2017级系统综合实践第4次实践作业
使用Docker-compose实现Tomcat+Nginx负载均衡
(1)理解nginx反向代理原理;
正向代理是代理客户端,为客户端收发请求,使真实客户端对服务器不可见;而反向代理是代理服务器端,为服务器收发请求,使真实服务器对客户端不可见。
反向代理(Reverse Proxy)方式是指以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器;并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
(2) nginx代理tomcat集群,代理2个以上tomcat;
- 树形结构
├── docker-compose.yml
├── nginx
│ └── default.conf
├── tomcat1
│ └── index.html
├── tomcat2
│ └── index.html
└── tomcat3
└── index.html
- docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: "nginx-tomcat"
ports:
- 80:8085
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: "tomcat01"
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: "tomcat02"
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: "tomcat03"
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
- nginx配置default.conf
upstream tomcats {
server tomcat01:8080;
server tomcat02:8080;
server tomcat03:8080;
}
server {
listen 8085;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
- index.htlm文件
tomcat1的html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>tomcat</title>
</head>
<body>
<h1>tomcat1</h1>
</body>
tomcat2、tomcat3的html同上
- 构建docker-compose up -d后即可访问localhost
(3)了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略;
unbuntu的Linux系统自带python3,直接利用一个python脚本进行多次访问浏览器测试负载均衡
- 轮询策略
testTomcat.py
import requests
url="http://localhost"
context={}
for i in range(0,100):
response=requests.get(url)
if response.text in context:
context[response.text]+=1
else:
context[response.text]=1
print(context)
修改defaul.conf,将三个tomcat的权重更改为1:2:3
upstream tomcats {
server tomcat1:8080 weight=1; # 容器名,与yml对应
server tomcat2:8080 weight=2;
server tomcat3:8080 weight=3; # 默认使用轮询策略
}
server {
listen 2020;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
restart容器 docker restart nginx-tomcat
运行py脚本查看三个的访问比重与配置文件中的1:2:3基本一致
使用Docker-compose部署javaweb运行环境
(1)分别构建tomcat、数据库等镜像服务;
(2)成功部署Javaweb程序,包含简单的数据库操作;
(3)为上述环境添加nginx反向代理服务,实现负载均衡。
使用Docker搭建大数据集群环境
完成hadoop分布式集群环境配置,至少包含三个节点(一个master,两个slave);
