
并发编程
一.并发编程:
1.计算机的简介
(1).计算机的硬件组成:
主板:固化寄存器,是直接和cpu进行交互的一个硬件
cpu:中央处理器:计算(数字计算和逻辑计算)和控制(控制所有的硬件协调工作)
存储:硬盘和内存
输入设备:键盘,鼠标,话筒
输出设备:显示器,音箱,打印机
cpu寄存器-->高级缓存-->内存-->缓存-->硬盘,U盘 从左到右读写速度越来越慢,价格越来越便宜,容量越来越大
(2).计算机的核心
早期的计算机是以计算为核心的
现在的计算机是以存储为核心的
(3).计算机的发展史
第一代计算机:电子管计算器,及其耗电,体积庞大,散热量特别高
第二代计算机:晶体计算机
第三代计算机:白色大头计算机,集成电路计算机,一个板子固化几十到上百个硬件
第四代计算机:大型集成电路计算机,一个板子可以达到固化十万个硬件
第五代计算机:甚大型集成电路计算机
(4).语言的发展史:
机器语言:由0和1组成
汇编语言:例: sum n,m
高级语言:面向过程语言(C),面向对象语言(C++,JAVA,python,.net,php)
2.计算机的操作系统:
(1)操作系统理论:
操作系统是一个软件是一个能直接操纵硬件的软件
无论什么时候操作系统的目标总是:让用户用起来更加轻松,高可用,低耦合(降低相互依赖性)
(2).os操作系统的分类:
dos系统(纯编程系统),Windows系统,unix系统
(3).操作系统的作用:
操作系统就是一个协调,管理和控制计算机硬件资源和软件资源的控制程序
1.封装所有硬件的接口,让各种用户使用电脑更加轻松
2.是对计算机内所有资源进行合理的调度和分配,并且将多个进程对硬件的竞争变得有序
3.进程:
(1)进程的理论:
.dll 库 .lib 库文件 .bat批处理脚本文件 .out Linux系统中的执行文件 .exe 可执行文件,双击能运行的文件 .sh shell脚本文件
进程:是指正在执行的程序,是程序执行过程中的一次指令,也可以叫做程序一次执行过程.是一个动态的概念
(2)进程由三大部分组成:
代码段,数据段,PUB(进程控制块):进程管理控制
(3)进程的特征:
动态性,并发性,独立性,异步性
(4)进程的三大基本状态:
就绪状态:已经获得运行需要的所有资源除了CPU
执行状态:已经获得所有资源包括CPU,处于正在运行
阻塞状态:因为各种原因进程放弃了cpu导致了进程无法继续执行此过程处于内存中,继续等待获得CPU
(5):进程一个特殊状态(挂起状态):
是指因为各种原因进程放弃了CPU导致进程无法继续执行,此时进程被踢出内存
(6).进程的模块:
multiprocessing模块:是python提供主要用于多进程编程
(7)进程调度:
先来先服务(FCFS),短作业优先调度算法(SJ/PF),时间片轮转法(Round Robin/RR),多级反馈队列
(8)多进程语法:
Process(target=函数名,args=(函数的参数,))
二.多进程
1.多进程相关理论知识
(1).并行与并发
并行:
并行是指两个同时执行,比如有两条车道,在某一个时间点,两条车道上都有车在跑(资源够用,比如三个线程,四核的CPU)
并发:
并发是指资源有限的情况下,两者交替轮流使用资源,比如只有一条车道(单核CPU资源),那么就是A车先走,在某个时刻A车退出把道路让给B车走,B车走完继续给A走,交替使用,目的是提高效率
区别:
并行是从微观上,也就是在一个精确时间片刻,有不同的程序在执行,这就要求必须有多个处理器
并发是从宏观上,是一个时间段上可以看出是同时执行的,比如:一个服务器同时处理多个session
注意:早期单核CPU时候,对于进程也是微观上串行(站CPU角度看),宏观上并行(在人的角度上看就是同时有很多程序在执行)
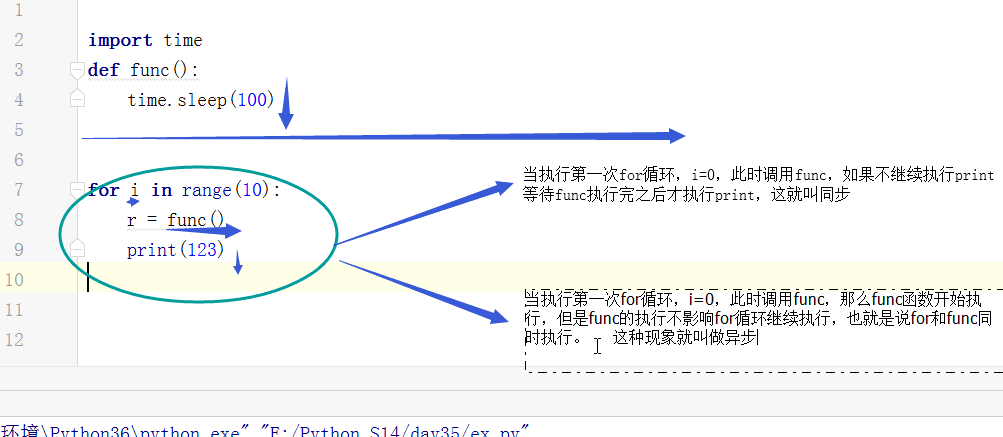
(2)同步与异步
同步:
一个任务的完成需要依赖另一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列,要么成功都成功,要么失败都失败,两个任务的状态可以保持一致.
