Zset
-
在ser的基础上, 增加了一个值 set k1 v1 zset k1 score1 v1 用于排序
添加: zadd myset 1 one 添加多个: zadd myset 2 two 3 three 查询所有: Zrange myset 0 -1 排序: zrangebyscore salary -inf +inf 按照salary从小到大排序 不能反过来 zrevrange salary 0 -1 从大到小排序 排序并带上值: zrangebyscore salary -inf +inf withscores 排序到指定范围并带上值: zrangebyscore salary -inf 2500 withscores 移除指定元素: zrem salary chen 查询元素个数: zcard salary 统计指定区间内的元素个数: zcount myset 1 2
-
set排序: 存储班级成绩表, 工资表排序
-
普通消息,1 重要消息:2, 带权重进行判断
-
排行榜应用实现, 取Top
三大特殊数据类型
geospatial地理位置
-
朋友的定位, 附近的人, 打车距离计算
-
Reds的Geo
-
可以查询一些数据
有效经度: -180度到180度 纬度: -85.05112878度到85.05112878度 添加地理位置: geoadd china:city 116.40 39.90 beijing geoadd china:city 121.47 31.23 shanghai geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shengzheng geoadd china:city 120.16 30.24 hangzou 108.96 34.26 xian 获取: geopos china:city beijng geopos china:city beijing shanghai 两人之间的距离: 单位 m米, km千米, mi英里, ft英尺 geodist china:city beijing shanghai geodist china:city beijing shanghai km 附件的人: 半斤查询 georadius china:city 100 30 1000 km 以100 30为中心找1000km的 并查看参数 显示经度纬度 withcoord 到中心直线距离 withdist 限定个数count georadius china:city 100 30 1000 km withdist withcoord count 2 以指定元素为中心: georadiusbymember china:city shanghai 400 km 返回二维的经纬度的字符串形式: geohash china:city shanghai chongqing 底层实现原理其实是zset 所以可以用zset操作 查看所有元素 zrange china:city 0 -1 删除元素: zrem china:city beijing
Hyperloglog
-
什么是基数
-
不重复的元素个数
-
-
基数统计
网页的UV(一个人访问一个网站多次, 但是还是算作一个人) * 原先通过存储的id * 现在使用基数统计 优点: 占用的内存固定: 2^64 12KB 0.81%的错误率,可以忽略不计 存: PFadd mykey a b c d e f g h i j 查看不重复的个数: PFcount mykey 合并: PFmerge mykey3 mykey mykey2 合并mykey和mykey2为mykey3
Bitmaps
-
位存储
-
Bitmaps位图, 数据结构, 都是操作二进制位来进行记录 就只有0和1两个状态
统计用户信息, 活跃, 不活跃, 登录, 未登录 ,打卡 未打卡 1 0 记录周一到周日的打卡 存: setbit sign 0 1 setbit sign 1 1 setbit sign 2 0 setbit sign 3 1 setbit sign 4 0 setbit sign 5 1 setbit sign 6 0 获取: getbit sign 6 统计打卡天数: bitcount sign
事务
-
redis事务的本子: 一组命令的集合, 一个事务中的所有命令都会被序列化, 在事务执行过程中, 会按照顺序执行
-
一次性, 顺序性, 排他性, 执行一些列的命令
-
redis事务没有隔离级别概念
-
所有的命令在事务中, 没有直接被执行, 只有在发起执行命令的时候才会执行 exec
-
redis单条命令是保持原子性的, 但是事务是没有原子性
-
redis的事务
-
开启事务(multi)
-
命令入队(...)
-
执行事务(exec)
-
取消事务(discard)
127.0.0.1:6379> multi OK 127.0.0.1:6379> mset k1 v1 k2 v2 QUEUED 127.0.0.1:6379> set k3 v3 QUEUED 127.0.0.1:6379> exec 1) OK 2) OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> ser k2 v2 (error) ERR unknown command 'ser' 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> discard OK 127.0.0.1:6379> get k1 (nil)
-
编译时异常, 所有命令都不会执行
-
比如: 命令写错
-
-
运行时异常, 没有异常命令会被执行
-
比如: 字符串不能自增, 命令使用错误
-
监控
悲观锁
-
认为做什么都有问题, 无论做什么都加锁
乐观锁
-
认为什么都不会有问题, 不一定会加锁
-
更新数据的时候去判断下, 在此期间是否有人修改过这个数据
-
获取version
-
更新的时候比较version
redis监控实现乐观锁
127.0.0.1:6379> set money 100 OK 127.0.0.1:6379> set out 0 OK 127.0.0.1:6379> watch money OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> decrby money 20 QUEUED 127.0.0.1:6379> incrby out 20 QUEUED 127.0.0.1:6379> exec 1) (integer) 80 2) (integer) 20 * 监视会在事务执行成功后结束 * 放弃监视 unwatch
模拟事务失败(乐观锁)
-
客户端1在没有执行exec前, 客户端2丢money进行了修改
127.0.0.1:6379> set money 100 OK 127.0.0.1:6379> set out 0 OK 127.0.0.1:6379> watch money OK 127.0.0.1:6379> multi OK 127.0.0.1:6379> decrby money 20 QUEUED 127.0.0.1:6379> incrby out 20 QUEUED 期间客户端2 提交执行 exec 执行失败 127.0.0.1:6379> exec (nil) 事务发生失败 就先解锁, 在加锁获取最新的值 unwatch watch money
127.0.0.1:6379> get money "100" 127.0.0.1:6379> incrby money 100 (integer) 200
Jedis
-
什么是jedis
是Redis官方推荐的java连接开发工具, 使用java操作Redis中间件 如果你要使用java操作redis, 那么一定要对jedis十分的熟悉
-
测试 环境
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.3.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.71</version> </dependency>-
编码测试
-
连接数据库
-
操作命令
-
结束测试
public class TestPing { public static void main(String[] args) { // 1. new Jedis 对象即可 Jedis jedis = new Jedis("127.0.0.1",6379); //jedis 的素有指令 都是之前学过的 System.out.println(jedis.ping());//PONG } } -
-
常用API
key
package com.cyz;
import redis.clients.jedis.Jedis;
import java.util.Set;
public class TestPing {
public static void main(String[] args) {
// 1. new Jedis 对象即可
Jedis jedis = new Jedis("127.0.0.1",6379);
//jedis 的素有指令 都是之前学过的
System.out.println(jedis.ping());//PONG
System.out.println("清空数据: "+jedis.flushDB());
System.out.println("判断某个键是否存在: " + jedis.exists("username"));
System.out.println("新增<'username','chen'> 的键值对: " + jedis.set("username","chen"));
System.out.println("新增<'password','password'> 的键值对: " + jedis.set("password","password"));
System.out.println("系统中所有的键如下: ");
Set<String> keys = jedis.keys("*");
System.out.println(keys);
System.out.println("删除键password:"+ jedis.del("'password"));
System.out.println("判断password是否存在: " + jedis.exists("password"));
