

运动物体检测论文(1)
接下来就是我要介绍的论文
Zhou D, Frémont V, Quost B, et al. Moving Object Detection and Segmentation in Urban Environments from a Moving Platform ☆[J]. Image & Vision Computing, 2017, 68.
这是一篇2017 的论文,发表在HAL,HAL is a multi-disciplinary open access archive for the deposit and dissemination of scientifc research documents
文章摘要:
This paper proposes an effective approach to detect and segment moving objects from two time-consecutive stereo frames, which leverages the uncertainties in camera motion estimation and in disparity computation. First, the relative camera motion and its uncertainty are computed by tracking and matching sparse features in four images(是双目相机). Then, the motion likelihood at each pixel is estimated by taking into account the ego-motion uncertainty and disparity in computation procedure. Finally, the motion likelihood, color and depth cues are combined in the graph-cut framework for moving object segmentation. The efficiency of the proposed method is evaluated on the KITTI benchmarking datasets, and our experiments show that the proposed approach is robust against both global (camera motion) and local (optical flow) noise. Moreover, the approach is dense as it applies to all pixels in an image, and even partially occluded moving objects can be detected successfully. Without dedicated tracking strategy, our approach achieves high recall and comparable precision on the KITTI benchmarking sequences.
文章提出了一种基于双目视觉中时间连续两帧中检测和分割出运动物体的有效方法,该方法利用了相机运动估计和视差计算中的不确定性。
首先,通过跟踪和匹配四个图像中的稀疏特征来计算相对相机运动及其不确定性。然后,将每个像素处的运动似然考虑到自车运动的不确定性和视察估计中。最后,将运动似然,颜色和深度信息,组合在用于运动对象分割的图形切割框架中。在KITTI基准数据集上评估了所提方法的效率,并且我们的实验表明,所提出的方法对全局(相机运动)和局部(光流)噪声具有鲁棒性。此外,该方法是密集的,因为它适用于图像中的所有像素,并且甚至可以成功地检测到部分遮挡的移动对象。如果没有专门的跟踪策略,我们的方法可以在KITTI基准测试序列上实现高召回率和可比较的精确度。
介绍
Making the vehicles to automatically perceive and understand their 3D environment is a challenging and important task,Due to the improvement of the sensor tech- nologies, processing techniques and researchers’ contributions, several Advanced Driver Assistance Systems (ADASs) have been developed for various purposes such as forward collision warning systems, parking assist systems, blind spot detection systems and adaptive cruise control systems
文中说到科研人员一直以来都在挑战的一个任务,就是使车辆能够感知和理解这个3D环境,,当然随着传感器技术的不断进步以及研究者们的贡献,ADAS有了很大的进展,并举例有碰撞报警,泊车辅助,盲区检测,以及自适应巡航系统。
当前更为流行的比如SLAM和SFM系统都很好的应用在ADAS系统以及自动驾驶中,比如比较常用且流行的ORB-SLAM
R. Mur-Artal, J. Montiel, and J. D. Tardos, \Orb-slam: a versatile and accu-rate monocular slam system," Robotics, IEEE Transactions on, vol. 31, no. 5,600 pp. 1147{1163, 2015.
但是呢,这些系统都假设是静态的环境,他们必须要面对一些复杂的城市环境和动态的物体,因此,有效且有效地检测移动物体对于这种系统的准确性来说是一个至关重要的问题。
moving objects are considered as outliers and RANSAC strategy is applied to get rid of them efficiently. However, this strategy will fail when the moving objects are the dominant part of the image. Thus, efficiently and effectively detecting moving objects turns out to be a crucial issue for the accuracy of such systems.
