

利用深度学习的点云语义分割(一)
Semantic Segmentation of Point Clouds using Deep Learning
在计算机视觉中,用3D表示数据变得越来越重要。 近年来,点云已成为3D数据的代表。 点云是一组3D点,它可以有不同的传感器获得,如激光雷达扫描仪。 点云也可以具有每个点的RGB值,这就是一个彩色的点云。 如今点云通常用于3D对象的可视化,机器人技术领域的3D地图。 区分一个物体的点云,常用的方法是语义分割法。
在计算机视觉中,语义分割的任务是是分割图像或者点云,区分出不同的分割物。 当使用语义分割时,它将图像或点云划分为语义上有意义的部分,然后在语义上将每个部分标记为预定义的类之一。 识别出不同点云或图像数据内的物体,这在许多应用程序中非常有用。在二维语义分割中,论文【4】【20】【21】已经表明卷积神经网络可以给出了良好的实验结果。在3D情况下,论文【8】【19】使用随机森林分类器来进行点云的语义分割是非常受欢迎的研究方法。图一显示了一个点云和具有相同语义的分割。 在本论文中,研究卷积神经网络在点云语义分割中的应用。


图一,左图显示了一个带有颜色的点云,用激光雷达扫描仪拍摄。 右图显示了点云的语义分割。 红色:地面,绿色:天然草地,蓝色:高植被,紫色:建筑物,青色:硬景观 和黑色:无标签或者无效。
如今,图像或点云的语义分割的不同应用领域中使用。在机器人领域,语义分割例如用于标记机器人环境中的物体。如果机器人需要找到特定的对象,则需要进行某种对象识别。所以语义标注非常有用,因为机器人可以对其周围的对象进行分类和识别。自主驾驶也是使用语义标签分割的领域。对于一辆自行驾驶的车辆来说,它需要知道周围有什么不同的物体。车辆要知道的最重要的事情之一是道路是怎么样的是否是可以的可以行走的。另一个重要的事情要知道的是其他车辆的位置,知道其他车辆的位置这样它可以适应它们的速度,或者在必要时超过它们。同样在3D地图中,语义标签被用来可视化对象,例如建筑物,地形和道路。语义标签可以给我们一个更容易理解的3D地图。点云的语义分割另一个很有用的是3D点云的陪住。在配准中,计算两组点之间的刚性变换以对齐两个点集,比如论文【2】
在点云数据上执行语义分割时,会比在2D图像的语义分割中遇到更多困难。 一个大难题是3D的案例中没有太多的训练数据。 这是因为在3D中标注数据集比在2D中更难。 另一个挑战是点云之间的点稀疏,这使得有可能透视物体。 这使得难以看到点云中的结构并区分一个点属于哪个物体。
文章的目的是利用预训练的二维卷积神经网络来研究点云的语义分割。 这是通过投影点云中的合成2D图像并使用卷积神经网络对它们进行分割来执行的。
为了实现语义分割点云,我们选择将点云投影到2D图像中。 这是因为在2D中语义分割的问题比3D中的更容易,这意味着分类器有更多的选择来分割图像。 进行2D投影的另一个原因是2D中的训练数据比3D中丰富。 这使得测试不同数据变得更加容易,并且还有更多种类的训练数据。 学则使用卷积神经网络(CNN)作为工具,因为它已被证明是用于图像的语义分割的好工具。
本文提出了一种点云语义分割方法。 该方法的第一步是将点云投影到虚拟2D RGB图像中。 然后,使用预训练卷积神经网络对图像进行语义分类。 分类的结果会给我们在语义图像中的每个像素中的每个类的一个分数。 然后将得分投影到点云数据中,这已不是给点云语义标记。 最后,使用来自数据集Semantic3D的地面实况来评估标记的点云。【3】
所以文章主要是三部分,第一部分是介绍CNN在分类领域的流行,第二部分是利用CNN对2D图像的分类,第三部分是3D点云的语义分割。
关于CNN的部分就不再介绍,那么2D中的语义分割【17】是在图像中查找不同对象并将每个对象分类为预定义类的问题。 在图像的语义分割中,图像被分割并分类为预定义类。 一种常用的二维图像语义分割方法是利用卷积神经网络对像素进行标签的图像[4] [20] [21]。 在图2中可以看到语义分割图像的一个例子

图2 右图为语义分割的结果
接下来是3D点云的语义分割部分,在三维语义分割的情况下,就是语义分割点云而不再是2D的图像。有不同的方法可以解决三维点云分割的问题,并且使用随机森林分类器很受欢迎[19] [8]。随机森林[1]由多个预测树组成。每棵树都会输出一个预测的类,并且所有的树都会投票给最受欢迎的类。在文章[19]中,作者通过使用条件随机场(CRF)语义分割室内场景的点云。通过使用随机森林分类器的结果来初始化CRF的一元势,然后从训练数据中学习成对势。另一种方法[8]使用随机森林分类器来对城市的三维模型进行语义分割。随机森林分类器在轻量级3D特征上进行训练,并用于场景的初始标记。然后通过检测其语义结构的差异将场景分成单独的外观。最后,作者提出了建筑规则来表达像门面的对齐和共同出现等偏好,这有助于改善结果。另一种方法用于文献[5]中,逐步对点云进行降采样以生成多尺度邻域。然后为每个比例级别计算一个搜索结构,从而快速且容易地从邻域中提取特征。为了语义分割点云提取特征向量,然后使用随机森林分类器进行分类。
接下来就是描述三维语义分割的方法
本节简要介绍了提出方法。该处理 方案由三部分组成。 第一部分是点云投影到二维RGB图像,深度图像和标签图像。 第二部分是使用CNN进行投影RGB图像的语义分割。 第三部分是将分割后的图像投影回点云。 在图3.1中可以看到处理流程的概述。
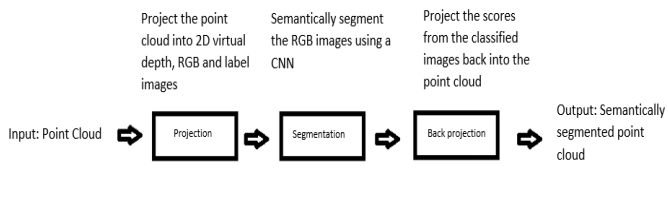
该图显示了本文提出的点云语义分割的总体流程。 第一部分将点云投影到虚拟2D图像中。 第二部分执行图像的语义分割。 最后一部分将语义分割的图像反投影到点云中,从而创建语义分割的点云。
