
线程
一.学习线程
1.线程的概念
线程被称作轻量级的进程
计算机的执行单位以线程为单位
计算机的最小可执行是线程
进程是资源分配的基本单位,线程是可执行的基本单位,是可被调度的基本单位
线程不可以自己独立拥有资源,线程的执行必须依赖于所属进程中的资源,进程中必须至少应该有一个线程
2.线程的组成
线程是由代码段,数据段,TCB(thread control block)线程管理控制组成
3.GIL锁
GIL是全局解释锁,只有CPython解释器才会有,限制只能由一个线程来访问CPU
对于线程来说,因为有了GIL锁,所以没有真正的并行
GIL是锁线程的,意思是在同一时间内只允许一个线程访问CPU
4.线程的分类(了解)
线程分为用户级线程和内核级线程
用户级线程:对于程序员来说,这样的线程完全被程序员控制执行调度
内核级线程:对于计算机内核来说,这样的线程完全被内核控制调度
5.线程的基本代码
thread ---- 线程
import Thread ---- 操作线程的模块
import threading import Thread 常用这个去操作线程
例如:普通的线程
from threading import Thread
import time
def func():
time.sleep(1)
print("这是一个子线程")
t = Thread(target=func,args=())
t.start()
print("这是主线程")
例如:继承的方式(继承Thread类)
from threading import Thread
import time
class MyThread(Thread):
def __init__(self):
super(MyThread, self).__init__()
def run(self):
time.sleep(2)
print("这是一个子线程")
t = MyThread()
t.start()
print("这是父进程")
二.线程和进程的比较
1.CPU切换进程要比CPU切换线程慢很多
在Python中,如果IO操作过多的话,使用多线程是最好的
例如:
from threading import Thread
from multiprocessing import Process
import time
def func():
pass
if __name__ == '__main__':
start = time.time()
for i in range(100):
p = Process(target=func,args=())
p.start()
print("进程的运行速度:",time.time() - start)
if __name__ == '__main__':
start = time.time()
for i in range(100):
t = Thread(target=func,args=())
t.start()
print("线程的运行速度:",time.time() - start)
2.在同一个进程内,所有的线程共享这个进程的pid,也是就说所有线程共享所属进程的所有资源和内存地址
例如:
from threading import Thread
from multiprocessing import Process
import os
def func():
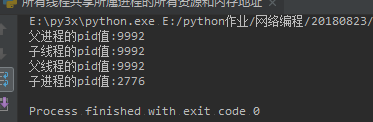
print("子进程的pid值:%s" % os.getpid())
def func1():
print('子线程的pid值:%s' % os.getpid())
if __name__ == '__main__':
p = Process(target=func,args=())
p.start()
print("父进程的pid值:%s" % os.getpid())
if __name__ == '__main__':
t = Thread(target=func1,args=())
t.start()
print("父线程的pid值:%s" % os.getpid())
打印结果:
3.在同一个进程内,所有线程共享该进程中的全局变量
例如:
from threading import Thread
def func():
global num
num -= 1
if __name__ == '__main__':
num = 100
l = []
for i in range(100):
t = Thread(target=func,args=())
t.start()
l.append(t)
[t.join() for t in l]
print(num) =====> 0
4.因为有GIL锁的存在,在Cpython中,没有真正的线程并行,但是有真正的多进程并行
当你的任务是计算密集的情况,使用多进程好
例如:
from threading import Thread
import time
def func():
global num #调用主线程的全局变量
tmp = num
time.sleep(0.001)
num = tmp - 1
if __name__ == '__main__':
num = 100
l = []
for i in range(100):
t = Thread(target=func,args=())
t.start()
l.append(t)
[t.join() for t in l] ====>异步开启一百个线程
print(num)
总结:在Cpython中,IO密集用多线程,计算密集用多进程
5.关于守护进程和守护线程的事情(注意:代码执行结束并不代表程序结束)
守护进程:要么自己正常结束,要么根据父进程的代码执行结束而结束
守护线程:要么自己正常结束,要么根据父线程的执行结束而结束
例如:守护线程
from threading import Thread
import time
def func():
time.sleep(3)
print(123)
if __name__ == '__main__':
t = Thread(target=func,args=())
t.daemon = True # 设置子线程为守护线程
