网络通信_黏包、subprocess、struct模块
关于cmd黑窗口里面的快捷方法:
输入文件的前几个关键字,加tab就可以出现神奇的效果!
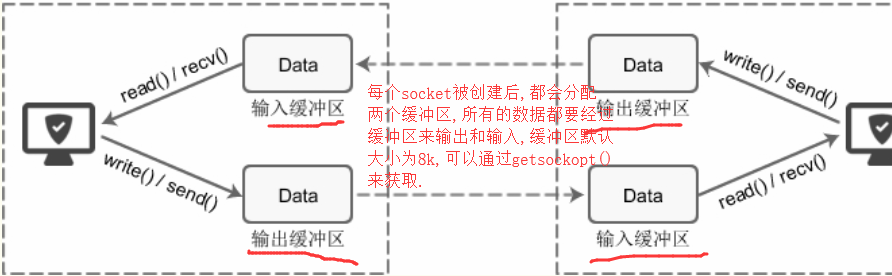
关于缓冲区:
-
缓冲区作用:

-
关于缓冲区的源码解释:


''' 源码解释: Receive up to buffersize bytes from the socket. 接收来自socket缓冲区的字节数据, For the optional flags argument, see the Unix manual. 对于这些设置的参数,可以查看Unix手册。 When no data is available, block untilat least one byte is available or until the remote end is closed. 当缓冲区没有数据可取时,recv会一直处于阻塞状态,直到缓冲区至少有一个字节数据可取,或者远程端关闭。 When the remote end is closed and all data is read, return the empty string. 关闭远程端并读取所有数据后,返回空字符串。 ''' ----------服务端------------: # 1,验证服务端缓冲区数据没有取完,又执行了recv执行,recv会继续取值。 import socket phone =socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.bind(('127.0.0.1',8080)) phone.listen(5) conn, client_addr = phone.accept() from_client_data1 = conn.recv(2) print(from_client_data1) from_client_data2 = conn.recv(2) print(from_client_data2) from_client_data3 = conn.recv(1) print(from_client_data3) conn.close() phone.close() # 2,验证服务端缓冲区取完了,又执行了recv执行,此时客户端20秒内不关闭的前提下,recv处于阻塞状态。 import socket phone =socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.bind(('127.0.0.1',8080)) phone.listen(5) conn, client_addr = phone.accept() from_client_data = conn.recv(1024) print(from_client_data) print(111) conn.recv(1024) # 此时程序阻塞20秒左右,因为缓冲区的数据取完了,并且20秒内,客户端没有关闭。 print(222) conn.close() phone.close() # 3 验证服务端缓冲区取完了,又执行了recv执行,此时客户端处于关闭状态,则recv会取到空字符串。 import socket phone =socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.bind(('127.0.0.1',8080)) phone.listen(5) conn, client_addr = phone.accept() from_client_data1 = conn.recv(1024) print(from_client_data1) from_client_data2 = conn.recv(1024) print(from_client_data2) from_client_data3 = conn.recv(1024) print(from_client_data3) conn.close() phone.close() ------------客户端------------ # 1,验证服务端缓冲区数据没有取完,又执行了recv执行,recv会继续取值。 import socket import time phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) phone.send('hello'.encode('utf-8')) time.sleep(20) phone.close() # 2,验证服务端缓冲区取完了,又执行了recv执行,此时客户端20秒内不关闭的前提下,recv处于阻塞状态。 import socket import time phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) phone.send('hello'.encode('utf-8')) time.sleep(20) phone.close() # 3,验证服务端缓冲区取完了,又执行了recv执行,此时客户端处于关闭状态,则recv会取到空字符串。 import socket import time phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) phone.send('hello'.encode('utf-8')) phone.close()
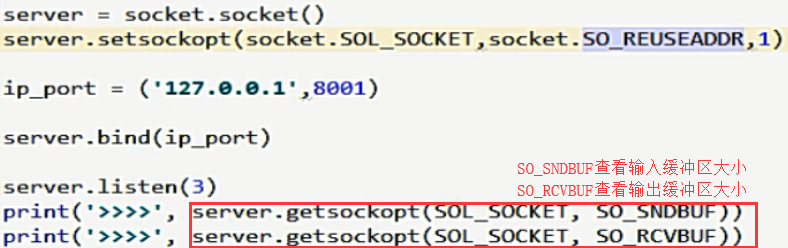
如何查看输入和输出缓冲区 server.getsockopt():
关于subprocess.Popen():
subprocess.popen是用来替代os.popen(该方法用于从一个命令打开一个管道),该模块允许我们创建子进程,连接windows的输入/输出/错误管道,还有获得返回值(应用场景:进入到cmd输入环境,然后再执行一系列的指令,并获取返回值)