(1)点云投影到2D中,首先介绍将点云投影到虚拟2D图像中。投影的步骤为每个点云投影生成RGB图像,深度图像和标签图像。
定义相机参数
流程中的第一步是将点云投影到虚拟2D图像中。 在该方法的情况下,这一步是必要的,因为我们使用无组织的点云作为输入,并且初始相机未知。 正因为如此,我们将点云投影到2D图像上。 为了生成2D图像,我们需要选择定义相机选择点云的视点。 其他方法也是可行的,例如网格划分,但是对于大点云来说太耗时了。 使用的相机模型由内参和外参矩阵表示。 外参矩阵是从世界坐标到相机坐标的变换。 内参矩阵反而定义了相机的几何属性。 摄像机的定义如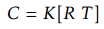 ,其中R是表示相机的外参旋转的部分,是一个3×3的矩阵,T是一个3×1的矩阵表示相机的平移参数,K是相机的内参,它符合该式子的形式:
,其中R是表示相机的外参旋转的部分,是一个3×3的矩阵,T是一个3×1的矩阵表示相机的平移参数,K是相机的内参,它符合该式子的形式:![]() ,至于相机的内参就不再一一说明,似乎之前的文章就有说过关于相机的模型的介绍,虽然我的这篇博客写的不好,但是网上是有很多类似的关于相机的模型的推导。
,至于相机的内参就不再一一说明,似乎之前的文章就有说过关于相机的模型的介绍,虽然我的这篇博客写的不好,但是网上是有很多类似的关于相机的模型的推导。
那么我们定义的相机可以放置在点云内的任何地方。 例子中,相机被放置在点云的原点。 这是因为使用的点云是通过单个激光雷达扫描获得的。 然后摄像机只能投射在点云扫描过程中可见的区域上。 相机旋转了一圈,因此它捕获了大部分的带你晕。 对于每次旋转,都进行了投影操作。
第二步 Katz投影
在投影过程中,确定哪些点从相机可见是非常重要的。 为了解决这个问题,我们使用了一个叫做Katz投影的算法[7]。 使用Katz投影的原因是它是确定点云中哪些点可见的快速方法。 该算法使用一个隐藏点运算操作,删除所有相机不可见的点。 例如,如果照相机在点云内投射一棵树,它后面的所有点都被Katz投影移除。 该算法还消除彼此靠近的点云以加速算法。 katz投影分两步进行,(inversion and convex hull construction )反演和凸包结构。 用于反演的方法称为球形翻转。 它通过在点云中的所有点周围定义一个半径为R的球体并将相机C放置在原点中来执行。 点的球形翻转使用以下公式计算:![]() ,
,
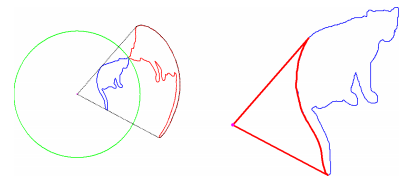
左:使用以视点(品红色)为中心的球体(绿色)2D曲线(蓝色)的球形翻转(红色)。 右:凸包的反投影。 请注意,此图片仅用于说明; 在实际中,R要大得多。
在球形翻转后,距离相机最近的点将离照相机最远。
Katz算法的下一步是构造凸包来确定哪些点是可见的。 这是因为点p在变换点p_^驻留在凸包中时被认为是可见的。当确定哪些点可见时,将3D点投影到像素中。 这是通过以下公式完成的: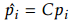 ,
,
其中C是相机矩阵,pi是可见点,p_^_i是投影点。 由于点不总是投影到像素上,因此使用最近邻点将点投影到像素中。 在此之后,每个可见点都有相机的深度和计算出的重量。 这个重量决定了这些点在其相应的像素中有多大的贡献。 这些点的权重是使用splatting [16]来计算的,这是一种将点映射到周围像素的方法。 使用高斯函数来计算权重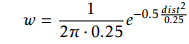
其中dist是像素与点位置之间的距离。
第三步 Mean Shift Clustering (均值漂移聚类)
接下来的问题是计算像素的深度和RGB值。 因为它可能不止一个像素点,我们必须计算每个点对像素深度和RGB值的贡献量。 这是通过使用均值漂移聚类算法来解决的,该算法根据点的密度计算深度和RGB的加权平均值。具体不再解释
算法伪码


显示RGB,深度图像和两个标签图像bildstein3点云的不同姿势。
下一步是语义分割点云的投影RGB图像。 图像的语义分割由预先训练的CNN执行。 在本论文中,两个不同的CNN被用于该任务。 这是因为我们想比较不同的CNN如何影响我们方法的结果。 使用的CNN之一是Laplacian金字塔重建网络[4],该网络执行像素明智的标记,并在Cityscapes数据集上进行训练[12]。 Cityscapes数据集包含从50个不同城市收集的街道场景序列,具有高质量的像素级注释。 该数据集包含19个语义类,属于地面,建筑,物体,自然,天空,人体和车辆7种不同类别。
[1] Leo Breiman. Random forests. Mach. Learn., 45(1), 2001. Cited on page 7.
[2] Martin Danelljan, Giulia Meneghetti, Fahad Shahbaz Khan, and Michael Felsberg. Aligning the Dissimilar : A Probabilistic Method for FeatureBased Point Set Registration. ICPR16, 2016. Cited on page 3.
[3] ETH Zurich. Large-Scale Point Cloud Classification Benchmark. URL http://www.semantic3d.net/. Cited on pages 4, 23, and 40.