System.out.println("查看键username锁存储的类型: "+jedis.type("username"));
System.out.println("随机返回key空间的一个:"+jedis.randomKey());
System.out.println("重命名key: "+jedis.rename("username","name") );
System.out.println("取出改后的name: "+jedis.get("name"));
System.out.println("按索引查询: "+jedis.select(0));
System.out.println("删除当前选择数据库中的所有key: "+ jedis.flushDB());
System.out.println("返回当前数据库中key的数目: "+jedis.dbSize());
System.out.println("删除所有数据库中的所有key: " + jedis.flushAll());
}
}
PONG
清空数据: OK
判断某个键是否存在: false
新增<'username','chen'> 的键值对: OK
新增<'password','password'> 的键值对: OK
系统中所有的键如下:
[password, username]
删除键password:0
判断password是否存在: true
查看键username锁存储的类型: string
随机返回key空间的一个:username
重命名key: OK
取出改后的name: chen
按索引查询: OK
删除当前选择数据库中的所有key: OK
返回当前数据库中key的数目: 0
删除所有数据库中的所有key: OK
String
package com.cyz;
import redis.clients.jedis.Jedis;
import java.util.concurrent.TimeUnit;
public class TestString {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("===========增加数据===========");
System.out.println(jedis.set("key1","value1"));
System.out.println(jedis.set("key2","value2"));
System.out.println(jedis.set("key3", "value3"));
System.out.println("删除键key2:"+jedis.del("key2"));
System.out.println("获取键key2:"+jedis.get("key2"));
System.out.println("修改key1:"+jedis.set("key1", "value1Changed"));
System.out.println("获取key1的值:"+jedis.get("key1"));
System.out.println("在key3后面加入值:"+jedis.append("key3", "End"));
System.out.println("key3的值:"+jedis.get("key3"));
System.out.println("增加多个键值对:"+jedis.mset("key01","value01","key02","value02","key03","value03"));
System.out.println("获取多个键值对:"+jedis.mget("key01","key02","key03"));
System.out.println("获取多个键值对:"+jedis.mget("key01","key02","key03","key04"));
System.out.println("删除多个键值对:"+jedis.del("key01","key02"));
System.out.println("获取多个键值对:"+jedis.mget("key01","key02","key03"));
jedis.flushDB();
System.out.println("===========新增键值对防止覆盖原先值==============");
System.out.println(jedis.setnx("key1", "value1"));
System.out.println(jedis.setnx("key2", "value2"));
System.out.println(jedis.setnx("key2", "value2-new"));
System.out.println(jedis.get("key1"));
System.out.println(jedis.get("key2"));
System.out.println("===========新增键值对并设置有效时间=============");
System.out.println(jedis.setex("key3", 2, "value3"));
System.out.println(jedis.get("key3"));
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(jedis.get("key3"));
System.out.println("===========获取原值,更新为新值==========");
System.out.println(jedis.getSet("key2", "key2GetSet"));
System.out.println(jedis.get("key2"));
System.out.println("获得key2的值的字串:"+jedis.getrange("key2", 2, 4));
}
}
===========增加数据===========
OK
OK
OK
删除键key2:1
获取键key2:null
修改key1:OK
获取key1的值:value1Changed
在key3后面加入值:9
key3的值:value3End
增加多个键值对:OK
获取多个键值对:[value01, value02, value03]
获取多个键值对:[value01, value02, value03, null]
删除多个键值对:2
获取多个键值对:[null, null, value03]
===========新增键值对防止覆盖原先值==============
1
1
0
value1
value2
===========新增键值对并设置有效时间=============
OK
value3
null
===========获取原值,更新为新值==========
value2
key2GetSet
获得key2的值的字串:y2G
List
package com.cyz;
import redis.clients.jedis.Jedis;
public class TestList {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("===========添加一个list===========");
jedis.lpush("collections", "ArrayList", "Vector", "Stack", "HashMap", "WeakHashMap", "LinkedHashMap");
jedis.lpush("collections", "HashSet");
jedis.lpush("collections", "TreeSet");
jedis.lpush("collections", "TreeMap");
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));//-1代表倒数第一个元素,-2代表倒数第二个元素,end为-1表示查询全部
System.out.println("collections区间0-3的元素:"+jedis.lrange("collections",0,3));
System.out.println("===============================");
// 删除列表指定的值 ,第二个参数为删除的个数(有重复时),后add进去的值先被删,类似于出栈
System.out.println("删除指定元素个数:"+jedis.lrem("collections", 2, "HashMap"));
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));
System.out.println("删除下表0-3区间之外的元素:"+jedis.ltrim("collections", 0, 3));
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));
System.out.println("collections列表出栈(左端):"+jedis.lpop("collections"));
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));
System.out.println("collections添加元素,从列表右端,与lpush相对应:"+jedis.rpush("collections", "EnumMap"));
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));
System.out.println("collections列表出栈(右端):"+jedis.rpop("collections"));
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));
System.out.println("修改collections指定下标1的内容:"+jedis.lset("collections", 1, "LinkedArrayList"));
System.out.println("collections的内容:"+jedis.lrange("collections", 0, -1));
System.out.println("===============================");