异步:
异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了,至于被依赖的任务最终是否真正完成,依赖他的任务无法确定,所以他不是可靠的任务序列.
(3)阻塞与非阻塞
①同步阻塞形式
效率最低,专心排队,什么别的事都不做
②异步阻塞形式
异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知的时候被阻塞
③同步非阻塞形式
比如一个你在排队的过程中打电话同时还要观看队伍还有多长的时候,打电话和观察队伍算是两个操作,需要这两种行为来回切换,所以效率比较低下
④异步非阻塞形式
比如你领了排队号,这时突然需要出去拿个东西,你跟保安说了一下,叫到你号的时候给你打个招呼,这两种不同的操作没有来回的切换,所以这就是异步非阻塞的形式,我可以做我自己的事情,同时我也没有影响到他人
(4)进程的三态状态装换图

2.开启子进程的两种方法
(1)第一种方法:普通的方法
Process(target = 函数名,args = (父进程给子进程传递的参数,)) =====>元组类型
from multiprocessing import Process
import time
import os
def func(n):
time.sleep(5)
print("子进程%s,父进程是%s" % (os.getpid(),os.getppid())) #getpid() 获取当前进程的pid
if __name__ == '__main__':
p = Process(target=func,args=(1,)) #实例化一个进程对象
p.start() #开始一个子进程,底层调用的是p.run()
time.sleep(1)
print("父进程%s,父亲的进程是%s" % (os.getpid(),os.getppid())) #getppid() 获取当前进程的父级进程的pid
(2)继承的方式
自定义类:继承Process父类
from multiprocessing import Process
class MyProcess(Process):
def __init__(self,name):
super(MyProcess, self).__init__() #调用父类中的__init__方法
self.name = name
def run(self):
print("这里是以继承类的方式开启的子进程,他的名字是%s" % self.name)
if __name__ == '__main__':
p = MyProcess("alex") #实例化一个对象,赋名字属性
p.start() #开始一个子进程 #解释器告诉操作系统,去帮我开启一个进程 (就绪状态)
p.run() #调用类中的run()方法 #告诉操作系统,现在马上帮我执行这个子进程 (执行状态)
3.多进程的常用方法
①start() 解释器告诉操作系统,去帮我开启一个进程(就绪状态)
processing import Process
import time
import os
def func(n):
time.sleep(2)
print("儿子的pid是%s,父亲的pid是%s" % (os.getpid(),os.getppid()))
if __name__ == "__main__":
p = Process(target=func,args=(1,))
p.start()
print("父亲的pid是%s,父亲法人父亲pid是%s" % (os.getpid(),os.getppid()))
②join() 是让主进程等待子进程完成 (让异步变同步)
现象: 主进程执行到这句话,主进程阻塞住,等待子进程执行
from multiprocessing import Process
import time
def func():
time.sleep(4)
print("子进程:")
if __name__ == '__main__':
p = Process(target=func)
p.start()
p.join() #将异步变同步 (让父进程停留在join这句话,等待子进程执行结束之后,父进程在继续执行)
time.sleep(1)
print("父进程:")
③p.is_alive() 判断子进程是否还活着
rom multiprocessing import Process
import time
def func(i):
time.sleep(0.1)
print("子进程%s" % i)
if __name__ == '__main__':
for i in range(5):
p = Process(target=func,args=(i,))
p.start()
print(p.is_alive()) #判断子进程是否还活着
p.join()
print(p.is_alive())
返回一个bool值,如果返回True,表示进程还活着,如果返回False,表示进程死了
④p.terminate() 杀死子进程,让解释器告诉操作系统,请杀掉子进程
from multiprocessing import Process
import time
def func(i):
# time.sleep(0.1)
print("子进程%s" % i)
if __name__ == '__main__':
for i in range(5):
p = Process(target=func,args=(i,))
p.start()
print(p.is_alive())
p.terminate() #杀死p进程,让解释器高度操作系统,请杀掉p进程
time.sleep(0.1)
print(p.is_alive())
p.join()
print(p.is_alive())