[4] Golnaz Ghiasi and Charless C. Fowlkes. Laplacian reconstruction and refinement for semantic segmentation. ECCV, 2016. Cited on pages 1, 6, and 16.
[5] Timo Hackel, Jan D Wegner, and Konrad Schindler. Fast Semantic Segmentation of 3D Point Clouds with Strongly Varying Density. ISPRS16, 2016. Cited on pages 7, 40, and 41.
[6] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093, 2014. Cited on
page 21.
[7] Sagi Katz. Direct Visibility of Point Sets. ACM Trans. Graph., 26(3), 2007. Cited on page 11.
[8] Jan Knopp, Hayko Riemenschneider, and Luc Van Gool. 3D All The Way Semantic Segmentation of Urban Scenes From Start to End in 3D. CVPR, 2015. Cited on pages 1 and 7.
[9] Yann LeCun and Yoshua Bengio. The handbook of brain theory and neural networks. chapter Convolutional Networks for Images, Speech, and Time Series, pages 255–258. MIT Press, Cambridge, MA, USA, 1998. Cited on page 5.
[10] Linköping University. Virtual Photo Sets. URL http://www.hdrv.org/vps/. Cited on page 27.
[11] Tianyi Liu, Shuangsang Fang, Yuehui Zhao, Peng Wang, and Jun Zhang. Implementation of Training Convolutional. arXiv:1506.01195, 2015. Cited on pages 5 and 6.
[12] Marius Cordts. Cityscapes Dataset. URL https://www.cityscapes-dataset.com/dataset-overview/. Cited on page 16.
[13] C V May. Fractional Max-Pooling. arXiv:1412.6071, 2015. Cited on page 5.
[14] Peter Meer. Mean Shift : A Robust Approach toward Feature Space Analysis. IEEE, 24(5), 2002. Cited on page 12.
[15] Radu Bogdan Rusu and Steve Cousins. 3D is here: Point Cloud Library(PCL). ICRA, 2011. Cited on page 21.
[16] Richard Szeliski. Computer Vision : Algorithms and Applications. 2010. URL http://szeliski.org/Book. Cited on page 12.
[17] Martin Thoma. A Survey of Semantic Segmentation. arXiv:1602.06541,2016. Cited on page 6.
[18] Andrea Vedaldi and C V May. MatConvNet Convolutional Neural Networks for MATLAB. arXiv:1412.4564. Cited on page 21.
[19] Daniel Wolf, Johann Prankl, and Markus Vincze. Fast Semantic Segmentation of 3D Point Clouds using a Dense CRF with Learned Parameters. ICRA, 2015. Cited on pages 1 and 7.
[20] Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, and Philip Torr. Conditional Random Fields as Recurrent Neural Networks. ICCV, 2015. Cited on pages
1 and 6.
[21] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic Understanding of Scenes through the ADE20K Dataset. arXiv:1608.05442, 2016. Cited on pages 1, 6, and 16.
关注微信公众号,加入群聊