System.out.println("collections的长度:"+jedis.llen("collections"));
System.out.println("获取collections下标为2的元素:"+jedis.lindex("collections", 2));
System.out.println("===============================");
jedis.lpush("sortedList", "3","6","2","0","7","4");
System.out.println("sortedList排序前:"+jedis.lrange("sortedList", 0, -1));
System.out.println(jedis.sort("sortedList"));
System.out.println("sortedList排序后:"+jedis.lrange("sortedList", 0, -1));
}
}
===========添加一个list===========
collections的内容:[TreeMap, TreeSet, HashSet, LinkedHashMap, WeakHashMap, HashMap, Stack, Vector, ArrayList]
collections区间0-3的元素:[TreeMap, TreeSet, HashSet, LinkedHashMap]
===============================
删除指定元素个数:1
collections的内容:[TreeMap, TreeSet, HashSet, LinkedHashMap, WeakHashMap, Stack, Vector, ArrayList]
删除下表0-3区间之外的元素:OK
collections的内容:[TreeMap, TreeSet, HashSet, LinkedHashMap]
collections列表出栈(左端):TreeMap
collections的内容:[TreeSet, HashSet, LinkedHashMap]
collections添加元素,从列表右端,与lpush相对应:4
collections的内容:[TreeSet, HashSet, LinkedHashMap, EnumMap]
collections列表出栈(右端):EnumMap
collections的内容:[TreeSet, HashSet, LinkedHashMap]
修改collections指定下标1的内容:OK
collections的内容:[TreeSet, LinkedArrayList, LinkedHashMap]
===============================
collections的长度:3
获取collections下标为2的元素:LinkedHashMap
===============================
sortedList排序前:[4, 7, 0, 2, 6, 3]
[0, 2, 3, 4, 6, 7]
sortedList排序后:[4, 7, 0, 2, 6, 3]
Set
package com.cyz;
import redis.clients.jedis.Jedis;
public class TestSet {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("============向集合中添加元素(不重复)============");
System.out.println(jedis.sadd("eleSet", "e1","e2","e4","e3","e0","e8","e7","e5"));
System.out.println(jedis.sadd("eleSet", "e6"));
System.out.println(jedis.sadd("eleSet", "e6"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("删除一个元素e0:"+jedis.srem("eleSet", "e0"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("删除两个元素e7和e6:"+jedis.srem("eleSet", "e7","e6"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("随机的移除集合中的一个元素:"+jedis.spop("eleSet"));
System.out.println("随机的移除集合中的一个元素:"+jedis.spop("eleSet"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("eleSet中包含元素的个数:"+jedis.scard("eleSet"));
System.out.println("e3是否在eleSet中:"+jedis.sismember("eleSet", "e3"));
System.out.println("e1是否在eleSet中:"+jedis.sismember("eleSet", "e1"));
System.out.println("e1是否在eleSet中:"+jedis.sismember("eleSet", "e5"));
System.out.println("=================================");
System.out.println(jedis.sadd("eleSet1", "e1","e2","e4","e3","e0","e8","e7","e5"));
System.out.println(jedis.sadd("eleSet2", "e1","e2","e4","e3","e0","e8"));
System.out.println("将eleSet1中删除e1并存入eleSet3中:"+jedis.smove("eleSet1", "eleSet3", "e1"));//移到集合元素
System.out.println("将eleSet1中删除e2并存入eleSet3中:"+jedis.smove("eleSet1", "eleSet3", "e2"));
System.out.println("eleSet1中的元素:"+jedis.smembers("eleSet1"));
System.out.println("eleSet3中的元素:"+jedis.smembers("eleSet3"));
System.out.println("============集合运算=================");
System.out.println("eleSet1中的元素:"+jedis.smembers("eleSet1"));
System.out.println("eleSet2中的元素:"+jedis.smembers("eleSet2"));
System.out.println("eleSet1和eleSet2的交集:"+jedis.sinter("eleSet1","eleSet2"));
System.out.println("eleSet1和eleSet2的并集:"+jedis.sunion("eleSet1","eleSet2"));
System.out.println("eleSet1和eleSet2的差集:"+jedis.sdiff("eleSet1","eleSet2"));//eleSet1中有,eleSet2中没有
jedis.sinterstore("eleSet4","eleSet1","eleSet2");//求交集并将交集保存到dstkey的集合
System.out.println("eleSet4中的元素:"+jedis.smembers("eleSet4"));
}
}
============向集合中添加元素(不重复)============
8
1
0
eleSet的所有元素为:[e3, e6, e5, e2, e1, e7, e8, e0, e4]
删除一个元素e0:1
eleSet的所有元素为:[e3, e6, e5, e2, e1, e7, e8, e4]
删除两个元素e7和e6:2
eleSet的所有元素为:[e3, e5, e2, e1, e8, e4]
随机的移除集合中的一个元素:e1
随机的移除集合中的一个元素:e2
eleSet的所有元素为:[e3, e5, e8, e4]
eleSet中包含元素的个数:4
e3是否在eleSet中:true
e1是否在eleSet中:false
e1是否在eleSet中:true
=================================
8
6
将eleSet1中删除e1并存入eleSet3中:1
将eleSet1中删除e2并存入eleSet3中:1
eleSet1中的元素:[e3, e5, e7, e8, e0, e4]
eleSet3中的元素:[e2, e1]
============集合运算=================
eleSet1中的元素:[e3, e5, e7, e8, e0, e4]
eleSet2中的元素:[e3, e2, e1, e8, e0, e4]
eleSet1和eleSet2的交集:[e3, e8, e0, e4]
eleSet1和eleSet2的并集:[e3, e2, e5, e1, e4, e0, e8, e7]
eleSet1和eleSet2的差集:[e5, e7]
eleSet4中的元素:[e3, e4, e0, e8]
Hash
package com.cyz;
import redis.clients.jedis.Jedis;
import java.util.HashMap;
import java.util.Map;
public class TestHash {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
Map<String,String> map = new HashMap<String,String>();
map.put("key1","value1");
map.put("key2","value2");
map.put("key3","value3");
map.put("key4","value4");
//添加名称为hash(key)的hash元素
