

运动物体检测论文(2)
在第之前的章节中,已经提出RIMF来检测移动像素。 为了计算RIMF,应首先估算GIMF。 此外,RIMF的不确定性也可以根据自我运动和视差图不确定性来计算。
Global Image Motion Flow (GIMF)怎么计算呢?
GIMF用于表示由相机运动引起的图像运动流。 给定前一图像帧中的像素位置pt-1 =(ut-1; vt-1; 1)^T,我们可以根据Eq (1) 预测其当前帧中的图像位置pt =(ut; vt; 1)^T。。 理论上,当前帧中3D静态点的图像位置对应关系可以通过前一帧中的深度信息和相机的相对运动信息来预测。 但是,此预测仅在3D点来自静态对象时才起作用,并且不适用于动态对象。 最后,由摄像机运动引起的图像点(u; v)^T的GIMF 光流值g =(gu; gv)^T可表示为:
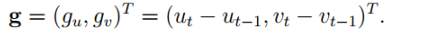
Residual Image Motion Flow RIMF 计算
假设在点(u; v)处的前一帧和当前帧之间估计的MOF是m =(mu; mv)^T,则RIMF的值q =(qu; qv)^T被计算为:

理想情况下,静态点的RIMF应为零,而移动点的RIMF应大于零。简单地将RIMF绝对差异与固定阈值进行比较不会得到令人满意的结果,能将运动像素与静态像素区分开,因为不同3D世界位置的点具有不同的图像运动。此外,估计的不确定性,例如,在相机运动或像素深度上,对图像点有不同的影响。忽视这些不确定性可能导致大量误报检测。 RIMF的不确定性主要来自四个部分。
第一个也是最重要的一个是相机运动估计的不确定性,因为它根据方程(1)对每个像素具有全局影响。此外,它会影响不同位置的像素。
第二个影响部分是深度估计的误差,
第三个影响部分来自光流估计过程。
最后一个是像素位置噪声,它直接来自图像噪声(图像校正,相机本征和外部校准,数字图像量化等)
Motion Likelihood Estimation 运动似然估计
如上所述,固定阈值不会得到检测移动像素的令人满意的解决方案。 为了处理这个问题,使用一阶高斯近似将RIMF的不确定性从传感器传播到最终估计。 如在等式(7)中,RIMF是相机运动θ,前一帧处的像素位置(u; v),视差d和测量的光流(μ; mv)的函数。在这项工作中没有考虑测量光流的不确定性,因为它只影响局部的检测结果。 基于[5]中的前向协方差传播框架,可以使用如下的一阶近似来计算RIMF协方差:
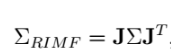
其中J表示关于每个输入变量的雅可比矩阵(例如,相机运动Θ,像素位置(u; v)和前一帧中的视差值d)和Σ= diag(ΣΘ;Σo)是协方差矩阵 所有输入变量。 相机运动的协方差矩阵是ΣΘ,估计过程中的视差值的协方差矩阵是Σo=diag (σu2;σv2; σd2),其中σu和σv是用于描述相机的像素量化误差和σd的方差。 在[18]中,作者提出视差图的不确定性也可以被认为是近似标准高斯分布,其方差可以线性近似为:
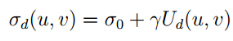
其中σ0和γ是两个常数参数,其中Ud(u; v)是位置(u; v)上的视差值的不确定性。 这里,匹配成本用作视差值的置信度度量(更多细节可以在[29]中找到)。 与Σ中每个参数的方差相比,自我运动参数,位置和视差之间的协方差可以忽略不计,并且估计过程是困难的。 基于上面估计的ΣRIMF,我们可以计算流向量移动的可能性。 假设静止世界和高斯误差传播,假设流向量遵循具有零均值和协方差矩阵ΣRIMF的高斯分布。 可以通过拟合优度检验该零假设来检测与该假设的偏差。 或者,可以计算与RIMF向量相关联的Mahalanobis距离[30]:
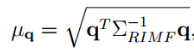
其中q是在等式7中定义的特定图像位置处的RIMF向量。 由于μ2q是χ2分布的,因此可以根据其μq值来计算RIMF向量的RIMF运动似然ξ(m)。