该方法有以下参数:
args:shell命令,可以是字符串,或者序列类型,如list,tuple。
bufsize:缓冲区大小,可不用关心
stdin,stdout,stderr:分别表示程序的标准输入,标准输出及标准错误
shell:与上面方法中用法相同
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env=None,则默认从父进程继承环境变量
universal_newlines:不同系统的的换行符不同,当该参数设定为true时,则表示使用\n作为换行符
import subprocess cmd = input('请输入指令>>>') res = subprocess.Popen( cmd, #字符串指令:'dir','ipconfig',等等 shell=True, #使用shell,就相当于使用cmd窗口 stderr=subprocess.PIPE, #标准错误输出,凡是输入错误指令,错误指令输出的报错信息就会被它拿到 stdout=subprocess.PIPE, #标准输出,正确指令的输出结果被它拿到 ) print(res.stdout.read().decode('gbk')) print(res.stderr.read().decode('gbk'))
stderr:标准错误
stdout:标准正确
关于粘包现象:
tcp粘包现象中的第一种:接受时接收方没有及时接收缓冲区的包,造成多个包接收(服务端发送了很大的数据(网络协议报头+数据最多1500,超过就分片发送),客户端只收了一小部分,客户端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)发生数据错误
tcp粘包现象第二种:发送数据时间间隔很短,数据也很小,会合到一起,产生粘包,发生数据错误.
粘包的原因:主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓.
struct模块 :
服务端
import socket import subprocess import struct server = socket.socket() ip_port = ('127.0.0.1',8001) server.bind(ip_port) server.listen() conn,addr = server.accept() while 1: from_client_cmd = conn.recv(1024) print(from_client_cmd.decode('utf-8')) #接收到客户端发送来的系统指令,我服务端通过subprocess模块到服务端自己的系统里面执行这条指令 sub_obj = subprocess.Popen( from_client_cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, #正确结果的存放位置 stderr=subprocess.PIPE #错误结果的存放位置 ) #从管道里面拿出结果,通过subprocess.Popen的实例化对象.stdout.read()方法来获取管道中的结果 std_msg = sub_obj.stdout.read()+ sub_obj.stderr.read() #为了解决黏包现象,我们统计了一下消息的长度,先将消息的长度发送给客户端,客户端通过这个长度来接收后面我们要发送的真实数据 std_msg_len = len(std_msg) print('指令的执行结果长度>>>>',len(std_msg)) msg_lenint_struct = struct.pack('i',std_msg_len) #封装的数据为4个字节 conn.send(msg_lenint_struct+std_msg)
思路:首先拿到要执行的命令,执行后得到数据,将数据的长度用struct.pack()方法封包成4个字节,将4个字节和后面的数据一起过去,就不会产生黏报.(struct.pack()就是解决数据长度不固定,容易跟后面的数据产生黏包的问题)
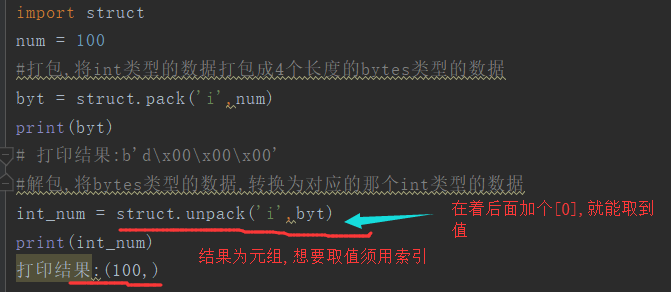
客户端(解包后是一个元组的形式,记得用索引取值[0])
while 1 : cmd = input('>>>').strip() client.send(cmd.encode('utf-8')) # 1,接受固定长度 head_bytes = client.recv(4) print('head_bytes',head_bytes) # 2,将head_bytes还原成原int类型 total_data_len = struct.unpack('i',head_bytes)[0] print('总长度:----',total_data_len) # 3,循环接受总数据 total_data = b'' # send(5) while total_data_len - len(total_data) > 1024: data = client.recv(1024) total_data += data total_data=total_data+client.recv(total_data_len - len(total_data)) print(total_data.decode('gbk')) client.close()
思路:因为双方规定了报头的格式,所以recv()时就可以每次固定的取4个字节,再用struct.unpack()[0]进行解包,得到后面真实的数据长度,设置个技术器,我循环着接收,将数据累加到这个变量里,当数据总长度减去已接收到的数据长度小于1024时,就结束循环,自己手动写一次接收(只针对数据长度较小,就是struct()能够封包的时候.