jedis.hmset("hash",map);
//向名称为hash的hash中添加key为key5,value为value5元素
jedis.hset("hash", "key5", "value5");
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));//return Map<String,String>
System.out.println("散列hash的所有键为:"+jedis.hkeys("hash"));//return Set<String>
System.out.println("散列hash的所有值为:"+jedis.hvals("hash"));//return List<String>
System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:"+jedis.hincrBy("hash", "key6", 6));
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));
System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:"+jedis.hincrBy("hash", "key6", 3));
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));
System.out.println("删除一个或者多个键值对:"+jedis.hdel("hash", "key2"));
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));
System.out.println("散列hash中键值对的个数:"+jedis.hlen("hash"));
System.out.println("判断hash中是否存在key2:"+jedis.hexists("hash","key2"));
System.out.println("判断hash中是否存在key3:"+jedis.hexists("hash","key3"));
System.out.println("获取hash中的值:"+jedis.hmget("hash","key3"));
System.out.println("获取hash中的值:"+jedis.hmget("hash","key3","key4"));
}
}
散列hash的所有键值对为:{key1=value1, key2=value2, key5=value5, key3=value3, key4=value4}
散列hash的所有键为:[key1, key2, key5, key3, key4]
散列hash的所有值为:[value2, value1, value3, value4, value5]
将key6保存的值加上一个整数,如果key6不存在则添加key6:6
散列hash的所有键值对为:{key1=value1, key2=value2, key5=value5, key6=6, key3=value3, key4=value4}
将key6保存的值加上一个整数,如果key6不存在则添加key6:9
散列hash的所有键值对为:{key1=value1, key2=value2, key5=value5, key6=9, key3=value3, key4=value4}
删除一个或者多个键值对:1
散列hash的所有键值对为:{key1=value1, key5=value5, key6=9, key3=value3, key4=value4}
散列hash中键值对的个数:5
判断hash中是否存在key2:false
判断hash中是否存在key3:true
获取hash中的值:[value3]
获取hash中的值:[value3, value4]
事务
package com.cyz;
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class TestTX {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","kuangshen");
// 开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
// jedis.watch(result)
try {
multi.set("user1",result);
multi.set("user2",result);
int i = 1/0 ; // 代码抛出异常事务,执行失败!
multi.exec(); // 执行事务!
} catch (Exception e) {
multi.discard(); // 放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close(); // 关闭连接
}
}
}
//成功
{"name":"kuangshen","hello":"world"}
{"name":"kuangshen","hello":"world"}
//失败
java.lang.ArithmeticException: / by zero
at com.cyz.TestTX.main(TestTX.java:23)
null
null
SpringBoot整合
-
环境
-
工具 + web +redis
-
jedis替换为了lettuce
-
jedis: 直连, 多个线程操作不安全, 避免不安全, 需要使用jedis pool 连接池
-
lettuce: 采用netty, 实例可以在多个线程中进行分享, 不存在线程不安全的情况, 可减少线程数量
-
-
整合测试
-
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
-
配置
spring.redis.host=127.0.0.1 spring.redis.port=6379
-
测试
package com.cyz;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class Redis02SpringbootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
// 在企业开发中,我们80%的情况下,都不会使用这个原生的方式去编写代码!
// RedisUtils;
// redisTemplate 操作不同的数据类型,api和我们的指令是一样的
// opsForValue 操作字符串 类似String
// opsForList 操作List 类似List
// opsForSet
// opsForHash
// opsForZSet
// opsForGeo
// opsForHyperLogLog
// 除了进本的操作,我们常用的方法都可以直接通过redisTemplate操作,比如事务,和基本的CRUD
// 获取redis的连接对象
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushDb();
// connection.flushAll();
redisTemplate.opsForValue().set("mykey","关注狂神说公众号");
System.out.println(redisTemplate.opsForValue().get("mykey"));
}
}
-
pojo
package com.cyz.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
@Component
@AllArgsConstructor
@NoArgsConstructor
@Data
// 在企业中,我们的所有 pojo 都会序列化!SpringBoot
public class User{
private String name;
private int age;
}
-
测试类
@Test
public void test() throws JsonProcessingException {
// 真实的开发一般都使用json来传递对象
User user = new User("狂神说", 3);
//如果直接掺入对象 会报错 需要序列化
// redisTemplate.opsForValue().set("user",user);
String jsonUser = new ObjectMapper().writeValueAsString(user);
redisTemplate.opsForValue().set("user",jsonUser);
System.out.println(redisTemplate.opsForValue().get("user"));
}
-
序列化pojo
package com.cyz.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
import java.io.Serializable;
@Component
@AllArgsConstructor
@NoArgsConstructor
@Data
// 在企业中,我们的所有 pojo 都会序列化!SpringBoot
public class User implements Serializable {
private String name;
private int age;
}
-
测试类
@Test
public void test() throws JsonProcessingException {
// 真实的开发一般都使用json来传递对象
User user = new User("狂神说", 3);
// String jsonUser = new ObjectMapper().writeValueAsString(user);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
-
自定义配置类
package com.cyz.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
//springboot默认使用的是jdk序列化
// 这是我给大家写好的一个固定模板,大家在企业中,拿去就可以直接使用!