在图(3)中,子图(a),(b)是由曼哈顿距离μq产生的运动似然图像。 绿色像素被检测为静态像素,红色像移动一样。 在子图a中,两个骑车者来自车辆的相反方向,并且行人在与车辆相同的方向上移动,并且所有三个都被很好地检测为移动。 还检测到玻璃窗中移动的汽车的阴影。 在子图b中,已经检测到所有移动的行人,但是地面上的误报是由MOF误差引起的。
运动分割
可能性阈值可以应用于运动似然图像,以便区分移动和静态像素。 然而,由于不完美的MOF,检测噪声可能遍及该过程。 图(3)显示了使用不同阈值的一些检测结果。 例如,无论使用哪个阈值,帧16(子图3a)处的运动可能性估计都是良好的并且已经很好地检测到所有运动对象。 尽管在帧535(子图3b)处的运动似然也被很好地估计,但由于光流的粗略估计,它仍然在静态物体的边缘上有噪声。 较低的阈值导致较高的真阳性和较高假阳性; 相反,较高的阈值可能导致较差的检测率。 无法确定适合所有情况的最佳阈值。
文中使用了 Graph-Cut for Motion Segmentation (没有具体看)具体效果如下

边界框生成
应在每个移动物体周围生成边界框。 另外,还应该消除一些错误检测的像素(例如,阴影)。 在我们的方法中,我们主要关注车辆前方30米(纵向),20米(横向)和3米(高度)的立方体检测空间。 在该有限子空间中,通过将所有检测到的3D移动点投影到xOz平面上来构建密度图。 密度图与累积缓冲区相关联。 累积缓冲区中的单元在xOz平面上覆盖50cm×50cm的区域。

基于U-Disparity Map的ROI生成
在每个聚类中,可以为下一个识别步骤的每个移动对象生成边界框。 区域增长用于去除冗余并使用密集视差图集成部分检测。 U-V视差图[34,35]是经典视差图的两个变体,通常用于道路和障碍物检测。 U视差图具有与原始图像相同的宽度,其通过记录沿每个图像列共享相同视差值的像素的数量而形成。
在U视差图中,由于相似的视差值,直立对象将形成水平线。 相反,每条白色水平线代表相应的直立物体。 该信息可以有效地用于确定对象的宽度。 在获得边界框的宽度之后,基于视差值将区域增长[36]应用于聚类组像素的邻域。 视差值在每个簇的最小和最大视差值之间的像素被认为属于同一对象。 最终的界限移动物体的框显示在5b-(e)中。
基于V-Disparity Map的聚类减少




在本文中,已经提出了一种从两个连续立体帧中检测运动物体的方法。通过用于获得每个像素的运动似然的一阶误差传播模型来估计自我运动不确定性。具有高运动可能性和类似深度的像素被检测为基于图形切割运动分割方法的移动。另外,基于分割结果,可以快速识别移动物体。几个不同的真实视频序列中的检测结果表明,我们提出的算法在全局(相机运动)和局部(光流)噪声方面是稳健的。此外,我们的方法适用于所有图像像素,并且可以检测任意移动的对象(包括部分遮挡)。如果没有任何跟踪策略,我们的检测方法可以提供高召回率,并且在几个公共序列中也表现出可接受的精确率。然而,所提出的方法的计算复杂性是一个重要的问题。这主要是由于计算每个图像像素的运动似然和使用图切算法的分割。基于GPU的算法可用于克服这一弱点[42]。此外,MOD的性能高度依赖于密集光流和视差图的结果。然而,他们在复杂动态环境(包括其他移动物体)中的估计通常变得非常困难。
有兴趣的小伙伴可以关注微信公众号,加入QQ或者微信群,和大家一起交流分享吧(该群主要是与点云三维视觉相关的交流分享群,欢迎大家加入并分享)