In this article, we focus on the specific problem of moving object detection. We propose a detection and segmentation system based on two time-consecutive stereo images. The key idea is to detect the moving pixels by compensating the image changes caused by the global camera motion. The uncertainty of the camera motion is also considered to obtain reliable detection results. Furthermore, color and depth information is also employed to remove some false detection
此文章 重点解决移动对象检测的具体问题。 提出了一种基于时间连续立体图像的两帧图像移动物体的检测和分割系统。 关键思想是通过补偿由全局相机运动引起的图像变化来检测运动像素。 摄像机运动的不确定性也被认为是获得可靠的检测结果。 此外,还使用颜色和深度信息来消除一些错误检测!!!(什么是通过补偿相机的全局运动引起的图像变换来检测相机运动)
移动物体检测一直以来都是研究的热点,其中背景减除法是最常用的一种物体检测方法。说了一些单目视觉上的移动物体检测方法,主要还是上面介绍的那些方法。
但是本文使用的双目,相比于单目摄像头,双目(stereo vision system SVS)提供了深度信息和视差信息。
Dense or sparse depth/disparity maps computed by global [10] or semi-global [11] matching approaches can be used to build 3D information on the environment. Theoretically, by obtaining the 3D information, any kind of motion can be detected, even the case of degenerate motion mentioned above. In [12], 3D point clouds are reconstructed from linear stereo vision systems first and then objects are detected based on a spectral clustering technique from the 3D points. Common used methods for Moving Object Detection (MOD) in stereo rig can be divided into sparse feature based [13, 14] and dense scene flow-based approaches [15, 16, 17]
通过全局[10]或半全局[11]匹配方法计算的密集或稀疏深度/视差图可用于重构环境的3D信息。 理论上,通过获得3D信息,即使是在自车运动退化的情况,也可以检测任何类型的运动。 在[12]中,首先从线性立体视觉系统重建3D点云,然后基于来自3D点的光谱聚类技术检测物体。 在立体相机中用于运动物体检测(MOD)的常用方法可以分为基于稀疏特征的[13,14]和基于密集场景流的方法[15,16,17]。
[10]L. Wang and R. Yang, \Global stereo matching leveraged by sparse ground control points," in Computer Vision and Pattern Recognition (CVPR), Conference on, pp. 3033{3040, IEEE, 2011.
[11] H. Hirschmuller, \Accurate and efficient stereo processing by semi-global matching and mutual information," in Computer Vision and Pattern Recognition, IEEE Computer Society Conference on, vol. 2, pp. 807{814, 2005.
[12] S. Moqqaddem, Y. Ruichek, R. Touahni, and A. Sbihi, \Objects detection and tracking using points cloud reconstructed from linear stereo vision," Current Advancements in Stereo Vision, p. 161, 2012.
[13] B. Kitt, B. Ranft, and H. Lategahn, \Detection and tracking of independently moving objects in urban environments," in Intelligent Transportation Systems, 13th International IEEE Conference on, pp. 1396{1401, IEEE, 2010.
[14] P. Lenz, J. Ziegler, A. Geiger, and M. Roser, \Sparse scene flow segmentation for moving object detection in urban environments," in Intelligent Vehicles Symposium (IV),IEEE, pp. 926{932, 2011.
[15] A. Talukder and L. Matthies, \Real-time detection of moving objects from moving vehicles using dense stereo and optical flow," in Intelligent Robots and Systems, Proceedings. International Conference on, vol. 4, pp. 3718{3725, IEEE, 2004.
[16] V. Romero-Cano and J. I. Nieto, \Stereo-based motion detection and tracking from a moving platform," in Intelligent Vehicles Symposium, IEEE, pp. 499 IEEE, 2013.
[17] C. Rabe, T. M¨uller, A. Wedel, and U. Franke, \Dense, robust, and accurate motion field estimation from stereo image sequences in real-time," in European conference on computer vision, pp. 582{595, Springer, 2010
当在移动物体对象上检测到很少的特征时,基于稀疏特征的方法就会失败。 此时,可以使用基于密集光流的方法。 在[15]中,基于当前场景深度和自我运动,预测和计算两个连续帧之间的光流。从预测的光流场和测量得到的光流场之间的差异,较大的非零区域被分类为潜在的移动物体。 尽管该运动检测方案提供了密集的结果,但是由于感知任务中涉及的噪声,系统可能易于产生大量的误检测。 通过考虑3D场景流[18]或2D真实光流[16]的不确定性,已经开发了其他改进方法[18]和[16]来限制误检测。 然而,这些方法粗略地模拟了从其他传感器比如 (GPS or IMU)获得的自我运动的不确定性。
使用来自单目相机的对极几何结构不能在其运动退化时检测移动物体。(退化的解释:3D点沿着由两个相机中心和点本身形成的极线平面移动,而其2D投影沿着极线移动。)
假设已经标定好的双目相机,We denote b as the calibrated baseline for the stereo head.
Additionally, the left and right rectified images have identical focal length f and principal point coordinates as p0 = (u0; v0)T.