// 自己定义了一个 RedisTemplate
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 我们为了自己开发方便,一般直接使用 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
//用于忽略未知属性的映射,比如没有get和set的属性
//om.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES,false);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
-
测试类
package com.cyz;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class Redis02SpringbootApplicationTests {
@Autowired
@Qualifier("redisTemplate")
private RedisTemplate redisTemplate;
@Test
public void test() throws JsonProcessingException {
// 真实的开发一般都使用json来传递对象
User user = new User("狂神说", 3);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
}
-
工具类
package com.cyz.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
// 在我们真实的分发中,或者你们在公司,一般都可以看到一个公司自己封装RedisUtil
@Component
public final class RedisUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// =============================common============================
/**
* 指定缓存失效时间
* @param key 键
* @param time 时间(秒)
*/
public boolean expire(String key, long time) {
try {
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据key 获取过期时间
* @param key 键 不能为null
* @return 时间(秒) 返回0代表为永久有效
*/
public long getExpire(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* 判断key是否存在
* @param key 键
* @return true 存在 false不存在
*/
public boolean hasKey(String key) {
try {
return redisTemplate.hasKey(key);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除缓存
* @param key 可以传一个值 或多个
*/
@SuppressWarnings("unchecked")
public void del(String... key) {
if (key != null && key.length > 0) {
if (key.length == 1) {
redisTemplate.delete(key[0]);
} else {
redisTemplate.delete(CollectionUtils.arrayToList(key));
}
}
}
// ============================String=============================
/**
* 普通缓存获取
* @param key 键
* @return 值
*/
public Object get(String key) {
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* 普通缓存放入
* @param key 键
* @param value 值
* @return true成功 false失败
*/
public boolean set(String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 普通缓存放入并设置时间
* @param key 键
* @param value 值
* @param time 时间(秒) time要大于0 如果time小于等于0 将设置无限期
* @return true成功 false 失败
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 递增
* @param key 键
* @param delta 要增加几(大于0)
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递增因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* 递减
* @param key 键
* @param delta 要减少几(小于0)
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递减因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
* @param key 键 不能为null
* @param item 项 不能为null
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 获取hashKey对应的所有键值
* @param key 键
* @return 对应的多个键值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
* @param key 键
* @param map 对应多个键值
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet 并设置时间
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除hash表中的值
*
* @param key 键 不能为null
* @param item 项 可以使多个 不能为null
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判断hash表中是否有该项的值
*
* @param key 键 不能为null
* @param item 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
*
* @param key 键
* @param item 项
* @param by 要增加几(大于0)
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash递减
*
* @param key 键
* @param item 项
* @param by 要减少记(小于0)
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* 根据key获取Set中的所有值
* @param key 键
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根据value从一个set中查询,是否存在
*
* @param key 键
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将数据放入set缓存
*
* @param key 键
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 将set数据放入缓存
*
* @param key 键
* @param time 时间(秒)
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 获取set缓存的长度
*
* @param key 键
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 移除值为value的
*
* @param key 键
* @param values 值 可以是多个
* @return 移除的个数
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ===============================list=================================
/**
* 获取list缓存的内容
*
* @param key 键
* @param start 开始
* @param end 结束 0 到 -1代表所有值
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 获取list缓存的长度
*
* @param key 键
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 通过索引 获取list中的值
*
* @param key 键
* @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
* @param key 键
* @param value 值
* @param time 时间(秒)
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据索引修改list中的某条数据
*
* @param key 键
* @param index 索引
* @param value 值
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 移除N个值为value
*
* @param key 键
* @param count 移除多少个
* @param value 值
* @return 移除的个数
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}
-
测试
@Autowired
private RedisUtil redisUtil;
@Test
public void test1(){
redisUtil.set("name","kuangshen");
System.out.println(redisUtil.get("name"));
}
Redis.conf详解
单位: 配置文件对大小写不敏感 可以导入其他配置文件 include 网络: bind 127.0.0.1 # 绑定的ip protected-mode yes #保护模式 port 6379 # 端口设置 通用 GENERAL : daemonize yew # 以守护进程的方式运行, 默认为no pidfile /var/run/redis_6379.pid # 如果使用欧泰的方式运行, 我们就要指定一个pid文件 # 日志 # debug # verbose # notice # warning loglevel notice logfile "" # 日志的文件位置名 databases 16 # 默认数据库数量 always-show-logo yes #是否总是显示LOGO 快照: 持久化, 在规定的时间内, 执行了多少次操作, 则会持久化到文件 .rdb, .aof redis是内存数据库, 如果没有持久化, 那么数据断电即失 save 900 1 # 如果900s 内至少有1个 key 进行了修改, 就进行持久化操作 save 300 10 # 如果300s 内至少有10个 key 进行了修改, 就进行持久化操作 save 60 10000 # 如果60s 内至少有10000个 key 进行了修改, 就进行持久化操作 stop-writes-on-bgsave-error yes # 持久化如果出错, 是否需要继续工作 rdbcompression yes # 是否压缩 rddb 文件, 需要消耗一些cpu资源 rdbchecksum yes # 保存rdb文件的时候, 进行错误的检查校验 dir ./ # rdb 文件保存的目录 主从复制: REOLICATION SECURITY 安全: requirepass 获取密码: config get requirepass 设置密码: config set requirepass "123456" 登录认证: auth 123456 限制 CLIENTS: maxclients 10000 # redis最大客户端数量 maxmemory <bytes> # redis 配置最大的内存容量 maxmemory-policy noeviction # 内存到达上线之后的处理策略 1. volatile-lru: 只对设置了过期时间的key进行LRU(默认值) 2. allkeys-lru: 删除lru算法的key 3. volatile-random: 随机删除即将过期key 4. allkeys-random: 随机删除 5. volatile-ttl: 删除即将过期的 6. noeviction: 永不过期, 返回错误 APPEND ONLY aof配置 appendonly no # 默认是不开启aof模式的, 默认是使用rdb方式持久化的 appendfilename "appendonly.aof" # 持久化额文件名字 # appendfsync always #每次修改都会sync 消耗性能 appendfsync everysec # 每秒执行一次sync 可能会丢失这一秒的数据 # appendfsync no # 不执行sync 这时候操作系统自己同步数据, 速度最快
Redis持久化
-
内存数据库, 断电即失
RDB(默认)
-
在指定的时间间隔内将内存中的数集快照写入磁盘, 恢复是就将快照写入即可
-
Redis会单独的创建(fork)一个子进程来进行持久化, 会先将数据写入到一个临时文件, 带持久化过程都结束了, 在拿这个临时文件替换上次持久化好的文件.