4.多进程的常用属性
p.name = 给p进程一个名字
p.daemon = True 表示守护进程 p.daemon = False 表示扑通进程
p.pid 返回p进程的pid
from multiprocessing import Process
import time
def fn():
print(123)
def func():
p1 = Process(target=(fn))
p1.start()
print("in son")
if __name__ == "__main__":
p = Process(target=func,name = "alex")
p.daemon = True =====>将p进程设置为守护进程,必须要在start之前设置
p.start()
print(p.name)
print(p.pid)
time.sleep(0.01)
print("in Dad")
守护进程:(1)跟随者父进程的代码执行结束,守护进程就结束
(2)守护进程不能再创建子进程
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True之后,p不能创建自己的新进程,必须在p.start()之前设置
开启子进程的windows内部操作和Linux内部操作
(1)windows
在windows操作系统中,当开启多进程时,是把当前文件全部copy了一份给子进程,但是子进程中__name__ = __mp_main__
所以在windows操作系统,子进程除了不执行py文件中的if__name__=="__main__"以内的代码,其他所有的代码全部执行
(2)Linux
在Linux操作系统中,当开启多进程时,是把当前文件中子进程要执行的任务(函数)copy出去给子进程
所以在Linux操作系统中,子进程之执行自己的任务函数,py文件中其它的代码,子进程一律不执行
5.多进程的锁机制
锁涉及的两个操作:
(1)拿钥匙,锁门 ---> 不让别人进屋
(2)还钥匙.开门 ---> 让别人进屋
锁的特点:一把钥匙一个锁
例子:
from multiprocessing import Process,Value,Lock
import time
def func(num,l):
l.acquire() #拿走钥匙,锁上门,不让别人进来
for i in range(100):
num.value -= 1
print(num.value)
time.sleep(0.01)
l.release() #还钥匙,打开门,让别人进来
def func1(num,l):
l.acquire()
for i in range(100):
num.value += 1
print(num.value)
time.sleep(0.01)
l.release()
if __name__ == '__main__':
num = Value("i",100) #可以将让两个进程共享数据 Value(你要输入的数据类型,输入的参数)
l = Lock() #实例化一个锁,一个锁配一把钥匙
p = Process(target=func,args=(num,l)) #实例化一个进程对象
p.start()
p1 = Process(target=func1,args=(num,l)) #实例化一个进程对象
p1.start() #开启一个进程
p.join() #让异步变同步 (父进程会等待子进程执行完毕之后在执行)
p1.join()
print(num.value)
抢票例子:
from multiprocessing import Process,Lock #导入锁机制模块
import time
def more_ticket(i):
with open("余票1")as f:
ticket = f.read()
print("第%s个人查看还有%s张余票" % (i,ticket))
def Rob_tickets(l,i):
l.acquire() #拿钥匙,锁住门,不让别人进来
with open("余票1")as f:
ticket = int(f.read()) #拿到票
time.sleep(0.01)
if ticket > 0:
print("\033[32m 第%s个人抢到票 \033[0m" % i)
ticket -= 1
else:
print("\033[34m 第%s个人没有抢到票 \033[0m" % i)
time.sleep(0.01)
with open("余票1","w")as f:
f.write(str(ticket)) #抢完票之后,将抢完的数记录到文件中去
l.release() #还钥匙,打开门,让别人进来
if __name__ == '__main__':
l = Lock() #实例化一个锁
for i in range(10):
p = Process(target=more_ticket,args = (i+1,))
p.start()
p.join()
for i in range(10):
p1 = Process(target=Rob_tickets,args=(l,i+1))
p1.start()
p1.join()
6.多进程的信号量机制
sem = Semaphore(n)
n:是初始化一个锁配几把钥匙,是int类型
l.acquire() 拿钥匙锁门
l.release() 还钥匙开门
例子:
from multiprocessing import Process,Semaphore
import time
import random
def func(s,i):
s.acquire() #拿钥匙 锁门
print("\033[31m 第%s个人进入理发店 \033[0m" % i)
time.sleep(random.randint(5,10))