t.start()
time.sleep(2)
例如:守护进程
from multiprocessing import Process
import time
def func():
time.sleep(2)
print(123)
if __name__ == '__main__':
p = Process(target=func,args=())
p.daemon = True #设置子进程为守护进程
p.start()
print(456)
守护线程:
守护线程是根据主线程执行结束才结束
守护线程不是根据主线程的代码执行结束而结束
主线程会等待普通线程执行结束再结束
守护线程会等待主线程结束再结束
所以,一般把不重要的事情设置为守护线程
三.线程的使用方法
1.锁机制 (他们锁的都是数据)
RLOCK:递归锁,是无止境的锁,但是所有的锁有一个共同的钥匙
LOCK:互斥锁,一把钥匙一把锁 ,用于保护数据安全
共享资源,又叫做临界资源,共享代码,又叫做临界代码
对临界资源进行操作时,一定要加锁
例如:LOCK互斥锁
from threading import Thread,Lock
def func():
l.acquire() #一把钥匙一个锁
print(123)
l.release()
if __name__ == '__main__':
l = Lock()
t = Thread(target=func,args=())
t1 = Thread(target=func,args=())
t.start()
t1.start()
例如:RLOCK递归锁(开了几个门,就还几次钥匙)
第一种情况:在同一个线程内,递归锁可以无止尽的acquire,但是互斥锁不行
第二种情况:在不同的线程内,递归锁是保证只能被一个线程拿到钥匙,然后无止尽的acquire,其它线程等待
from threading import Thread,RLock
def func():
l.acquire() #拿了一把钥匙,开了四个门
l.acquire()
l.acquire()
l.acquire()
print(123)
l.release() #需要将四个门都打开,其它人才能拿了钥匙开门进入
l.release()
l.release()
l.release()
if __name__ == '__main__':
l = RLock()
t = Thread(target=func,args=())
t.start()
t1 = Thread(target=func,args=())
t1.start()
2.多线程的信号量
from threading import Semaphore
例如:
from threading import Thread,Semaphore
import time,random
def func(i,s):
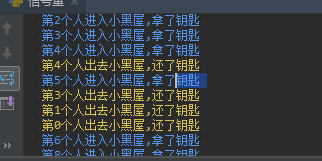
s.acquire() #拿了钥匙,锁了门
print("\033[34m 第%s个人进入小黑屋,拿了钥匙 \033[0m" % i)
time.sleep(random.randint(1,3)) #随机数,随机几秒出门
print("\033[33m 第%s个人出去小黑屋,还了钥匙 \033[0m" % i)
s.release() #还了钥匙,开了门
if __name__ == '__main__':
s = Semaphore(5) #初始化5把钥匙,也就是说允许5个人同时进入,之后其它人必须在门外等待,有人出来,他们拿了钥匙才能允许进入
for i in range(20):
t = Thread(target=func,args=(i,s))
t.start()
3.多线程的事件
from threading import Event
例如:
from threading import Thread,Event
import time
def light(e):
while 1:
if e.is_set(): (if e.is_set() = True) #如果为True的时候,绿灯亮
time.sleep(5) #绿灯亮五秒钟,此时可以通车
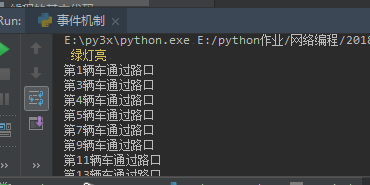
print("\033[31m 红灯亮 \033[0m") #五秒钟之后,变为红灯
e.clear() #将e.is_set()的bool值变为False
else:
time.sleep(5) #此时红灯亮五秒钟
print("\033[33m 绿灯亮 \033[0m") #五秒钟之后,变为绿灯
e.set() #将e.is_set()的bool值变为True
def car(e,i):
e.wait() #此时判断e.is_set()的bool值是True还是False
print("第%s辆车通过路口" % i) #如果是True,则绿灯亮,让通车 ,如果是False,则是红灯.不让通车
if __name__ == '__main__':
e = Event() #实例化一个事件
t = Thread(target=light,args=(e,))
t.start()
for i in range(50): #描述50辆车的进程
c = Thread(target=car,args=(e,i+1))
c.start()
4.多线程的条件
from threading import Condition
条件是让程序员自行去调度线程的一个机制
Conditon涉及的4个方法
(1)acquire() 拿钥匙,锁门
(2)release() 还钥匙,开门
(3)wait() 是指让线程阻塞住
(4)notify(int) 是指给wait发一个信号,让wait变成不阻塞
int是指 你要给多少,给wait发信号
例如:
from threading import Thread,Condition
def func(con,i):
con.acquire() #拿了钥匙,锁了门
con.wait() #让线程阻塞住
con.release() #还了钥匙,开了门
print("第%s个线程开始执行了" % i) #开始执行线程
if __name__ == '__main__':