-
整个过程中, 主进程是不进行任何的IO操作, 性能高
-
如果需要进行大规模的数据恢复, 且对数据恢复的完整性不是非常敏感, 那么RDB方比AOF方式更加的高效
-
缺点: 是最后一次持久化后的数据有可能丢失
rdb保存的文件: dump.rdb ==
dbfilename: dump.rdb
触发机制(生成dump.rdb)
-
save规则满足
-
flushall命令执行
-
退出redis
恢复
-
只需要放在我们redis启动目录就可以, redis启动的时候就会自动检查dump.rdb恢复其中的数据
-
查看
127.0.0.1:6739> config get dir 1) "dir" 2) "/usr/local/bin"
优点
-
适合大规模的数据恢复
-
对数据完整性要求不高
缺点
-
需要一定的时间间隔进行操作! 如果redis意外宕机, 这个最后一次修改数据就没有了
-
fork进程的时候, 会占用一定的内存空间
AOF操作
-
将我们的所有命令记录下来
-
恢复的时候在执行一遍命令
appendonly.aof文件
-
配置
appendonly no # 默认为no
-
aof文件错误导致启动不了redis
修复: redis-check-aof 并不完全修复 redis-check-aof -fix appendonly.aofs
-
重写规则
如果aof的文件大于64m 太大了, fork一个新的进程来将文我们的文件进行重写 no-appendfsync-on-rewrite no # 默认无限追加 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
优点
-
每一次修改都同步, 文件的完整会更加好
-
每秒同步一次, 可能会丢失1秒的数据
-
从不同步, 效率最高的
缺点
-
相对于数据文件来说, aof远远大于edb, 修复的速度比rdb慢
-
aof运行效率也要比rdb慢, 所以我们redis默认的配置就是rdb持久化
扩展


发布订阅
-
消息通信模式
-
消息发送者-----频道----消息订阅者
客户端1: subscribe chen # 订阅频道 1) "subscribe" 2) "chen" 3) (integet) 1 客户端2: publish chen "hello,chen" # 发送消息 客户端1: subscribe chen # 订阅频道 1) "subscribe" 2) "chen" 3) (integet) 1 # 等待接收消息 1) "message" # 消息 2) "chen" # 频道 3) "hello,chen" # 内容
使用场景
-
实时消息系统
-
实时聊天
-
订阅, 关注系统
稍微复杂的场景使用消息队列MQ
Redis主从复制
-
将一台Redis服务器的数据(主节点), 复制到其他Redis服务器(从节点)
-
数据单向: 主机负责写, 从机负责读
-
主从复制, 读写分离, 减缓服务器压力 一般是 一主二从
主从复制的作用
-
数据冗余: 数据热备份, 持久化之外的一种数据冗余方式
-
故障恢复: 服务冗余, 当主节点出现问题时, 可以从从节点提供服务
-
负载均衡: 读写分离, 主写从读, 提高并发量
-
高可用(集群)基石: 哨兵和集群能够实施的基础
环境搭建
-
redis默认自己就是主库, 所以只用配置从库
# 查看当前库的信息 info replication role:master # 角色: master connected_slaves:0 # 没有从机
# 需要4台客户端 # 拷贝配置文件 cp redis.conf redis79.conf cp redis.conf redis80.conf cp redis.conf redis81.conf 分别配置端口: 6379 6380 6381 开启守护进程: daemonize yes pridfie /var/run/redis_6379.pid # 修改pid文件 修改日志文件位置 logfile "6379.log" # 修改日志文件 修改rdb文件 dbfilename dump6379.rdb #修改dump.rdb文件 分别3个进程启动3个服务 redis-server kconfig/redis79.conf redis-server kconfig/redis80.conf redis-server kconfig/redis81.conf
主从复制
测试三台是否ping通, 并查看当前库信息 ping info replication 一般只需要被从机就好 选择主机(79) 从机(80, 81) 在从机中 找主机6379 SLAVEOF 127.0.0.1 6379 info replication # 主机查看 info replication # 显示库信息 看到从机列表 真实开发在配置文件中配置, 命令配置是暂时的 配置文件: repliceof 127.0.0.1 6379 # 主机地址ip + 端口 masterauth "123456" # 密码 测试: 在主机79 设置key: set k1 v1 # 主机写入 在从机80/81 查询 keys * 和 get k1 测试从机写入key set k2 v2 # 报错 从机只读 # 主机79宕机: shutdown # 从机依然可连接到数据, 不可写入了 # 主机重新启动时, 从机依然可以连接到 # 从机宕机后重启, 如果是命令是设置的从机, 重启会将从机重置为新的主机 # 从机重启后需要重新配置从机
复制原理
Slave启动成功连接到master后会发送一个sync同步命令 Master接到命令, 启动后台的存盘进程, 同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后, master将传送整个数据文件到slave, 并完成一次完全同步. 全量赋值: 而slave服务在接收到数据库文件数据后, 将其存盘并加载到内存中 增量赋值: Master继续将新的所有收集到的修改命令依次传给slave, 完成同步 但是只要是重新连接master, 一次完全同步(全量复制) 将被自动执行 我们的数据一定可以在从机中看到
层层链路
-
当改成79连着80, 80连着81的形式, 这里80还是从节点 而不是主节点, 所以也不能写入数据
原主机宕机后手动配置主机
-
谋权篡位
-
从机执行: slavef no one 变为主节点
slavef no one # 变为主节点 # 如果真正的主机修复了, 需要重新配置
哨兵模式
-
自动选举老大的模式
-
主从切换技术的方法是: 当主服务器宕机后, 需要手动把一台服务器切换为主服务器, 这就需要人工干预, 费时费力, 还造成一段时间服务器不可用, 这是后就需要使用哨兵模式
-
能够后台监控主机是否故障, 如果故障了通过投票数来判断谁转为主库
-
哨兵是一个独立的进程, 独立运行
-
原理: 哨兵通过发送命令, 等待Redis服务器响应, 从而监控运行的多个redis实例
-
如果命令没有回复, 就是故障了
-
-