print("\033[36m 第%s个人出去了理发店 \033[0m" % i)
s.release() #还钥匙开门
if __name__ == '__main__':
s = Semaphore(5) #初始化五把钥匙,也就是说允许五个人同时进入,之后其它人必须等待,有人出来还了钥匙才能进入
for i in range(20):
p = Process(target=func,args=(s,i))
p.start()
信号量机制比锁机制多了一个计数器,这计数器是用来记录当前剩余几把钥匙的
当计数器为0时,表示没有钥匙了,此时acqurie()处于阻塞状态
对于计数器来说,每acquire一次,计数器内部就减1,release一次,计数器就加1
7.多进程事件机制
from multiprocessing import Event
e = Event()
事件是通过is_set()的bool值,去表示e.wait()的阻塞状态
当is_set()的bool值为False时,e.wait()是阻塞状态
当is_set()的bool值为True时,e.wait()是非阻塞状态
当使用set()的时候,是把is_set()的bool值变为True
当使用clear()的时候,是把is_set()的bool值变为False
例子:
from multiprocessing import Process,Event
e = Event()
print(e.is_set()) ====>False
e.set() 将e.is_set() 的bool值变为True
e.wait() 非阻塞状态
print(123) =====>123
e.clear() 将e.is_set() 的bool值变为False
e.wait() 阻塞状态
print(456) 打印不出来
信号灯模拟:
from multiprocessing import Process,Event
import time
def light(e):
while 1:
if e.is_set(): #true 代表绿灯亮
time.sleep(5) #绿灯亮五秒之后变成红灯
print("\033[31m 红灯亮 \033[0m ")
e.clear() #将e.is_set()的bool值变为False
else: #False
time.sleep(5) #等待五秒之后红灯变为绿灯
print("\033[33m 绿灯亮 \033[0m ") #绿灯亮
e.set() #将e.is_set()的bool值变为true
def car(i,e):
e.wait()
print("第%s个车通过" % i)
if __name__ == '__main__':
e = Event()
p = Process(target=light,args=(e,))
p.start()
for i in range(50):
p1 = Process(target=car,args=(i+1,e))
p1.start()
8.消费者生产者模型 (主要用于解耦) 耦合度
需要借助队列来实现
栈:先进先出(First In Last Out) 简称:FILO
队列:先进先出(First In First Out) 简称:FIFO
import Queue (不能进行多进程之间的数据传输)
form multiprocessing import Queue (队列是安全的,无需加锁)
①q = Queue(num) num = q.maxsize 队列的长度(可以自定义)
②q.get() 阻塞等待获取数据,如果有数据就直接获取,如果没有数据就阻塞等待
③q.put() 如果可以继续往队列中放入数据就直接放入,如果不能放就阻塞等待
④q.get_nowait() 不阻塞,如果有数据就直接获取,没有数据就报错
⑤q.put_nowait() 不阻塞,如果可以继续往队列中放数据,就直接放,如果不能放就报错
(1)方法一
from multiprocessing import Process,Queue
def consumer(q,name):
while 1:
info = q.get() #如果有数据就直接获取,如果没有数据就阻塞等待
if info: #判断info有没有数据,如果有数据就向下执行
print("%s拿走了%s" % (name,info))
else: #当消费者获得队列中的数据的时候,如果获得None,就是获得了生产者不再生产数据的标识
break #此时,消费者结束就可以了
def producter(q,product):
for i in range(20): #生产20个娃娃
info = product + "的娃娃%s号" % i
q.put(info) #如果可以继续往队列中放数据,就直接放,如果不能放就阻塞等待
q.put(None) #让生产者生产完数据之后,给消费者一个不在生产数据的标识
if __name__ == '__main__':
q = Queue(10)
p_pro = Process(target = producter,args=(q,"布朗熊"))
p_con = Process(target = consumer,args=(q,"刘某某"))
p_pro.start()
(2)方法二
from multiprocessing import Process,Queue
def consumer(q,name):
while 1:
info = q.get()
if info:
print("%s拿走了%s" % (name,info))
else: #当消费者获得队列中的数据时,如果接受到的是None,就是获得到了生产者不再生产数据的标识
break #此时消费者结束即可
def producter(q,product):