con = Condition()
for i in range(10):
t = Thread(target=func,args=(con,i))
t.start()
while 1:
num = int(input(">>>>")) #循环输入一个数字
con.acquire() #拿了钥匙,锁了门 (主线程和10个子线程都在抢夺递归锁的一把钥匙,如果主线程抢到钥匙,主线程执行while循环,input,然后notify发信号,还钥匙,但是如果主线程执行速度特别快,极有可能接下来主线程又会拿到钥匙,那么此时哪怕其它10个子线程的wait接收到信号,但是因为没有拿到钥匙,所以其它子线程还是不会执行)
con.notify(num) #给wait发输入的数字个信号
con.release() #还了钥匙,开了门
5.线程的定时器
from threading import Timer
Timer(time,func)
time:睡眠时间,以秒为单位
func:睡眠时间过后,需要执行的任务(函数)
例如:
from threading import Timer
def func():
print(123)
Timer(5,func).start() #将该方法睡眠五秒之后再执行
6.多线程的守护线程
守护线程是根据主线程执行结束才结束
守护线程不是根据主线程的代码执行结束而结束
主线程会等待普通线程执行结束再结束
守护线程会等待主线程结束再结束
所以,一般把不重要的事情设置为守护线程
例如:
from threading import Thread
import time
def func():
time.sleep(3) #让守护线程睡3秒之后在执行
print(123) #此时打印不出来123
if __name__ == '__main__':
t = Thread(target=func,args=())
t.daemon = True #将子线程设置为守护线程
t.start()
time.sleep(2) #让主线程睡2秒之后执行结束,所以两秒之后主线程执行结束后,守护线程也就跟着结束,如果守护线程睡眠时间比主线程睡眠时间短,则守护线程会执行完
7.同一进程内的队列
import queue 适用于同一个进程内的队列,不能做多进程之间的通信
from multiprocessing import Queue 用于多进程的队列,就是专门用来作进程之间的通信(IPC)
(1)先进先出队列
import queue
q = queue.Queue()
q.put(1)
q.put(2)
q.put(3)
print(q.get()) ====> 1
print(q.get()) ====> 2
(2)后进先出队列
import queue
q = queue.LifoQueue()
q.put(5)
q.put(4)
q.put(3)
print(q.get()) ====> 3
print(q.get()) ====> 4
(3)优先级队列
例子一:
import queue
q = queue.PriorityQueue()
q.put((1,"123"))
q.put((2,"456"))
q.put((3,"789"))
print(q.get()) =====> (1,"123")
print(q.get()) =====> (2,"456")
例子二:
import queue
q = queue.PriorityQueue()
q.put(("b",123))
q.put(("c",456))
q.put(("a",123))
print(q.get()) ====> ("a",123)
print(q.get()) ====> ("b",123)
例子三:
import queue
q = queue.PriorityQueue()
q.put(("中国",123))
q.put(("美国",456))
q.put(("韩国",789))
print(q.get()) ====> ("中国",123)
优先级队列:首先保证整个队列中,所有表示优先级的东西类型必须一致
put方法接收的是一个元组类型(),第一个位置是优先级,第二个位置是数据
优先级如果是数字,直接比较数值
字符串比较的话,会先比较第一位的ASCII码,如果相等的话继续向下比较
当ASCII码相同时,会按照先进先出的原则
8.线程池
线程池:在一个池子里,放固定数量的线程,这些线程等待任务,一旦有任务来,就有线程去执行
from concurrent.futures import ThreadPoolExecutor (线程池)
from concurrent.futures import ProcessPoolExecutor (进程池)
concurrent.futures ====> 这个模块是异步调用的机制,提交的任务都是用submit
for + submit 多任务提交
shutdown ====> 是等效于Pool中的close + join,是指不允许在继续向池中增加任务,然后让父进程(线程)等待池中所有进程执行完所有任务
(1)线程池和进程池的效率比较
例子一:异步调用的线程池
from concurrent.futures import ThreadPoolExecutor
import time
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
# print(sum)
if __name__ == '__main__':
t = ThreadPoolExecutor(20)
start = time.time()
for i in range(1000):
t.submit(func,i)
t.shutdown()
print("异步线程池执行的时间:",time.time() - start)
例子二:异步调用的进程池
from concurrent.futures import ProcessPoolExecutor
import time
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
# print(sum)
if __name__ == '__main__':
