mysql大小写敏感与校对规则
正文
大家在使用mysql过程中,可能会遇到类似以下的问题:
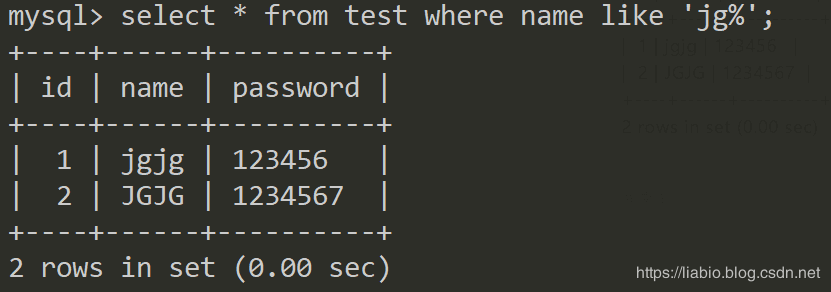
模糊匹配 jg%,结果以JG开头的字符串也出现在结果集中,大家很自然的认为是大小写敏感的问题。那么mysql中大小写敏感是如何控制的;数据库名,表名,字段名这些字典对象以及字段值的大小敏感是如何控制的;以及校验规则与索引的关系,这是本文要讨论的内容。
数据库名、表名:
windows建库:

windows建表:
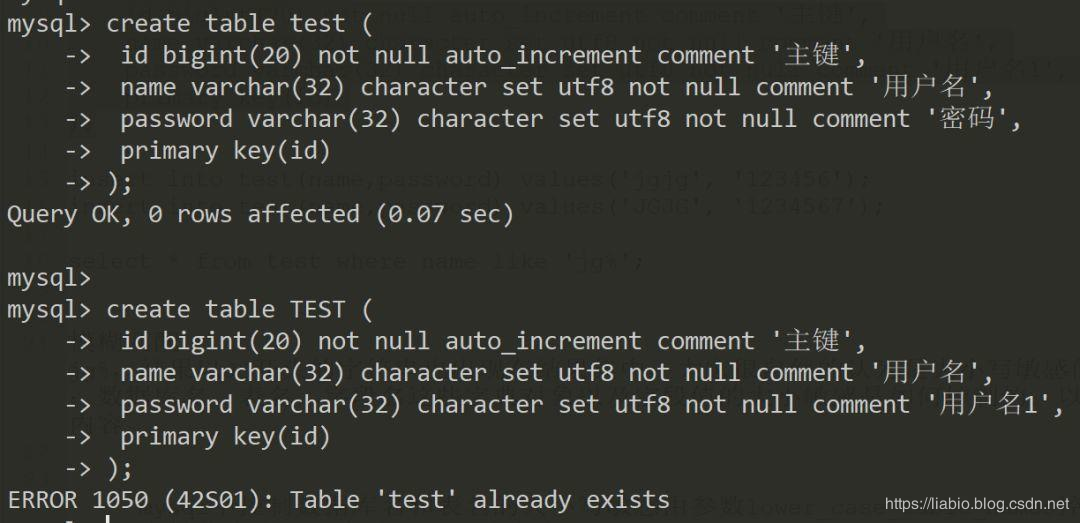
linux建库:
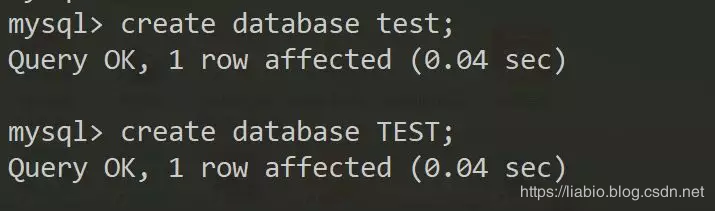
linux建表:
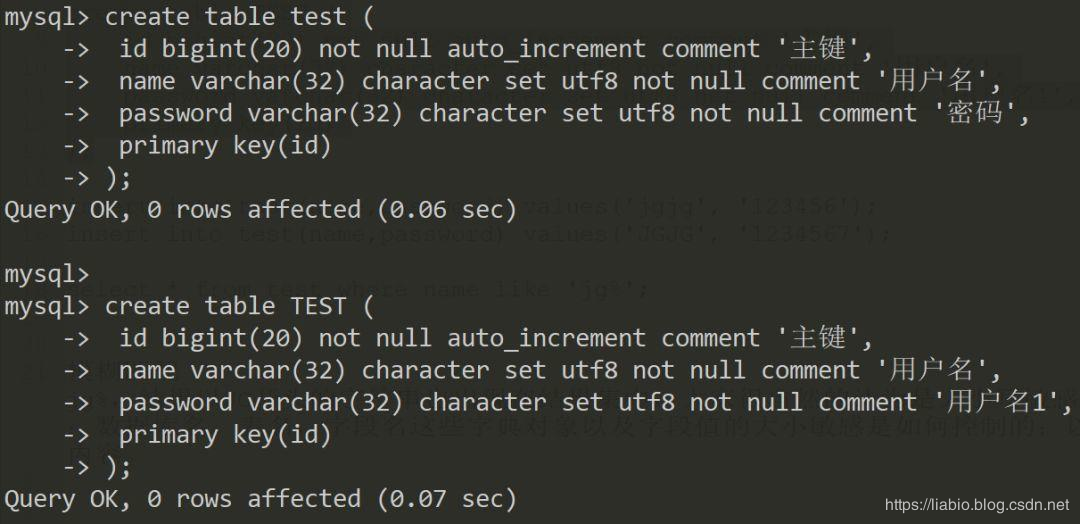
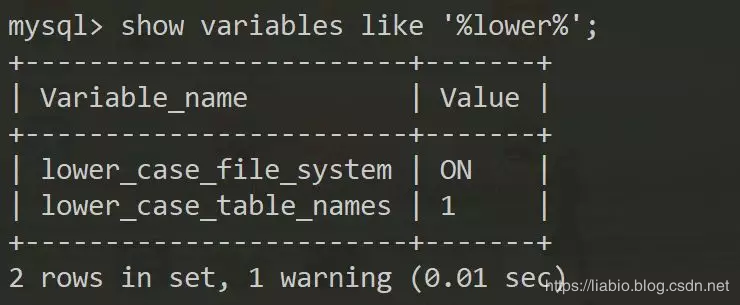
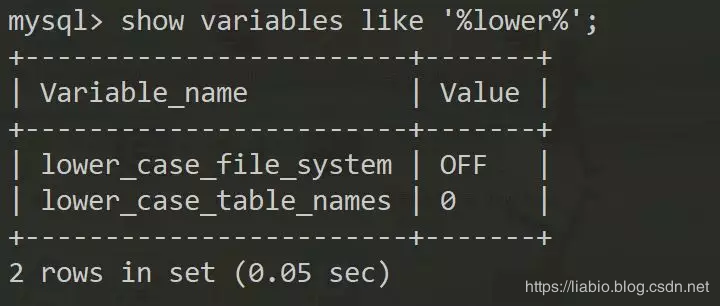
以上可以看出windows下大小写不敏感,linux下是敏感的,故前者不可以同时建test和TEST,而后者可以。
大小写区分规则:
Linux下:
-
数据库名与表名是严格区分大小写的;
-
表的别名是严格区分大小写的;
-
列名与列的别名在所有的情况下均是忽略大小写的;
-
变量名也是严格区分大小写的;
Windows下:
- 都不区分大小写。
Mac OS下,文件系统类型HFS+,非UFS卷:
- 都不区分大小写。
mysql中控制数据库名和表名的大小写敏感由参数lower_case_table_names控制,为0时表示区分大小写,为1时,表示将名字转化为小写后存储,不区分大小写。
在mysql中,数据库对应数据目录中的目录。数据库中的每个表至少对应数据库目录中的一个文件(也可能是多个,取决于存储引擎)。因此,所使用操作系统的大小写敏感性决定了数据库名和表名的大小写敏感性。
lower_case_file_system:
变量说明是否数据目录所在的文件系统对文件名的大小写敏感。ON说明对文件名的大小写不敏感,OFF表示敏感。
lower_case_table_names:
unix下默认值为 0 ;Windows下默认值是 1 ;Mac OS X下默认值是 2
