非确定性有穷状态决策自动机练习题Vol.1 题解 & 总结
前言
今天的成绩真就像下午老姚念总结的时候的那个同学一样,昨天刚刚考好一次,今天就又掉了......
下午找学长调昨天的T3,Jombo学长对着我的5.4k的代码和毒瘤的码风都要抓狂了,先立一个flag,以后要改变一下码风,至少找别人调代码的时候可以让别人稍微舒服一些。
今天下午好像来了一位新的学长,貌似是老师先前提到的来给我们讲数学的ckq学长?
快要放假了,今天下午机房里面颓废的风气好重......
扭动的回文串
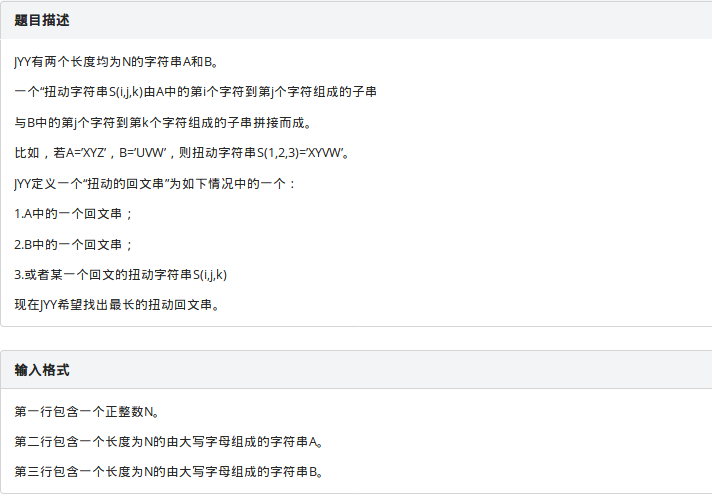
不知道上午大家考试的时候有没有读懂题,反正我当时是没有,于是去对面吵醒了还没起床的两位学长才搞懂题意......
做这个题首先我们要先发现一个规律,我们的答案一定是一个回文串的左右(其实是上下,即若取a串的回文串,在a的左边,b的右边再选取一些点)又放了一些对称的字符,而这个回文串一定是以当前回文串的中心为中心的最长的回文串,我们可以这样想,如果我们存在一种答案,使得回文串不是以当前回文串的中心为中心的最长的回文串,那么我们把答案变为回文串的中心为中心的最长的回文串结果一定不会更坏,而且这样方便我们查找,于是我们就可以枚举a的每一个点作为中心,在当前最长的回文两边二分查找另外延伸的字符串,哈希判断是否合法,就可以了,一交上去,73分,原因是我们需要再次以b串的回文串为基准计算一次,这样就没有问题了(学长讲课最后一句:难写难调)


1 #include<cstdio> 2 #include<cstring> 3 #include<algorithm> 4 #include<cstdlib> 5 #include<ctime> 6 #include<cmath> 7 const int N=3e5+10; 8 typedef unsigned long long ull; 9 char a[N],b[N]; 10 int da[N],db[N],ans,pos; 11 int n; 12 int mlc(char *cc,int *d){ 13 int len=strlen(cc+1); 14 memset(d,0,sizeof(d)); 15 int c=0,r=-1,Max=0; 16 for(int i=1;i<=len;++i){ 17 if(i > r) d[i]=1; 18 else d[i]=std::min(r-i+1,d[2*c-i]); 19 while(i-d[i] >= 1 && i+d[i] <= len){ 20 if(cc[i-d[i]]==cc[i+d[i]]) 21 d[i]++; 22 else break; 23 } 24 if(i+d[i]-1 > r){ 25 c=i; 26 r=i+d[i]-1; 27 } 28 if(d[i] > Max) Max=d[i]; 29 } 30 return Max-1; 31 } 32 ull bas=233,ha[N],hb[N],mi[N]; 33 bool Judge(int pos,int lb,int rb){ 34 ull haha=ha[lb]-ha[pos-1]*mi[lb-pos+1]; 35 ull hahb=hb[rb]-hb[rb+lb-pos+1]*mi[lb-pos+1]; 36 return haha==hahb; 37 } 38 int main(){ 39 freopen("A.in","r",stdin); 40 freopen("A.out","w",stdout); 41 scanf("%d",&n); 42 n=n*2+1; 43 mi[0]=1; 44 for(int i=1;i<=n;++i){ 45 if(i & 1) a[i]='#'; 46 else scanf(" %c",&a[i]); 47 mi[i]=mi[i-1]*bas; 48 } 49 for(int i=1;i<=n;++i){ 50 if(i & 1) b[i]='#'; 51 else scanf(" %c",&b[i]); 52 } 53 ans=std::max(ans,mlc(a,da)); 54 ans=std::max(ans,mlc(b,db)); 55 for(int i=1;i<=n;++i){ 56 ha[i]=ha[i-1]*bas+a[i]; 57 } 58 for(int i=n;i>=1;--i){ 