for i in range(20):
info = product + "的娃娃%s号" % i
q.put(info)
if __name__ == '__main__':
q = Queue(10)
p_pro = Process(target=producter,args=(q,"布朗熊"))
p_con = Process(target=consumer,args=(q,"刘某某"))
p_pro.start()
p_con.start()
p_pro.join() #主进程等待生产者进程结束后再执行以下代码
q.put(None) #有几个消费者就需要接受几个结束的标识
(3)方法三
from multiprocessing import JoinableQueue
q = JoinableQueue() 可连接队列,继承Queue,可以使用Queue里面的所有方法
q.join() 用于生产者,等待q.task_done()的返回结果,通过返回结果,生产者就可以获得消费者当前消费了多少个数据
q.task_done() 用于消费者,是指每消费者队列中一个数据,就给join返回一个标识
from multiprocessing import Process,JoinableQueue
def consumer(q,name):
while 1:
info = q.get()
print("%s拿走了%s" % (name,info))
q.task_done()
def producter(q,product):
for i in range(20):
info = product + "的娃娃%s号" % i
q.put(info)
q.join()
if __name__ == '__main__':
q = JoinableQueue(10)
p_pro = Process(target=producter,args=(q,"布朗熊"))
p_pro1 = Process(target=producter,args=(q,"兔子"))
p_con = Process(target=consumer,args=(q,"刘某某"))
p_con1 = Process(target=consumer,args=(q,"牛某某"))
p_con.daemon = True #需要将消费者进程设置为守护进程
p_con1.daemon = True #有几个消费者就需要将多少个消费者进程设置为守护进程
p_pro.start()
p_pro1.start()
p_con.start()
p_con1.start()
p_pro.join() #父进程需要等待生产者进程完毕之后再结束进程
p_pro1.join()
9.管道(是不安全的,没有锁机制) 全双工
管道是用于多进程之间通信的一种方式
单管道:
在单进程中使用管道:那么就是con1收数据,con2发数据
如果是con1发数据,con2收数据
多管道:
在多进程中使用管道,那么就是必须是父进程使用con1收数据,子进程必须con2发数据
父进程使用con1发数据,子进程必须con2收数据
父进程使用con2收数据,子进程必须con1发数据
父进程使用con2发数据,子进程必须con1收数据
在管道中有一个著名的错误叫做EOFError:是指父进程中如果关闭了发送端,子进程还继续接收数据,那么就会引发EOFError错误
(1)单进程管道 (双向收发)
C1给C2发数据,C2收数据
C2给C1发数据,C1收数据
例如:
from multiprocessing import Pipe
con1,con2 = Pipe()
con1.send("abc")
print(con2.recv())
con2.send(123)
print(con1.recv())
(2)多进程管道
例如:消费者生产者
from multiprocessing import Pipe,Process
def func(con):
con1,con2 = con
con1.close() #子进程使用con2和父进程通信
while 1:
try:
print(con2.recv()) #当主进程的con1发数据时,子进程要死循环的去接收
except EOFError: #如果主进程的con1发完数据并关闭con1,子进程的con2继续接收时,就会报错,使用try方法,获取错误
con2.close() #获取到错误,就是指子进程已经把管道中所有数据都接收完了,所以用这种方法关闭管道
break
if __name__ == '__main__':
con1,con2 = Pipe()
p = Process(target=func,args=((con1,con2),))
p.start()
con2.close() #在父进程中,使用con1和子进程通信,所以不需要con2,就提前关闭
for i in range(10): #生产数据
con1.send(i) #给子进程的con2发送数据
con1.close() #生产完数据,关闭父进程这一端的管道
10.进程之间的共享内存
from multiprocessing import Manager
m = Manager()
num = m.dict({key:value})
num = m.list([1,2,3])
例如:
from multiprocessing import Manager,Process
def func(num):
num[0] -= 1
print("子进程中num的值是:",num) =====>[0,2,3]
if __name__ == '__main__':
m = Manager()
num = m.list([1,2,3])
p = Process(target=func,args=(num,))
p.start()
