
5 Hbase
# 大纲:
* 认识 HBase
* HBase 架构
* HBase读写流程
定义:
* HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用Hbase 技术可在廉价PC Server 上搭建起大规模集群。它是一个可以随机访问的存储和检索数据的平台。他不加以数据的类型。允许动态的,灵活的数据模型
Hbase基本概念
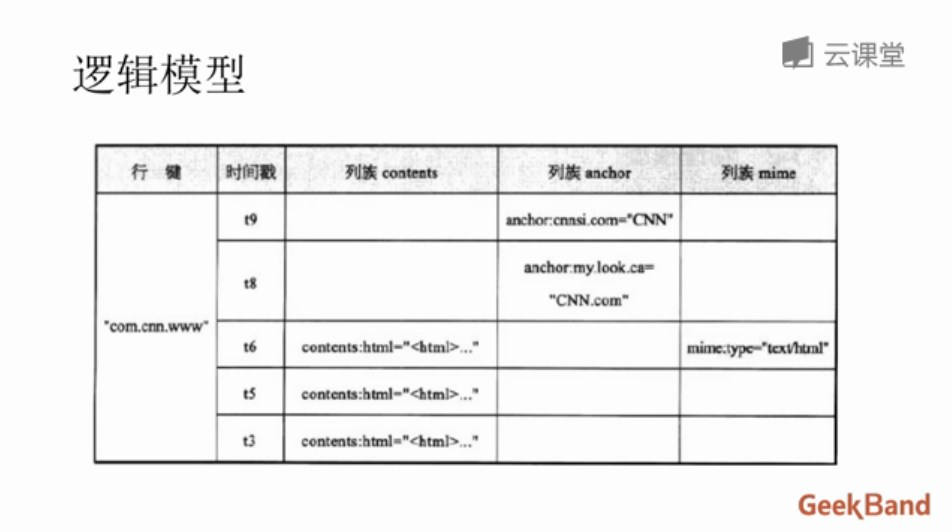
RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
Value(Cell):Byte array
Client
包含访问HBase的接口,并维护cache来加快对HBase的访问,比如region的位置信息
Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改查操作
Region Server
Regionserver维护region,处理对这些region的IO请求
Regionserver负责切分在运行过程中变得过大的region
Zookeeper作用
通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
存贮所有Region的寻址入口
实时监控Region server的上线和下线信息。并实时通知给Master
存储HBase的schema和table元数据
默认情况下,HBase 管理ZooKeeper 实例,比如, 启动或者停止ZooKeeper
Zookeeper的引入使得Master不再是单点故障
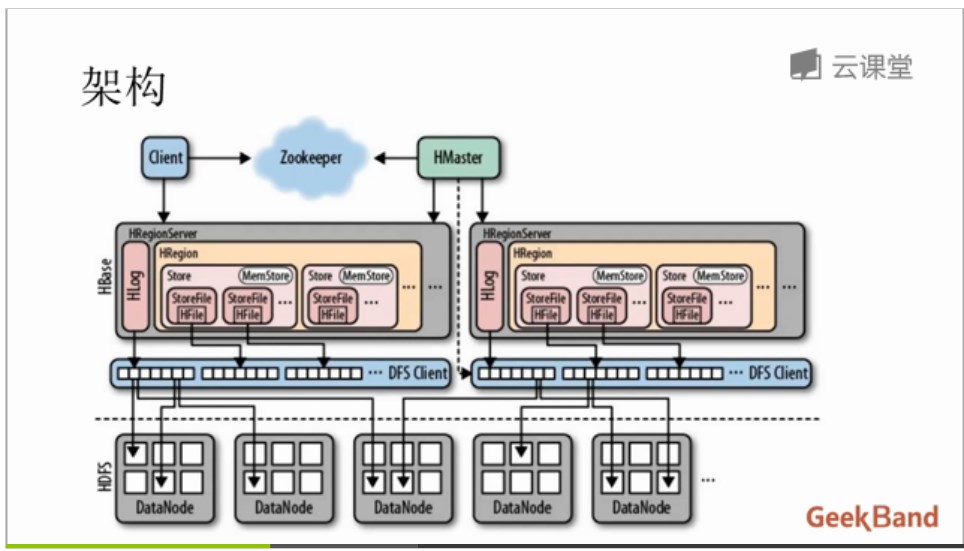
物理存储:
1、Table中所有行都按照row key的字典序排列;2、Table在行的方向上分割为多个Region;
3、Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
4、Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
5、Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。
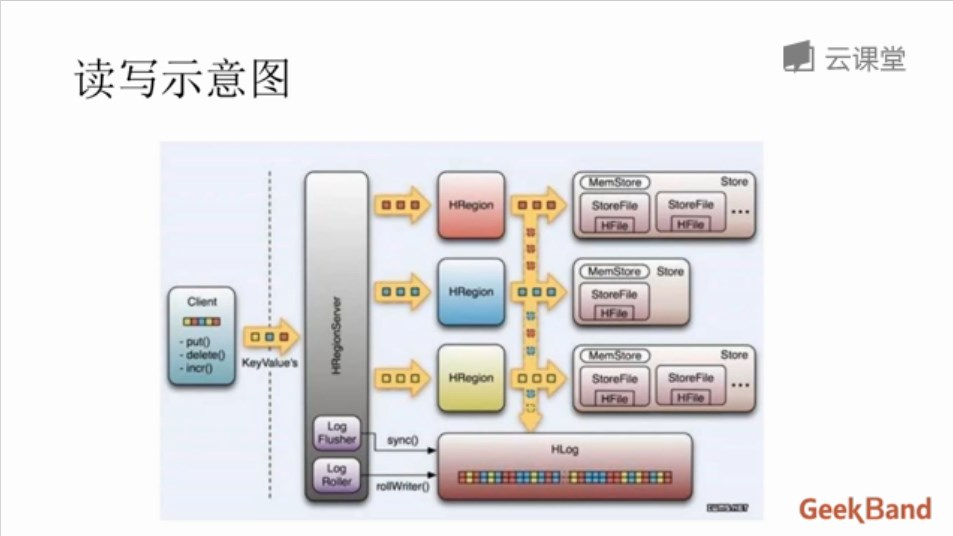
# Hbase 的读写流程
```
专注数据分析
欢迎转载并注明出处
```