(1)搭建hadoop环境
- 实验环境
ubuntu 18.04 LST
openjdk 1.8
hadoop 3.1.3
- 树形结构
├── Dockerfile
├── build
│ └── hadoop-3.1.3.tar.gz
└── sources.list
- Dockerfile
#Base images 基础镜像
FROM ubuntu:18.04
#MAINTAINER 维护者信息
MAINTAINER lqy
COPY ./sources.list /etc/apt/sources.list
- source.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse
- 创建并运行容器
docker build -t ubuntu:18.04 .
docker run -it --name ubuntu ubuntu:18.04
(2)容器初始化
-
实现ssh无密码登陆
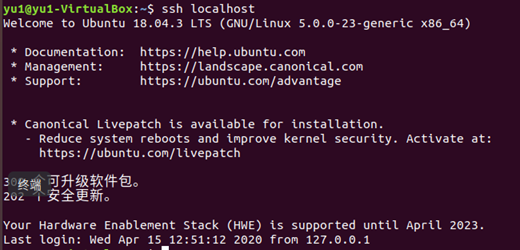
-
配置Hadoop环境变量
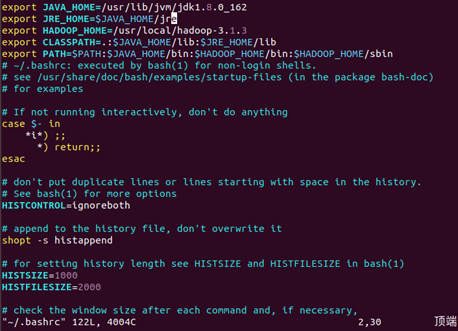
-
确认Hadoop安装配置完成
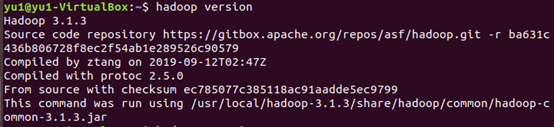
(3)配置hadoop集群(好难好复杂)
(4)构建镜像
docker commit 容器ID ubuntu/hadoop
(5)利用构建好的镜像运行主机
开启三个终端分别运行
# 第一个终端
docker run -it -h master --name master ubuntu/hadoop
# 第二个终端
docker run -it -h slave01 --name slave01 ubuntu/hadoop
# 第三个终端
docker run -it -h slave02 --name slave02 ubuntu/hadoop
分别修改/etc/hosts
根据自己容器的ip地址修改
172.17.0.5 master
172.17.0.3 slave01
172.17.0.4 slave02
相互进行ssh 发现可以到达对方主机
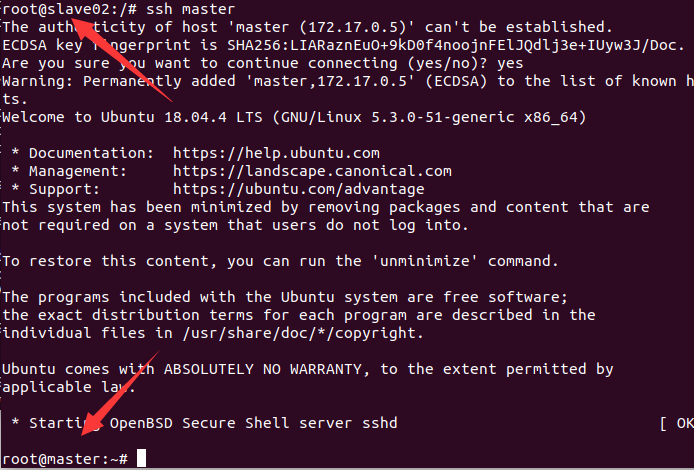
master主机上修改workers
vim /usr/local/hadoop-3.1.3/etc/hadoop/workers
slave01
slave02
开启服务
master上运行:
start-dfs.sh
start-yarn.sh
jps查看服务是否开启成功

成功运行hadoop 自带的测试实例。
grep测试 (大数据实践做过)
hdfs dfs -mkdir -p /user/root/input #新建input文件夹
hdfs dfs -put /usr/local/hadoop-3.1.3/etc/hadoop/*s-site.xml input #将部分文件放入input文件夹
hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+' #运行示例程序grep
hdfs dfs -cat output/* #查看运行结果
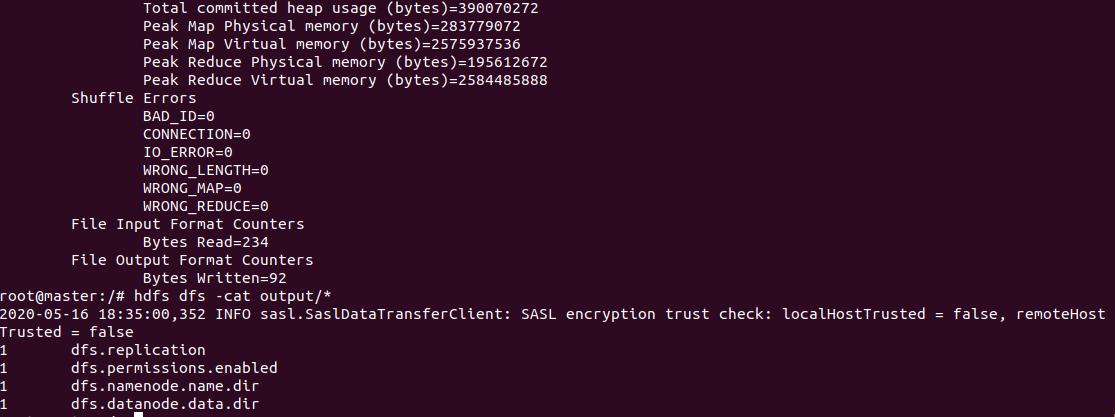
wordcount测试
hdfs dfs -rm root #删除上一次运行的输入和输出
hdfs dfs -mkdir -p /user/root/input #新建input文件夹
vim txt1.txt #在当前目录下新建txt1.txt
vim txt2.txt #在当前目录下新建txt2.txt
hdfs dfs -put ./*.txt input #将新建的文本文件放入input文件夹
hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount input output #运行示例程序wordcount
hdfs dfs -cat output/* #查看运行结果
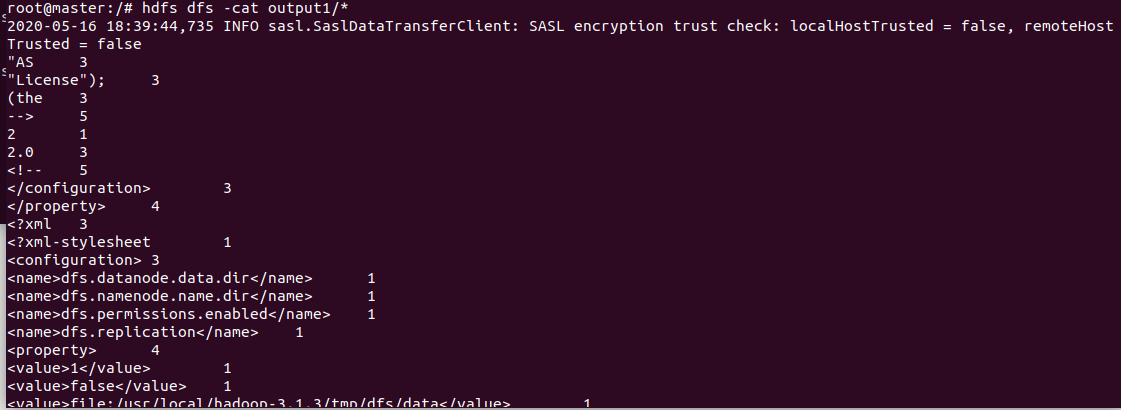
三、主要问题和解决方法和感想
我觉得这次的实验一个顶三个。。。实验二我实在顶不住,还好实验三大数据实验有做过类似的相对来说比较顺利。实验的过程也大都参考前面的同学的步骤,再次致谢,我自己刚开始看题目的时候是真的一脸懵。因为是参照其他人的实验过程,操作做过一遍后我觉得掌握了方法(其实也没太掌握。。。),运行原理什么的认识的还是不都深刻,我得自己找时间再研究研究。