下图给出了两帧连续的从t-1到t时刻的双目相机图像。假设世界坐标系的原点在时间t-1与左摄像机的局部坐标系重合。
the X-axis points to the right and the Y -axis points downwards (X轴方向向右,Y轴向下)
在t-1时刻,从静态背景点提取的像素的位置是 
在t时刻获取的位置是![]()

其中K是相机的内在参数矩阵,R,tr是相对相机旋转和平移(姿势),Zt-1代表t-1中帧中3D点X的深度。
为了检测图像中的运动物体,一个直截了当的想法是通过方程式补偿相机运动。根据公式
 (1)
(1)然后,残差图像被计算为在运动中补偿的当前和先前的差值,突出显示属于运动对象的像素和与运动误差估计有关的像素。 为了清楚起见,我们首先定义三种不同的基于流的表达式:
全局图像运动光流( Global Image Motion Flow GIMF)表示仅由相机运动引起的预测图像变化,可以使用等式(1)计算
测量光流( Measured Optical Flow MOF)表示使用图像处理技术估计的实际密集光流[23]。
C. Liu, Beyond pixels: exploring new representations and applications for motion analysis. PhD thesis, Massachusetts Institute of Technology, 2009.
残余图像运动光流( Residual Image Motion Flow RIMF)用于测量MOF和GIMF之间的差异
RIMF可用于区分该像素是否和移动和非移动物体相关的像素。 为了计算RIMF,应首先计算MOF和GIMF。 注意计算后者需要关于相机运动(自我运动)和像素深度值的信息。文中没有说明计算密集光流[23]和视差图[24]的问题:
[23] C. Liu, Beyond pixels: exploring new representations and applications for motion analysis. PhD thesis, Massachusetts Institute of Technology, 2009.
[24] A. Geiger, M. Roser, and R. Urtasun, \Efficient large-scale stereo matching,"in Asian Conference on Computer Vision, pp. 25{38, Springer, 2010
[25]C. Vogel, K. Schindler, and S. Roth, \3d scene flow estimation with a piecewise rigid scene model," International Journal of Computer Vision, vol. 115, no. 1, pp. 1{28, 2015.
更确切地说,我们利用[25]中提出的方法来计算密集光流和密集视差图。 然后我们直接将它们用作我们系统的输入。 整个系统可以通过以下三个步骤进行总结:
1. Moving Pixel Detection 移动像素检测。 在该步骤中,通过补偿由相机运动引起的图像变化来检测运动像素。 为了改善检测结果,考虑了相机运动的不确定性。
2. Moving object segmentation移动对象分割。 在移动像素检测之后,使用基于图形切割的算法通过考虑颜色和视差信息来移除错误检测。
