
爬虫(2)
一、XPATH解析和案例
XPATH是解析方式中最重要的一种。
1、环境安装
pip install lxml
2、解析原理
- 获取页面源码数据
- 实例化一个etree的对象,并且将页面源码数据加载到该对象中
- 调用该对象的xpath方法进行指定标签的定位
- 注意:xpath函数必须结合着xpath表达式进行标签定位和内容捕获
3、xpath表达式

4、五个案例
1)解析58二手房的相关数据
# 58二手房信息 import requests from lxml import etree url = 'https://bj.58.com/ershoufang/sub/l16/s2242/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.bdpcpz_bt&PGTID=0d30000c-0000-1139-b00c-643d0d315a04&ClickID=1' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } page_text = requests.get(url,headers=headers).text tree = etree.HTML(page_text) li_list = tree.xpath('//ul[@class="house-list-wrap"]/li') for li in li_list: title = li.xpath('./div[2]/h2[1]/a/text()')[0]
2)下载彼岸图网中的图片数据:中文乱码问题
import os import urllib url = 'http://pic.netbian.com/4kmeinv/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } response = requests.get(url,headers=headers) # print(response.encoding) # ISO-8859-1 # response.encoding = 'utg-8' if not os.path.exists('./imgs'): os.mkdir('./imgs') page_text = response.text tree = etree.HTML(page_text) li_list = tree.xpath('//div[@class="slist"]/ul/li') for li in li_list: img_name = li.xpath('./a/b/text()')[0] # 处理中文乱码 img_name = img_name.encode('ISO-8859-1').decode('gbk') img_url = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0] img_path = './imgs/' + img_name + '.jpg' urllib.request.urlretrieve(url=img_url,filename=img_path)
3)下载煎蛋网中图片数据:数据经过加密
# 煎蛋网图片 import requests from lxml import etree import base64 import os if not os.path.exists('./jiandan'): os.mkdir('./jiandan') headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } url = 'http://jandan.net/ooxx' res1 = requests.get(url, headers=headers).text tree = etree.HTML(res1) span_list = tree.xpath('//span[@class="img-hash"]/text()') for span_hash in span_list: img_url = 'http:' + base64.b64decode(span_hash).decode('utf8') img_data = requests.get(url=img_url, headers=headers).content filepath = './jiandan/' + img_url.split('/')[-1] urllib.request.urlretrieve(url=img_url, filename=filepath) print(filepath,'下载完成!') print('over')
4)下载站长素材中的简历模板数据
import requests from lxml import etree import random import os headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } if not os.path.exists('./jianli'): os.mkdir('./jianli') for i in range(1,4): if i == 1: url = 'http://sc.chinaz.com/jianli/free.html' else: url = 'http://sc.chinaz.com/jianli/free_%s.html' % (i) response = requests.get(url=url, headers=headers) response.encoding = 'utf8' res = response.text tree = etree.HTML(res) a_list = tree.xpath('//a[@class="title_wl"]') for a in a_list: name = a.xpath('./text()')[0] jl_url = a.xpath('./@href')[0] response = requests.get(url=jl_url, headers=headers) response.encoding = 'utf8' res1 = response.text tree = etree.HTML(res1) download_url_list = tree.xpath('//div[@class="clearfix mt20 downlist"]/ul/li/a/@href') download_url = random.choice(download_url_list) res3 = requests.get(url=download_url, headers=headers).content filepath = './jianli/' + name + '.rar' with open(filepath, 'wb') as f: f.write(res3) print(name, '下载完成!') print('over')

5)解析所有城市名称(https://www.aqistudy.cn/historydata/)
import requests from lxml import etree url = 'https://www.aqistudy.cn/historydata/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } res = requests.get(url=url, headers=headers).text tree = etree.HTML(res) city_list = tree.xpath('//div[@class="bottom"]/ul/li/a/text() | //div[@class="bottom"]/ul/div[2]/li/a/text()') # 可以用逻辑运算符,这里 | 表示或的关系 city = ''.join(city_list)
5、xpath插件安装
1)按照下图步骤点击扩展程序
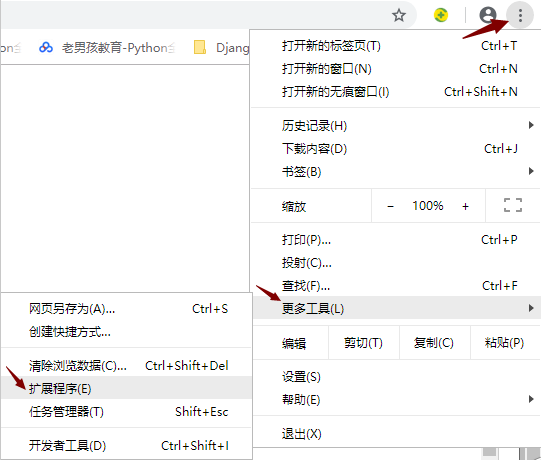
2)将开发者模式打开

3)点击添加扩展程序

4)此时重启浏览器,按"ctrl + shift + x",便可使用插件验证xpath表达式

6、图片懒加载
示例网站:http://sc.chinaz.com/tupian/hunsha.html
import requests from lxml import etree import os import urllib if not os.path.exists('./tupian'): os.mkdir('./tupian') url = 'http://sc.chinaz.com/tupian/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } response = requests.get(url=url, headers=headers) response.encoding = 'utf8' res = response.text tree = etree.HTML(res) url_list = tree.xpath('//div[@id="container"]/div/div/a/img/@src2') # img标签有伪属性src2,当图片滚动到视野内时变为 src for url in url_list: filepath = './tupian/' + url.rsplit('/',1)[-1] urllib.request.urlretrieve(url, filepath) print(filepath, '下载完成!') print('over')
7、代理ip
免费:http://www.goubanjia.com,收费:快代理https://www.kuaidaili.com和西祠代理
import requests url = 'https://www.baidu.com/s?wd=ip' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } page_text = requests.get(url, headers=headers, proxies={'https':'61.7.170.240:8080'}).text with open('./ip.html','w',encoding='utf8') as f: f.write(page_text)
8、总结:目前学过的反爬机制
- robots.txt
- UA
- 数据加密
- 懒加载
- 代理IP

 浙公网安备 33010602011771号
浙公网安备 33010602011771号