
python中使用Redis
一、Redis简介
redis是一个非常重要的非关系型(No-Sql)数据库,数据库分两种类型(关系型数据库和非关系型数据库),我们之前学习的mysql数据库是一种典型的关系型数据库,而redis是一种典型的非关系型数据库。
redis不再像mysql那样按照一对多或者一对一的那种关系存储,而是以key-value的形式创建结构,它没有表和字段一说,只有key-value,简单,直接,易操作。
redis对比memcache数据库(也是一种非关系型数据库)的共同点:
- 将数据缓存到内存中;
- 属于key-value结构;
不同点:
- redis可以做持久化(即将数据保存到磁盘上,相比mencache更安全);
- redis支持更丰富的数据类型,value可以是字符串、链表、哈希,集合,而mencache的value只能是字符串;
二、Redis安装和基本使用
1、redis下载并安装
本文以下载Redis-x64-3.2.100.msi为例,下载地址>>>
下载地址:https://github.com/MicrosoftArchive/redis/releases
2、安装完成后启动服务器(端口号6379)
redis-server.exe是服务端,双击即可运行服务端
redis-cli.exe是客户端,双击如下图
3、使用

三、python操作redis
1、下载redis
pip install redis
2、使用
1)连接方式一
import redis # 默认连接本机的6379,所以下面括号中的可以不写 # 参数decode_responses=True表示解码,默认为false r = redis.Redis(host='127.0.0.1', port=6379, decode_responses=True) r.set('age', '22') print(r.get('age')) # b'22' 注意:存的是字节
2)连接方式二(连接池的方式,客户端可以使用连接池中的,避免连接开销)
import redis pool = redis.ConnectionPool(host='', port=6379, decode_responses=True) r = redis.Redis(connection_pool=pool) r.set('age', '22') print(r.get('age'))
3、redis的字符串(String)操作
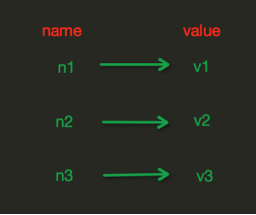
redis中的String在内存中按照一个name对应一个value来存储。如图:
1)set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
2)setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
3)setex(name, value, time)
设置值
参数:
time,过期时间(数字秒 或 timedelta对象)
4)psetex(name, time_ms, value)
设置值
参数:
time_ms,过期时间(数字毫秒 或 timedelta对象)
5)mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'})
6)get(name)
获取值
7)mget(keys, *args)
批量获取
如:
mget('ylr', 'wupeiqi') 或 r.mget(['ylr', 'wupeiqi'])
8)getset(name, value)
设置新值并获取原来的值
9)getrange(key, start, end)
获取子序列(根据字节获取,非字符)
参数:
name,Redis 的 name
start,起始位置(字节)
end,结束位置(字节)
如: "武沛齐" ,0-3表示 "武"
10)setrange(name, offset, value)
修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
参数:
offset,字符串的索引,字节(一个汉字三个字节)
value,要设置的值
11)incr(self, name, amount=1)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
name,Redis的name
amount,自增数(必须是整数)
注:同incrby
12)decr(self, name, amount=1)
自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
参数:
name,Redis的name
amount,自减数(整数)
13)append(key, value)
在redis name对应的值后面追加内容
参数:
key, redis的name
value, 要追加的字符串
4、redis的哈希(Hash)操作
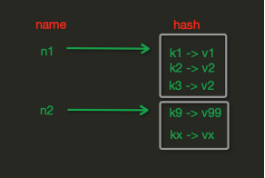
redis中Hash在内存中的存储格式如下图:
1)hset(name, key, value)
name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
name,redis的name
key,name对应的hash中的key
value,name对应的hash中的value
注:
hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
2)hmset(name, mapping)
在name对应的hash中批量设置键值对
参数:
name,redis的name
mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
如:
r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
3)hget(name,key)
在name对应的hash中获取根据key获取value
4)hmget(name, keys, *args)
在name对应的hash中获取多个key的值
参数:
name,reids对应的name
keys,要获取key集合,如:['k1', 'k2', 'k3']
*args,要获取的key,如:k1,k2,k3
如:
r.mget('xx', ['k1', 'k2'])
或
print r.hmget('xx', 'k1', 'k2')
5)hgetall(name)
获取name对应hash的所有键值
6)hlen(name)
获取name对应的hash中键值对的个数
7)hkeys(name)
获取name对应的hash中所有的key的值
8)hvals(name)
获取name对应的hash中所有的value的值
9)hexists(name, key)
检查name对应的hash是否存在当前传入的key
10)hdel(name,*keys)
将name对应的hash中指定key的键值对删除
