pandas数据分析-处理填充缺失数据
dropna默认丢失任何含有缺失值的行。
date = DataFrame([[1.,2.,3.],[NA,NA,NA],
[1.,3.,NA],[1.,5.,NA]])
clean = date.dropna()
print(clean)

你可能希望丢弃含有NA的行或列,传输how='all'将只丢弃含有NA的行。
date = DataFrame([[1.,2.,3.],[NA,NA,NA],
[1.,3.,NA],[1.,5.,NA]])
clean = date.dropna(how='all')
print(clean)

要用这种方式丢弃列,只需要传入axis=1即可。
date = DataFrame([[1.,2.,NA],[NA,NA,NA],
[1.,3.,NA],[1.,5.,NA]])
clean = date.dropna(axis=1,how='all')
print(clean)
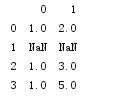
另一个滤除DataFrame行的问题涉及时间序列数据,假设你只想留下一部分观测数据,可以用thresh参数实现此目的。
df = DataFrame(np.random.randn(6,3))
df.ix[:4,1]=NA;df.ix[:2,2]=NA
print(df)

df = DataFrame(np.random.randn(5,3))
df.ix[:4,1]=NA;df.ix[:2,2]=NA
print(df.dropna(thresh=2))

你可能不想过滤除缺失数据,而是通过其他方式填补那些空洞,通过一个常数调用fillna就会将缺失值替换为常数值。
df = DataFrame(np.random.randn(5,3))
df.ix[:4,1]=NA;df.ix[:2,2]=NA
print(df.fillna(0))

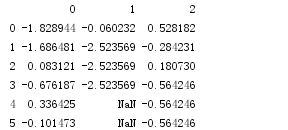
若是通过字典调用fillna,就可以实现对不同列填充不同的值。
df = DataFrame(np.random.randn(5,3))
df.ix[:4,1]=NA;df.ix[:2,2]=NA
print(df.fillna({1:0.5,2:1}))

fillna默认会返回新对象,也可以对现有对象进行就地修改。
df.ix[:4,1]=NA;df.ix[:2,2]=NA
_ = df.fillna(0, inplace=True)
print (df)
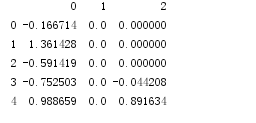
对reindex有效的那些插值方法也可用于fillna。
df = DataFrame(np.random.randn(6,3))
df.ix[2:,1]=NA;df.ix[4:,2]=NA
print(df)
print(df.fillna(method='ffill'))
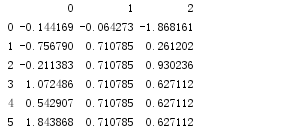
df = DataFrame(np.random.randn(6,3))
df.ix[2:,1]=NA;df.ix[4:,2]=NA
print(df)
print(df.fillna(method='ffill',limit=2))
还可以利用fillna实现很多功能,比如说:你可以传入Series的平均值或中位数。
date = Series([1,NA,2,NA,3])
print(date.fillna(date.mean()))

参数 说明
value 用于填充缺失值得标量值或字典对象
method 插值方式,如果函数调用时未指定其他参数的话,默认为“ffill”
axis 待填充的轴,默认axis=0
inplace 修改调用者对象而不产生副本
limit 对于向前和向后填充,可以连续填充的最大数量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号