0:使用CREATE TABLE或CREATE DATABASE语句指定的大小写字母在硬盘上保存表名和数据库名。名称比较对大小写敏感。在大小写不敏感的操作系统如windows或Mac OS x上我们不能将该参数设为0,如果在大小写不敏感的文件系统上将此参数强制设为0,并且使用不同的大小写访问MyISAM表名,可能会导致索引破坏。
1:表名在硬盘上以小写保存,名称比较对大小写不敏感。MySQL将所有表名转换为小写在存储和查找表上。该行为也适合数据库名和表的别名。该值为Windows的默认值。
2:表名和数据库名在硬盘上使用CREATE TABLE或CREATE DATABASE语句指定的大小写字母进行保存,但MySQL将它们转换为小写在查找表上。名称比较对大小写不敏感,即按照大小写来保存,按照小写来比较。注释:只在对大小写不敏感的文件系统上适用innodb表名用小写保存。
windows上:
linux上:
为了避免大小写引发的问题,一种推荐的命名规则是:在定义数据库、表、列的时候全部采用小写字母加下划线的方式,不使用任何大写字母。
字段名和字段值:
字段名通常都是不区分大小写的。
字段值的大小写由mysql的校对规则来控制。提到校对规则,就不得不说字符集。字符集是一套符号和编码,校对规则是在字符集内用于比较字符的一套规则,比如定义'A'<'B'这样的关系的规则。不同的字符集有多种校对规则,一般而言,校对规则以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束 。比如 utf8字符集,utf8_general_ci,表示不区分大小写,这个是utf8字符集默认的校对规则;utf8_general_cs表示区分大小写,utf8_bin表示二进制比较,同样也区分大小写。
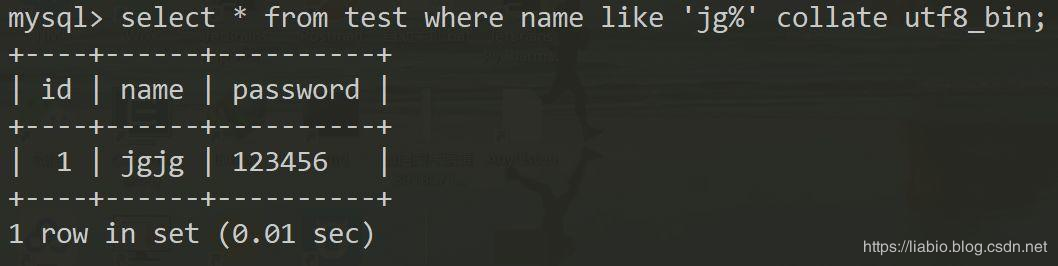
校对规则通过关键字collate指定,比如创建数据库test2,指定字符集为utf8,校对规则为utf8_bin
create database test2 default character set utf8 collate utf8_bin;
通过上述语句说明数据库test2中的数据按utf8编码,并且是对大小写敏感的。
有时候我们建库时,没有指定校对规则校对时字符大小写敏感,但是我们查询时,又需要对字符比较大小写敏感,就比如开篇中的例子,只想要jg开头的字符串。没关系,mysql提供了collate语法,通过指定utf8_bin校对规则即可。