p = ProcessPoolExecutor(5)
start = time.time()
for i in range(1000):
p.submit(func,i)
p.shutdown()
print("异步进程池执行的时间:",time.time() - start)
例子三:异步进程池
from multiprocessing import Pool
import time
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
# print(sum)
if __name__ == '__main__':
p = Pool(5)
start = time.time()
for i in range(1000):
res = p.apply_async(func,i)
p.close()
p.join()
print("进程池异步执行时间:",time.time() - start)
总结:
不管是Pool的进程池还是ProcessPoolExecutor()的进程池,他俩执行效率相当
ThreadPoolExecutor()的效率要差很多
所以当计算密集的时候,使用多线程
(2)线程池中的方法
① map()
多任务的提交的两种方法
要么直接用for + submit 的方式去提交多个任务
要么直接使用map的方式提交任务,结果是一个生成器,采用__next__()的方式去拿结果
例如一:
from concurrent.futures import ThreadPoolExecutor
import time
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
# print(sum)
t = ThreadPoolExecutor(20)
start = time.time()
t.map(func,range(1000)) =====> 提交多个任务给池中,等效于for循环 + submit
t.shutdown()
print(time.time() - start)
例如二:
from concurrent.futures import ThreadPoolExecutor
import time
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
# print(sum)
t = ThreadPoolExecutor(20)
start = time.time()
for i in range(1000):
t.submit(func,i)
t.shutdown()
print(time.time() - start)
②多任务的返回值
例如一:
from concurrent.futures import ThreadPoolExecutor
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
return sum
t = ThreadPoolExecutor(20)
# l = []
for i in range(1000):
res = t.submit(func,i)
print(res.result())
# l.append(res)
# [print(i.result()) for i in l]
例如二:
from concurrent.futures import ThreadPoolExecutor
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
return sum
t = ThreadPoolExecutor(20)
res = t.map(func,range(1000))
t.shutdown()
# for i in res: =====> res 本身是个生成器(迭代器) 可以通过for循环拿值 也可以通过抛异常拿值
# print(i)
while 1:
try:
print(res.__next__())
except StopIteration:
break
③进程池的回调函数
from concurrent.futures import ThreadPoolExecutor
def func(num):
sum = 0
for i in range(num):
sum += i ** 2
return sum
def call_back_func(res): =====> 通过回调函数拿值
print(res.result())
t = ThreadPoolExecutor(20)
for i in range(1000):
t.submit(func,i).add_done_callback(call_back_func)
t.shutdown()
④线程池的回调函数
from threading import current_thread =====>通过这个模块拿到线程的id
from concurrent.futures import ThreadPoolExecutor
import time
def func(i):
sum = 0
sum += i
time.sleep(1)
print("这是在子线程中",current_thread())
return sum
def call_back(sum):
time.sleep(1)
print("这是在回调函数中",sum.result(),current_thread())
if __name__ == '__main__':
t = ThreadPoolExecutor(5)
for i in range(10):
t.submit(func,i).add_done_callback(call_back)
t.shutdown()
print("这是在主线程中",current_thread())
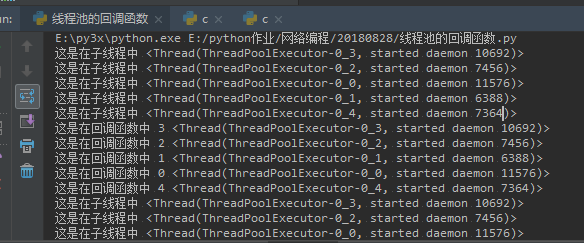
关于回调函数
不管是Pool进程池的方式,还是ProcessPoolExecutor的方式开启进程池,回调函数都是由父进程调用的,和父进程没有关系
线程池中的回调函数是子线程调用的,和父线程没有关系
父线程不一定是主线程 主线程不一定是子线程的父线程