3. Bounding box generation.边界框生成。 最后,通过使用UV视差图分析为每个移动物体生成边界框
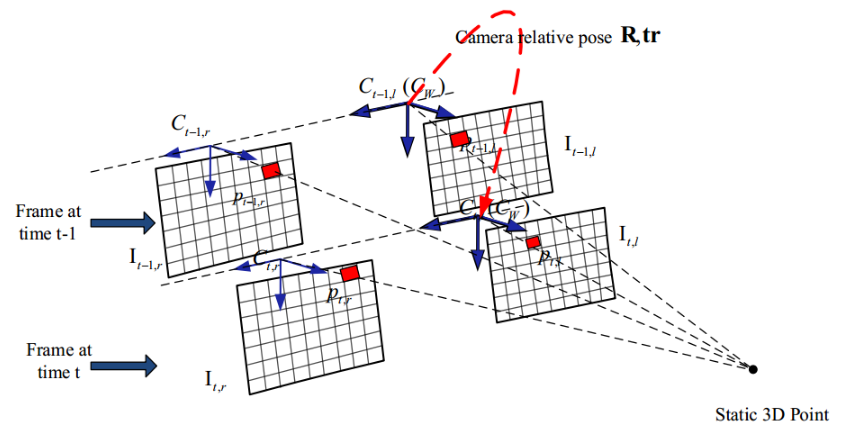
图1 双目视觉下的坐标系
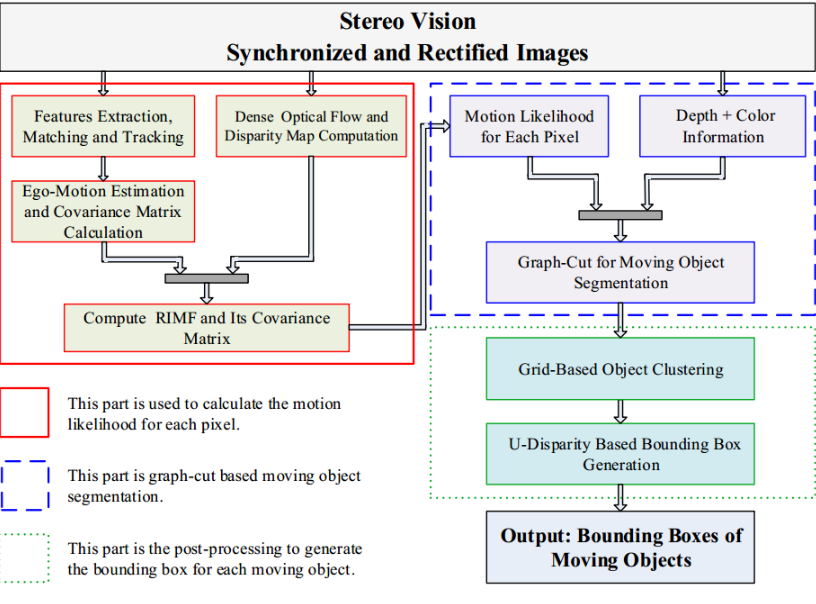
图2 Framework of the moving object detection and segmentation system
红色部分用于计算每个像素的运动似然。
蓝色部分是基于图形切割的运动对象分割。
绿色部分是为每个移动对象生成边界框的后处理。
首先介绍Moving Pixel Detection 移动像素检测
从图1双目连续两帧的四个图像来看,在t-1时刻和t时刻的图像,在t-1时刻左图像I_(t-1,L)被当做是参考图像,以下是定义

接着是自车运动估计和不确定性计算
给定两个连续帧的四个图像中的一组对应点,可以通过使用非线性最小化方法最小化重投影误差的总和来估计相机的相对姿态。
首先,重建前一帧的3D特征点。通过三角测量和使用相机内在参数。 然后使用如下的相机运动将这些3D点重新投影到当前帧的图像上、
 (2)
(2)其中![]()
 是通过前一帧图像重构后的3D点计算出的当前帧图像上的像素点。
是通过前一帧图像重构后的3D点计算出的当前帧图像上的像素点。 是前一帧图像上的像素点。
是前一帧图像上的像素点。
是通过前一帧图像重构后的3D点计算出的当前帧图像上的像素点。是前一帧图像上的像素点。 该向量是 代表了六个自由度的相对位姿(是两个帧上同一点的相对位姿)
该向量是 代表了六个自由度的相对位姿(是两个帧上同一点的相对位姿) P rl 和 P rr 是3D点投影到左右相机上的像素的坐标(non-homogeneous coordinates)
通常,可以通过最小化测量和预测的加权平方误差来获得最佳相机运动矢量Θ^ ,公式如下:
 (3)
(3) 是使用跟踪和匹配策略的当前帧中的匹配点
是使用跟踪和匹配策略的当前帧中的匹配点 代表根据协方差矩阵Σ的曼哈顿距离
代表根据协方差矩阵Σ的曼哈顿距离所以我们根据以上这些可知,最优估计的运动向量 Θ^可以根据(3)公式求得,但结果是依赖于图像之间的匹配和跟踪的精度的。

 (4)
(4)

由于篇幅限制,所以接下来的内容就请查看《运动i物体检测论文(2)》,那么可以根据这个框架图可以总结一下文章的思想,在双目视觉中,由于我们可以根据双目相机求得特征点对应的深度信息,所以我们使用上述的公以求得上一帧图像中的特征点,在当前帧图像上的位置,,那么根据该点的位移值即是我们上文中说到的全局图像运动光流( Global Image Motion Flow GIMF)之后再利用KLT光流法求得我们的测量光流(测量光流( Measured Optical Flow MOF)),那么这两个光流值对于静态物体而言,这两个值是相等,而对于动态移动物体是有误差的这也就是我们上文中说到的 残余图像运动光流( Residual Image Motion Flow RIMF),主要思想就是通过这个误差来判断该特征点是属于静态特征点还是动态特征点,当然文中还是使用一些其他方法来提高检测的精度,但是主要的思想就是如此。接下来的文章是文中关于其他一些技术上的说明。
有兴趣的小伙伴可以关注微信公众号,加入QQ或者微信群,和大家一起交流分享吧(该群主要是与点云三维视觉相关的交流分享群,欢迎大家加入并分享)