哨兵不止设置一个, 防止一个哨兵故障了(多哨兵模式互相监控)
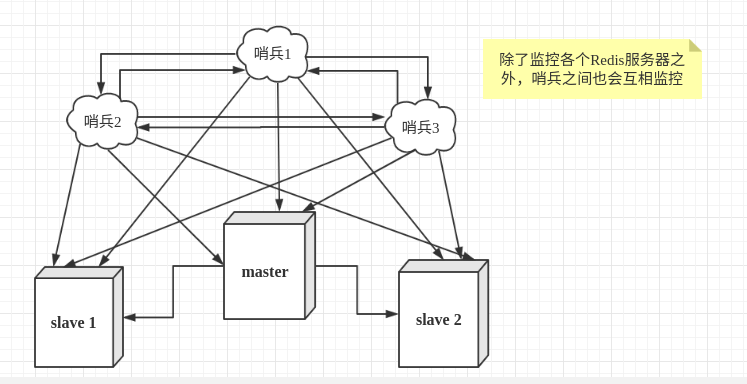
3个哨兵互相监控 一个主机 2个从机 假设主服务器宕机了, 哨兵1先检测到结果, 系统并不会马上进行failover[故障转移]过程, 仅仅是哨兵1主观的认为服务器不可用, 这个现象称为 # 主观下线 当后面额哨兵也检测到主服务器不可用, 并且数量达到一定的值时, 那么哨兵之间就会进行一次投票, 投票的结果由一个哨兵发起, 进行failover操作, 切换成功后, 就会通过发布订阅模式, 让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为 # 客观下线
测试
-
在kconfig下新建sentinel.ocnf
sentinel monitor myredis 127.0.0.1 6379 1 # 配置监控主机 1表示宕机投票数 # 被监控名称
-
启动哨兵
redis-sentinel kconfig/sentinel.conf
# 一主二从 # 模拟宕机, 观察哨兵日志 # 这时候重新连接原来的主机, 原主机会变为新主机的从机
-
哨兵模式规则: 重新连接原来的主机, 原主机会变为新主机的从机
优点
-
哨兵集群, 基于主从复制模式, 所有的主从配置优点, 它全有
-
主从可以切换, 故障可以转移, 系统的可用性就会更好
-
哨兵模式就是主从模式的升级, 手动到自动, 更加健壮
缺点
-
Redis不好在线扩容的, 集群容量一旦到达上限, 在线扩容就十分麻烦
-
实现哨兵模式的配置起始是很麻烦的, 里面有很多的选择
# Example sentinel.conf # 哨兵sentinel实例运行的端口 默认26379 port 26379 # 如果有多个哨兵就需要配置多个配置文件 端口不同 # 哨兵sentinel的工作目录 dir /tmp # 哨兵sentinel监控的redis主节点的 ip port # master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。 # quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了 # sentinel monitor <master-name> <ip> <redis-port> <quorum> sentinel monitor mymaster 127.0.0.1 6379 2 # 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码 # 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码 # sentinel auth-pass <master-name> <password> sentinel auth-pass mymaster MySUPER--secret-0123passw0rd # 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒 # sentinel down-after-milliseconds <master-name> <milliseconds> sentinel down-after-milliseconds mymaster 30000 # 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步, 这个数字越小,完成failover所需的时间就越长, 但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。 可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 # sentinel parallel-syncs <master-name> <numslaves> sentinel parallel-syncs mymaster 1 # 故障转移的超时时间 failover-timeout 可以用在以下这些方面: #1. 同一个sentinel对同一个master两次failover之间的间隔时间。 #2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。 #3.当想要取消一个正在进行的failover所需要的时间。 #4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了 # 默认三分钟 # sentinel failover-timeout <master-name> <milliseconds> sentinel failover-timeout mymaster 180000 # SCRIPTS EXECUTION #配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。 #对于脚本的运行结果有以下规则: #若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10 #若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。 #如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。 #一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。 #通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。 #通知脚本 # shell编程 # sentinel notification-script <master-name> <script-path> sentinel notification-script mymaster /var/redis/notify.sh # 客户端重新配置主节点参数脚本 # 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。 # 以下参数将会在调用脚本时传给脚本: # <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> # 目前<state>总是“failover”, # <role>是“leader”或者“observer”中的一个。 # 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的 # 这个脚本应该是通用的,能被多次调用,不是针对性的。 # sentinel client-reconfig-script <master-name> <script-path> sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # 一般都是由运维来配置!
Redis缓存穿透和雪崩
服务的高可用问题!