如果数据量很大,需要将长度写进个字典,然后将字典的长度struct()封包,发给对方,对方解包后,得到一个字典,得到总数据大小,准备循环着接受,条件就是写入的数值长度,小于总数据的长度).
-
传送很大的视频文件时,数字很大很长,struct无法承受,需要将真实的数据长度,装进个字典,再用struct封包,目的是将数值变小,能正常使用struct模块.
服务端
import socket import struct import json,os server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(("127.0.0.1",8001)) server.listen(5) conn,addr = server.accept() data_js = conn.recv(4) dict_data_len = struct.unpack("i",data_js)[0] dic = json.loads(conn.recv(dict_data_len).decode("utf-8")) name = dic["filename"] total_data_len= dic["filesize"] file_path = os.path.join(r"E:\360文件",name) count = 0 with open(file_path,"wb")as f: while count < total_data_len: n = conn.recv(1024) f.write(n) count += 1024 print("接受完毕")
思路:先接受4个字节,得到后面字典的长度,recv(字典的长度),打开字典,得到数据的真实长度,循环着接收,当已接收的长度大于或等于数据的真实长度就终止循环
import socket import struct import json import os client=socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(("127.0.0.1",8001)) #上传 file_size = os.path.getsize("simida.mp4") data = {"filename":"simida.mp4", "filesize":file_size, } data_size = json.dumps(data).encode("utf-8") a = struct.pack("i", len(data_size)) #因为数据量很大,无法直接用struct封包,所以将len数据装进字典,减小数字的值 client.send(a) #发送后面字典的长度 client.send(data_size) #发送字典 with open("simida.mp4","rb")as f: ao = 0 while ao < file_size: data_f=f.read(1024) #每一次循环读取1024的字节长度 client.send(data_f) #发送1024字节的长度 ao += len(data_f) #给计数器做累加
思路:因为数据量很大,无法直接用struct封包给对方数据,所以将len数据装进字典是为了,减小数字的值,能正常使用struct().循环每次读取1024字节,发送,给计数器做累加,当计数器大于os.path.getsize(路径)的数值时,就终止.
关于struck的介绍:(该模块可以把(-2147483648 <= number <= 2147483647)之间的数字(int)转换成长度为4个字节的数据,进行发送.
struck的作用:将不同长度的数字转化成固定长度的字节,但是需要注意的是。(应用场景:网络传输中发送的数据长度大小不确定,对方就无法正确接受该长度,以前是专门发送了长度后,等待对方回复,确认收到后,再发送真实数据,
用该模块就能简化对方接受到数据长度后,还需回复确认,然后我再发送数据的步骤.)
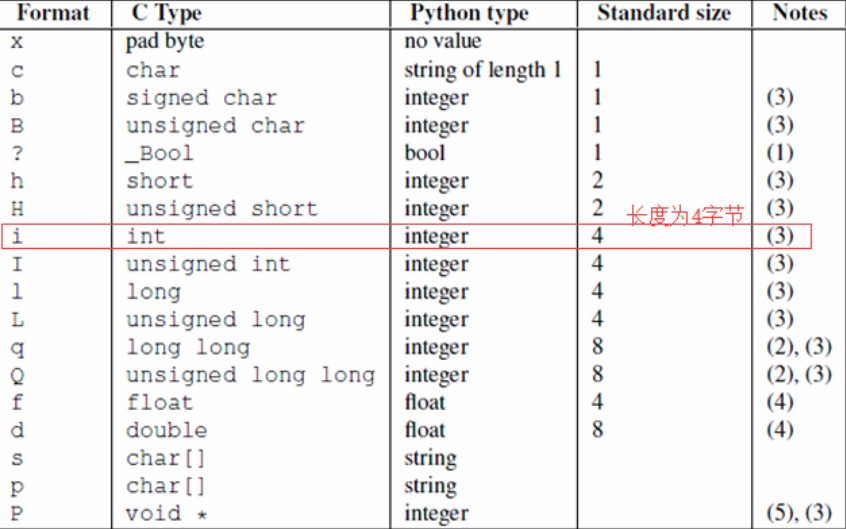
解答思路:通过struck模块将需要发送的内容的长度进行打包,打包成一个4字节长度的数据发送到对端,对端只要取出前4个字节,
然后对这四个字节的数据进行解包(注意,unpack解包后是个元组,需要索引取值 [0]),拿到你要发送的内容(int类型)的长度,然后通过这个长度来继续接收我们实际要发送的内容