微服务架构-雪崩效应
微服务化产品线,每一个服务专心于自己的业务逻辑,并对外提供相应的接口,看上去似乎很明了,其实还有很多的东西需要考虑,比如:服务的自动扩充,熔断和限流等,随着业务的扩展,服务的数量也会随之增多,逻辑会更加复杂,一个服务的某个逻辑需要依赖多个其他服务才能完成。一但一个依赖不能提供服务很可能会产生雪崩效应,最后导致整个服务不可访问。
微服务之间进行rpc或者http调用时,我们一般都会设置调用超时,失败重试等机制来确保服务的成功执行,看上去很美,如果不考虑服务的熔断和限流,就是雪崩的源头。
假设我们有两个访问量比较大的服务A和B,这两个服务分别依赖C和D,C和D服务都依赖E服务
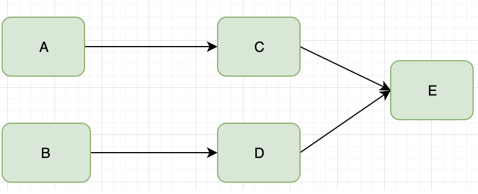
A和B不断的调用C,D处理客户请求和返回需要的数据。当E服务不能供服务的时候,C和D的超时和重试机制会被执行

由于新的调用不断的产生,会导致C和D对E服务的调用大量的积压,产生大量的调用等待和重试调用,慢慢会耗尽C和D的资源比如内存或CPU,然后也down掉。
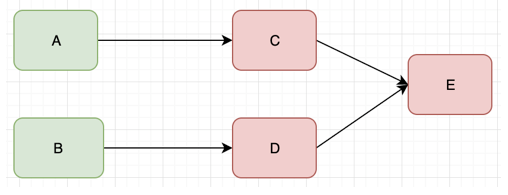
A和B服务会重复C和D的操作,资源耗尽,然后down掉,最终整个服务都不可访问。
常见的导致雪崩的情况有以下几种:
- 程序bug导致服务不可用,或者运行缓慢
- 缓存击穿,导致调用全部访问某服务,导致down掉
- 访问量的突然激增。
- 硬件问题,这感觉只能说是点背了⊙︿⊙。
虽然雪崩效应的产生千万条,保证服务的不挂机,和流畅运行是我们不可推卸的责任,对应雪崩效应还是有很多保护方案的。
服务的横向扩充
现在我们可以利用很多工具来保证服务不会挂掉,然后流量比较大的时候,可以横向扩充服务来保证业务的流畅。比如我们最常使用k8s,能保证服务的运行状态,也可以让服务自动的横向扩充。对于用户访问量的激增情况这样处理还是很不错的,但是,横向扩充也是有尽头的,如果在一定环境下E服务的响应时间过长,依然有可能导致雪崩效应的产生。

限流
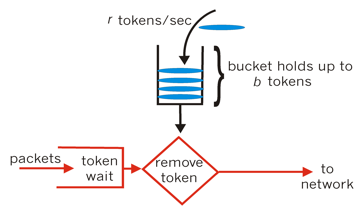
限制客户端的调用来达到限流的做法是很常见的,比如,我们限制每秒最大处理200个请求,超过个数量直接拒绝请求。常见的算法如令牌桶算法
以一定的速度在桶里放令牌,当客户端请求服务的时候,要先从桶里得到令牌,才能被处理,如果桶里的令牌用完了,则拒绝访问。
熔断
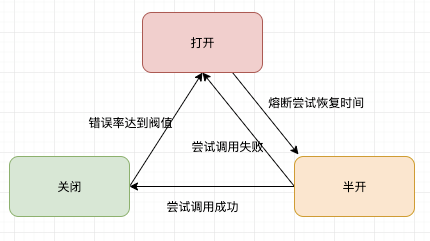
在客户端控制对依赖的访问,如果调用的依赖不可用时,则不再调用,直接返回错误,或者降级处理。开源的库比如hystrix-go,也是我接下来要写的源码分析的一个库。很好的实现了熔断和降级的功能。他的主要思想是,设置一些阀值,比如,最大并发数,错误率百分比,熔断尝试恢复时间等。能过这些阀值来转换熔断器的状态:
- 关闭状态,允许调用依赖
- 打开状态,不允许调用依赖,直接返回错误,或者调用fallback
- 半开状态,根据
熔断尝试恢复时间来开启,允许调用依赖,如果调用成功则关闭失败则继续打开
具体的实现方式和对hystrix-go源码的分析,在这篇帖子里hystrix-go 源码分析。