11)hincrby(name, key, amount=1)
自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
name,redis中的name
key, hash对应的key
amount,自增数(整数)
5、redis的链式(List)操作
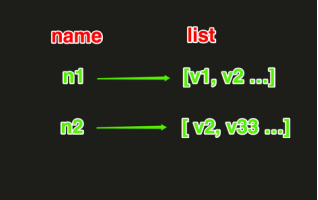
redis中的List在内存中按照一个name对应一个List来存储。如图:
1)lpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最左边
如:
r.lpush('oo', 11,22,33)
保存顺序为: 33,22,11
扩展:
rpush(name, values) 表示从右向左操作
2)lpushx(name,value)
在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
更多:
rpushx(name, value) 表示从右向左操作
3)llen(name)
name对应的list元素的个数
4)linsert(name, where, refvalue, value))
在name对应的列表的某一个值前或后插入一个新值
参数:
name,redis的name
where,BEFORE或AFTER
refvalue,标杆值,即:在它前后插入数据
value,要插入的数据
5)r.lset(name, index, value)
对name对应的list中的某一个索引位置重新赋值
参数:
name,redis的name
index,list的索引位置
value,要设置的值
6)r.lrem(name, value, num)
在name对应的list中删除指定的值
参数:
name,redis的name
value,要删除的值
num, num=0,删除列表中所有的指定值;
num=2,从前到后,删除2个;
num=-2,从后向前,删除2个;
7)lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
更多:
rpop(name) 表示从右向左操作
8)lindex(name, index)
在name对应的列表中根据索引获取列表元素
9)lrange(name, start, end)
在name对应的列表分片获取数据
参数:
name,redis的name
start,索引的起始位置
end,索引结束位置
10)ltrim(name, start, end)
在name对应的列表中移除没有在start-end索引之间的值
参数:
name,redis的name
start,索引的起始位置
end,索引结束位置
11)rpoplpush(src, dst)
从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
src,要取数据的列表的name
dst,要添加数据的列表的name
12)blpop(keys, timeout)
将多个列表排列,按照从左到右去pop对应列表的元素
参数:
keys,redis的name的集合
timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞更多:
r.brpop(keys, timeout),从右向左获取数据
13)brpoplpush(src, dst, timeout=0)
从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
src,取出并要移除元素的列表对应的name
dst,要插入元素的列表对应的name
timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
6、redis的集合(Set)操作
Set集合就是不允许重复的列表
1)sadd(name,values)
name对应的集合中添加元素
2)scard(name)
获取name对应的集合中元素个数
3)sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
4)sdiffstore(dest, keys, *args)
获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
5)sinter(keys, *args)
获取多一个name对应集合的并集
6)sinterstore(dest, keys, *args)
获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
7)sismember(name, value)
检查value是否是name对应的集合的成员
8)smembers(name)
获取name对应的集合的所有成员
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序
1)zadd(name, *args, **kwargs)
在name对应的有序集合中添加元素
如:
zadd('zz', 'n1', 1, 'n2', 2)
或
zadd('zz', n1=11, n2=22)
2)zcard(name)
获取name对应的有序集合元素的数量
3)zcount(name, min, max)
获取name对应的有序集合中分数 在 [min,max] 之间的个数
4)zincrby(name, value, amount)
自增name对应的有序集合的 name 对应的分数
5)zrank(name, value)
获取某个值在 name对应的有序集合中的排行(从 0 开始)
更多:
zrevrank(name, value),从大到小排序
6)zrem(name, values)
删除name对应的有序集合中值是values的成员
如:zrem('zz', ['s1', 's2'])
7、其他常用操作
1)delete(*names)
根据删除redis中的任意数据类型
2)exists(name)
检测redis的name是否存在
3)keys(pattern='*')
根据模型获取redis的name
更多:
KEYS * 匹配数据库中所有 key 。
KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
KEYS h*llo 匹配 hllo 和 heeeeello 等。
KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
4)expire(name ,time)
为某个redis的某个name设置超时时间
5)rename(src, dst)
对redis的name重命名为
6)move(name, db))
将redis的某个值移动到指定的db下
7)randomkey()
随机获取一个redis的name(不删除)
8)type(name)
获取name对应值的类型
其他数据库及redis的其他方法详见博客>>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号