# 在这里我们不会详细的区分析解决方案的底层! # Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。 # 另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。
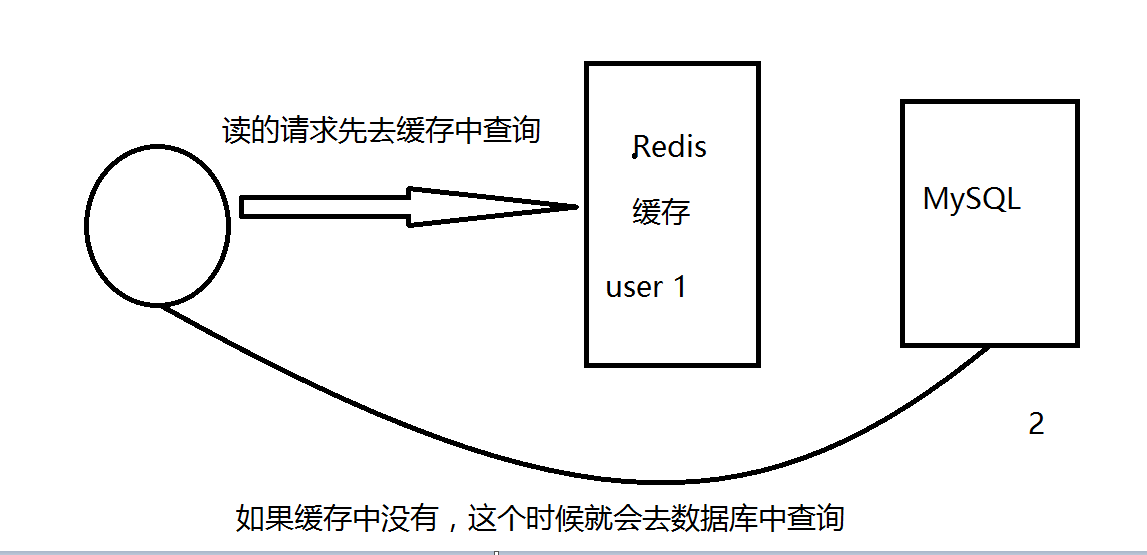
缓存穿透(查不到)
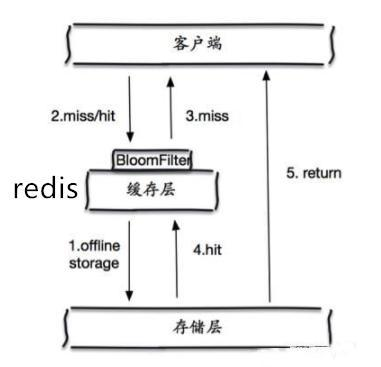
概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒杀!),于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
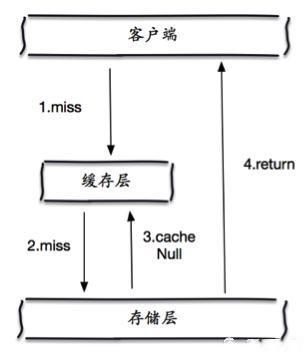
但是这种方法会存在两个问题:
-
如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
-
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(量太大,缓存过期!)
概述
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大。
解决方案
设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
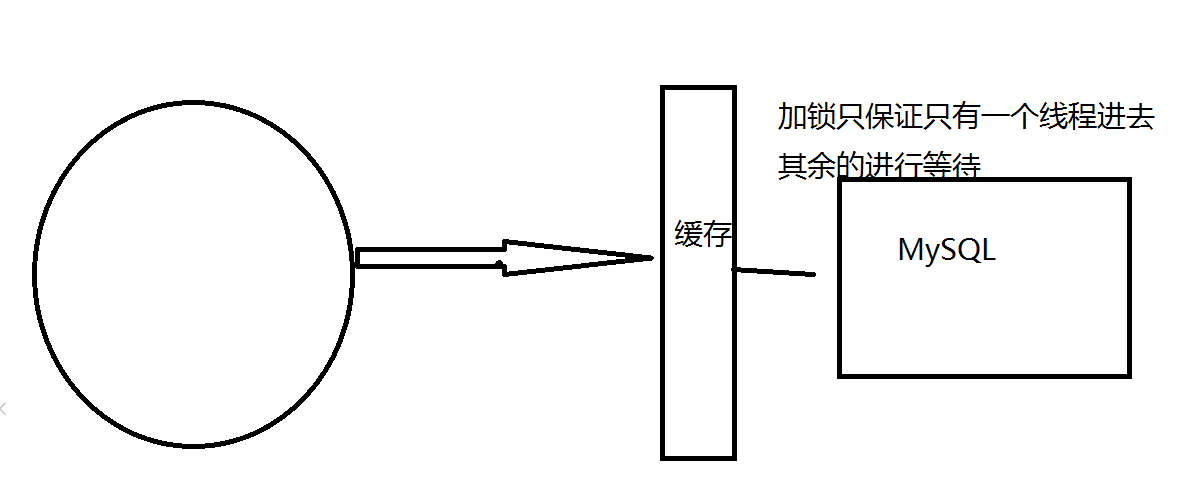
加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
概念
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis 宕机!
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
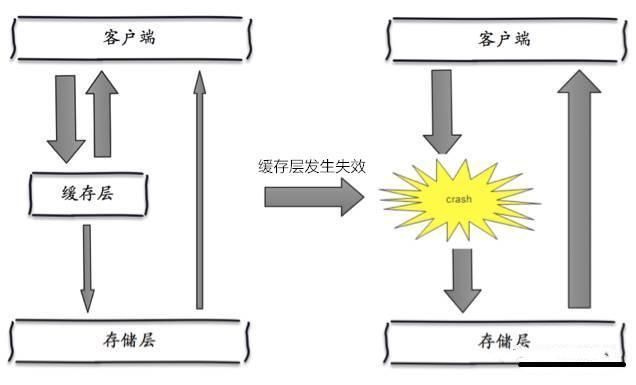
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。(异地多活!)
限流降级(在SpringCloud讲解过!)
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