59 hb[i]=hb[i+1]*bas+b[i]; 60 } 61 for(int i=1;i<=n;++i){ 62 int l=1,r=i-da[i]; 63 while(l <= r){ 64 int mid=(l+r)>>1; 65 if(Judge(mid,i-da[i],i+da[i]-2)) r=mid-1; 66 else l=mid+1; 67 } 68 ans=std::max(ans,da[i]-1+i-da[i]-l+1); 69 } 70 for(int i=n;i>=1;--i){ 71 int l=1,r=i-db[i]+2; 72 while(l <= r){ 73 int mid=(l+r)>>1; 74 if(Judge(mid,i-db[i]+2,i+db[i])) r=mid-1; 75 else l=mid+1; 76 } 77 ans=std::max(ans,db[i]-1+i-db[i]-l+3); 78 } 79 printf("%d\n",ans); 80 return 0; 81 }
^_^
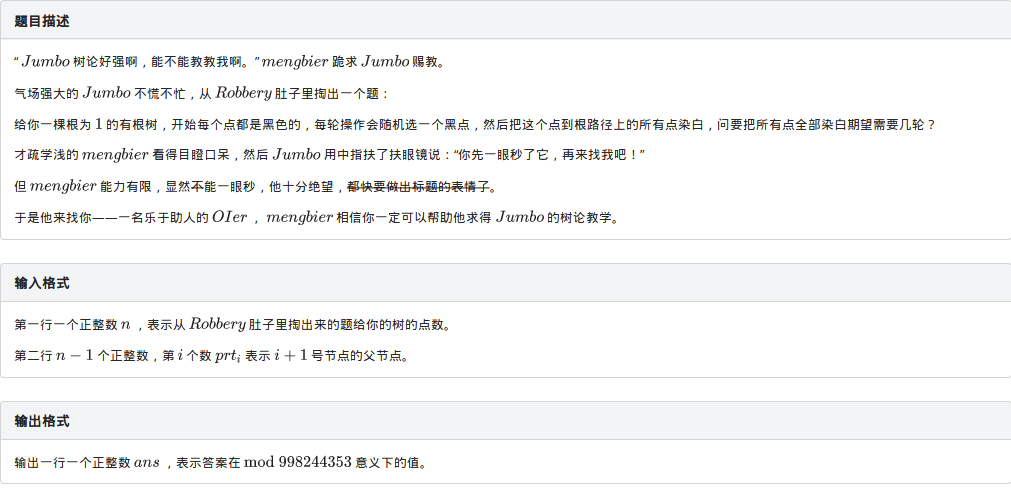
这题不就是还在校的两位学长的互黑并且还拉上了刚走的robbory学长吗其实这道题并不怎么难,只是考场上我一看到期望就直接害怕了,就没有详细去想,其实这道题和学长昨天晚上讲的例题挺像的,就是反了一下,我们只需要求出每个节点的子树大小的逆元就OK了,考完试之后5min就改出来了......希望自己下次看到这类题目至少可以认真思考一下吧。
1 #include<cstdio> 2 #include<algorithm> 3 #include<cstring> 4 #include<iostream> 5 const int N=2e7+10; 6 const int Mod=998244353; 7 typedef long long ll; 8 ll ny[N]; 9 void getny(int x){ 10 ny[1]=1; 11 for(int i=2;i<=x;++i){ 12 ny[i]=(long long)(1ll*(Mod-Mod/i)*ny[Mod%i])%Mod; 13 } 14 } 15 struct Node{ 16 int next,to; 17 }edge[N]; 18 int Head[N],tot; 19 void Add(int x,int y){ 20 edge[++tot].to=y; 21 edge[tot].next=Head[x]; 22 Head[x]=tot; 23 } 24 int siz[N]; 25 void dfs(int u,int pa){ 26 siz[u]=1; 27 for(int i=Head[u];i;i=edge[i].next){ 28 int v=edge[i].to; 29 if(v==pa) continue; 30 dfs(v,u); 31 siz[u]+=siz[v]; 32 } 33 } 34 int main(){ 35 freopen("B.in","r",stdin); 36 freopen("B.out","w",stdout); 37 int n; 38 scanf("%d",&n); 39 getny(n); 40 for(int i=1;i<n;++i){ 41 int x; scanf("%d",&x); 42 Add(x,i+1); 43 Add(i+1,x); 44 } 45 dfs(1,1); 46 long long ans=0; 47 for(int i=1;i<=n;++i) 48 ans=(ans+ny[siz[i]])%Mod; 49 printf("%lld\n",ans); 50 return 0; 51 }
第K大区间

刚刚看到这道题的时候一直以为需要分块维护区间众数,于是最初的思路一直在想如何团出来一个根号的时间复杂度能过的方法,后来突然发现这不就是前几天考的原题吗,只是k小变成了众数,之后一直在想方法是否适用,拍了一下发现能过。于是就过了这道题(不开longlong见祖宗QAQ)
于是我们可以二分答案,检验答案的时候弄一个双指针,移动过程中维护数字的出现个数使得当前区间里面的数字的出现次数都小于等于二分出的答案,其实维护过程只要使得新加入的点的个数小于答案就可以了,毕竟维护之前的数列的每一个数字都是小于答案的,破坏这一现状的只能是新加入的数字,由于数字很大,需要离散化(map常数巨大会直接挂掉)于是我们就可以用nlog2的时间复杂度来过掉这道题了。(%%%用nlog的方法A掉这道题的大佬们 orz)