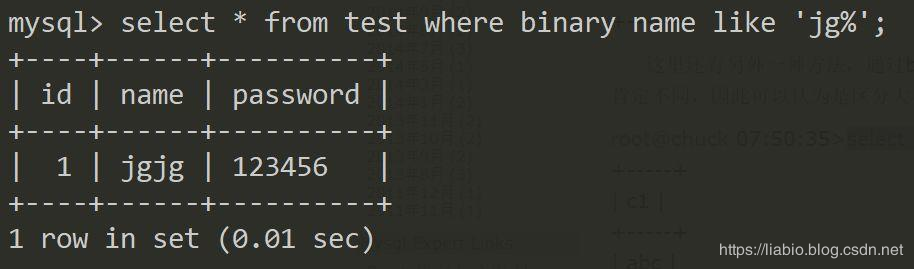
还有另外一种方法,通过binary关键字,将串转为二进制进行比较,由于大小写字符的二进制肯定不同,因此可以认为是区分大小的一种方式。
校对规则与索引存储的关系。因为校对规则会用于字符串之间比较,而索引是基于比较有序排列的,因此校对规则会影响记录的索引顺序。下面举一个小例子说明:
建表:
create table test3(name varchar(100), primary key(name));
create table test4(name varchar(100), primary key(name)) collate utf8_bin;
给表test3插入数据:
insert into test3(name) values('abc');
insert into test3(name) values('ABD');
insert into test3(name) values('ZBC');
给表test4插入数据:
insert into test4(name) values('abc');
insert into test4(name) values('ABD');
insert into test4(name) values('ZBC');
查表:
select * from test3;
select * from test4;
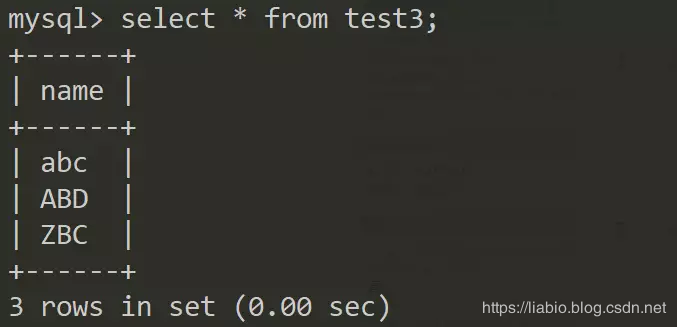
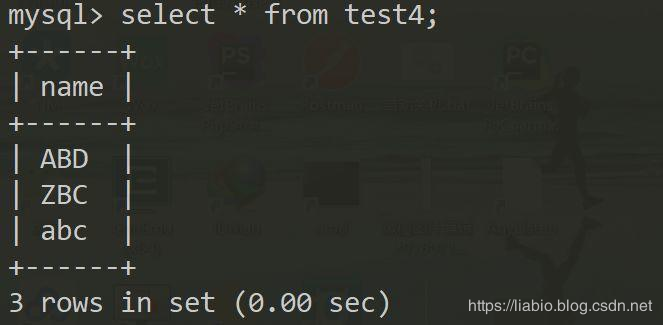
从结果可以看到test3和test4返回的结果集中,记录的相对顺序是不同的,因为是全表扫描,返回的记录体现了主键顺序。由于test3表校验规则采用默认的utf8_general_ci,大小写不敏感,因此abc<ABC<ZBC;同理,test4采用utf8_bin,大小写敏感,因此ABD<ZBC<abc。
关于mysql相关海量教程可以关注文末公众号回复【1】加助手微信索取。
本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你


 浙公网安备 33010602011771号
浙公网安备 33010602011771号