p.join()
print("父进程中的num的值是:",num) =====> [0,2,3]
11.进程池
1.进程池的理论
(1)在实际业务中,任务量是有多有少的,如果任务量特别多,不可能要开对应那么多的进程数,开启那么多进程就需要消耗大量的时间让操作系统来为你管理它,其次还需要消化大量时间让CPU帮你去调度它
(2)进程池还会帮程序员去管理池中的进程
from multiprocessing import Pool
p = Pool(os.cpu_count + 1) =====>一般为5
(3)进程池:一个池子,里面有固定数量的进程,这些进城一直处于待命的状态,一旦任务过来,马上就有进程去处理
2.进程池的三个方法
(1)map(function,iterable)
function:进程池中的进程执行的任务函数
iterable:可迭代对象,是把可迭代对象中的每一个元素依次传给任务函数的参数
例如:
from multiprocessing import Pool
import os
def func(num):
num += 1
return num
if __name__ == '__main__':
p = Pool(os.cpu_count() + 1)
res = p.map(func,[i for i in range(100)])
p.close()
p.join()
print("主进程中的map的返回值:",res)
(2)apply(function,args=(,)) 同步的效率,池中进程一个一个去执行任务
function:进程池中的进程执行的任务函数 (主进程需要等待其执行结束)
args:可迭代对象型的参数,是传给任务函数的参数
同步处理任务的时候,不需要close和join (进程池中的所有进程是普通进程)
例如:
from multiprocessing import Pool
import os,time
def func(num):
num += 1
return num
if __name__ == '__main__':
p = Pool(os.cpu_count() + 1) #进程池设置固定的数量为5
start = time.time() #计算开启任务之前的时间
for i in range(100): #开启一百个进程
res = p.apply(func,args=(i,))
print(res)
print(time.time() - start) #计算同步效率的时间
(3)apply_async(function,args(,),callback = None) 异步的效率,也就是说池中的进程一次性都去执行任务
function:进程池中的进程执行的任务函数
args:可迭代对象型的参数,是传给任务函数的参数
callback:回调函数,也就是说每当进程池中有进程处理完任务了,返回的结果可以交给回调函数,由回调函数进行进一步处理 (只有异步有,同步没有)
异步处理任务时,进程池中的所有进程是守护进程(主进程代码执行完毕守护进程就结束)
异步处理任务的时候,必须要加上close和join (等待进程池中所有进程执行完毕任务)
例如:
from multiprocessing import Pool
import os,time
def func():
pass
if __name__ == '__main__':
p = Pool(os.cpu_count() + 1)
start = time.time()
l = []
for i in range(1000):
res = p.apply_async(func,args=(i,)) #异步处理这1000个任务,指进程中有5个进程就一下子处理这五个任务,接下来哪个进程处理完任务了,就马上去接收下一个任务
l.append(res)
p.close()
p.join()
print(time.time() - start)
回调函数的使用
进程的任务函数的返回值,被当成回调函数的形参接收到,依次进行进一步的处理操作
回调函数室友主进程调用的,而不是子进程,子进程只复责把结果传递给回调函数
例如:
from multiprocessing import Pool
import requests
import time,os
def func(url):
res = requests.get(url)
print("子进程的pid:%s,父进程的pid:%s" % (os.getpid(),os.getppid()))
if res.status_code == 200:
return url,res.text
def call_back(sta):
url,text = sta
print("回调函数的pid:%s" % os.getpid())
with open("a.text","a",encoding="utf-8")as f:
f.write(url+text)
if __name__ == '__main__':
p = Pool(os.cpu_count() + 1)
l = ["https://www.baidu.com",
"http://www.jd.com",
"http://taobao.com",
"http://www.cnblogs.com",
"https://www.bilibili.com"
]
print("主进程的pid:",os.getpid())
start = time.time()
for i in l:
p.apply_async(func,args=(i,),callback = call_back) #异步处理
p.close() #不允许再向进程池中添加任务
p.join() #等待进程中所有进程执行完所有任务
print(time.time() - start)