1 #include<cstdio> 2 #include<cstring> 3 #include<algorithm> 4 #define int long long 5 const int N=2e5+10; 6 int a[N],b[N],cnt[N],n,k,tot; 7 int read(){ 8 int s=0,f=1; 9 char ch=getchar(); 10 while(ch < '0' || ch > '9'){ 11 if(ch=='-') f=-1; 12 ch=getchar(); 13 } 14 while(ch >= '0' && ch <= '9'){ 15 s=(s<<1)+(s<<3)+(ch^48); 16 ch=getchar(); 17 } 18 return s*f; 19 } 20 bool Judge(int x){ 21 memset(cnt,0,sizeof(cnt)); 22 int L=1,ret=0; 23 for(int i=1;i<=n;++i){ 24 int pos=std::lower_bound(b+1,b+tot+1,a[i])-b; 25 cnt[pos]++; 26 while(cnt[pos] > x){ 27 int now=std::lower_bound(b+1,b+tot+1,a[L])-b; 28 cnt[now]--; 29 L++; 30 } 31 ret+=i-L+1; 32 } 33 return ret >= k; 34 } 35 signed main(){ 36 freopen("C.in","r",stdin); 37 freopen("C.out","w",stdout); 38 n=read(); k=read(); 39 for(int i=1;i<=n;++i){ 40 a[i]=read(); 41 b[i]=a[i]; 42 } 43 k=n*(n+1)/2-k+1; 44 std::sort(b+1,b+n+1); 45 tot=std::unique(b+1,b+n+1)-b-1; 46 int l=1,r=n; 47 while(l <= r){ 48 int mid=(l+r)>>1; 49 if(Judge(mid)) r=mid-1; 50 else l=mid+1; 51 } 52 printf("%lld\n",l); 53 return 0; 54 }
收集邮票

概率题是真的神仙这道题我们可以定义f,g两个数组,f[i]表示当前买了i种邮票购买完成需要的期望次数,g[i]表示当前买了i种邮票之后购买完成的期望花费,显然f[n]=g[n]=0,之后他们的转移就满足(juruo不会markdown,图片来自https://www.luogu.com.cn/blog/league/solution-p4550):
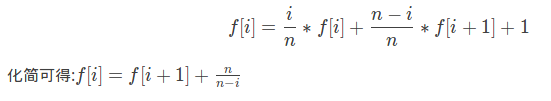
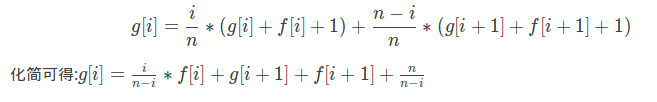
关于f的式子好理解,关于g的式子我们可以理解为倒着来计算,最后一次话费为f[i],次小为f[i]-1一直到i为1,于是我们就可以把式子理解为前缀和的样子,每一次递推都从当前位置开始向后累加,到了1号节点之后就已经满足第k次花费为k的条件了,于是最后的答案就是g[n](代码真短)
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N=1e6+10; 4 int n; 5 double f[N],g[N]; 6 int main(){ 7 freopen("D.in","r",stdin); 8 freopen("D.out","w",stdout); 9 scanf("%d",&n); 10 for(int i=n-1;i>=0;--i){ 11 f[i]=f[i+1]+(1.0*n)/(1.0*(n-i)); 12 g[i]=(1.0*i)/(1.0*(n-i))*(f[i]+1)+g[i+1]+f[i+1]+1; 13 } 14 printf("%.2lf\n",g[0]); 15 return 0; 16 }
