QuerySet
get_or_create
会返回一个tuple,第一个值是查到或者创建的数据,第二个值是一个布尔,表示是否执行了创建操作。
values and values_list
- values("comment_id")方法返回包含字典的QuerySet
<QuerySet [{'comment_id': 1}, {'comment_id': 2}]>
- values_list() 方法返回一个包含元组的QuerySet:
<QuerySet [(1,), (2,)]>
如果您使用values_list()单个字段,则可以使用flat=True返回单个值的QuerySet而不是1个元组:
<QuerySet [1, 2]>
defer和only
- Defer方法的用途是查询数据库时跳过指定的字段,比如下面查询时将跳过每篇Entry的headline和body字段。当你不需要在查询结果中使用headline和body字段时,使用defer方法可以防止将headline和body载入内存,从而节省空间。一篇文章可能没啥关系,但文章很多时,节省的内存空间不可忽视。
- Only方法与defer方法作用类时,只不过only方法是指定需要载入的字段。比如下面查询将只会载入body和pub_date。
原文链接:https://blog.csdn.net/weixin_42134789/article/details/102639721
prefetch_related和select_related
- select_related 针对Forenkey字段使用
- prefetch_related 针对ManyToManyField字段使用
Subquery
- 用于子查询
from django.db.models import Subquery
ApprovalConfigRelation.objects.exclude(
approval_config_key__in=Subquery(
ApprovalConfig.objects.values("approval_config_key")
)
annotate
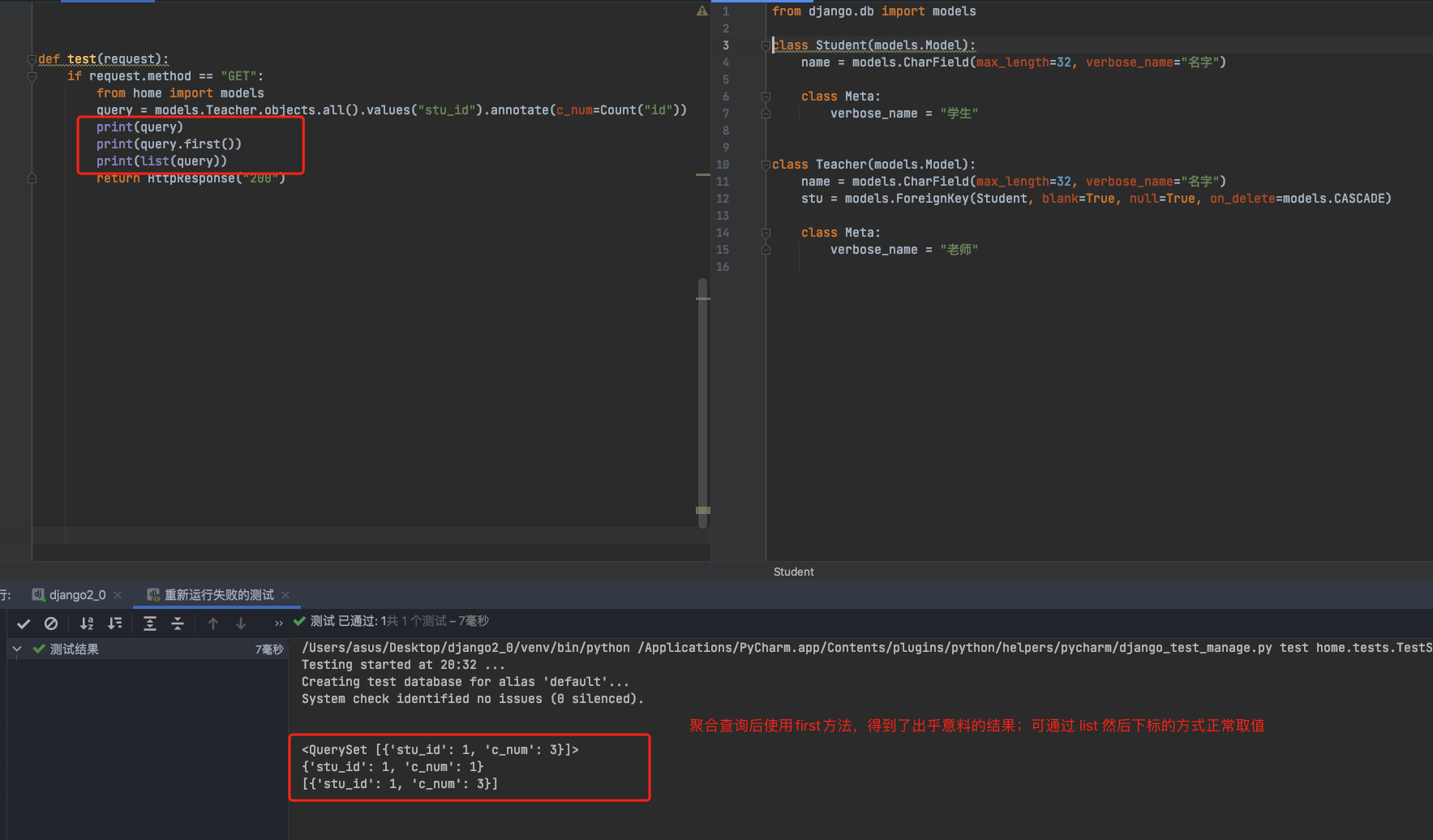
- 聚合函数需要和annotate配合才能使用,返回值里面会多个refer_count属性,就是你聚合的结果。
result = Template.objects.all().annotate(
refer_count=Count("approvalconfigrelation")
)
F
针对对象某字段的改变,使用数据库层面计算,而不是python代码层面计算
Reporter.objects.all().update(stories_filed=F('stories_filed') + 1)
注意
- F() 赋值在 Model.save() 之后持续存在
reporter = Reporters.objects.get(name='Tintin')
reporter.stories_filed = F('stories_filed') + 1
reporter.save()
reporter.name = 'Tintin Jr.'
reporter.save()
在这种情况下,stories_filed 将被更新两次。如果最初是 1,最终值将是 3。这种持久性可以通过在保存模型对象后重新加载来避免,例如,使用 obj.refresh_from_db()。
https://docs.djangoproject.com/zh-hans/3.2/ref/models/expressions/
意外的结果
Django版本 1.11.8、2.0。