

模块
一.在python中使用正则表达式
1.转义符
(1)在python中的转义符
print(r"C\\next") 在python中r是取消所有转义
(2)在正则表达式中的转义符
"\(" 表示匹配小括号 转义 (还是当括号来使用
[() + * ? / $ . ] 在字符组中这些字符会现出原形 还是当他们本身来使用
所有的\w,\d,\s(\t,\n),\W,\D,\S 都是表示它原本的意义
[-]只有写在字符组的首位的时候表示普通的减号
写在其他位置上表示范围:[1-9]
如果就是想要匹配减号:[1\-9]
二.re模块
1.字符串
(1)匹配
findall*****(正则表达式,参数) 返回值类型:列表形式 返回值的个数:1(一个列表) 返回值的内容:所有匹配上的项
例如:
import re
ret = re.findall("\d+","342dssf234")
print(ret) ====>['342', '234']
例如:没有匹配上
import re
ret = re.findall("\s+","342dssf234")
print(ret) =====>[]
search*****(正则表达式,参数) 返回值类型:正则表达式匹配给的对象,需要通过group来获取匹配到的第一个结果,类型是字符串 返回值的个数为:1 返回值的内容:为第一个匹配到的值
例如:
import re
ret = re.search("\d+","223dsf33")
print(ret.group()) ====>223
例如:没有匹配结果返回None
import re
ret = re.search("\s+","223dsf33")
print(ret) =====>None
match(正则表达式,参数) 和search基本相同
区别:
例如:
import re
ret = re.match("\d+","$232sdfd")
print(ret.group()) ====>会直接报错
import re
ret = re.search("\d+","$^223dsf33")
print(ret.group()) ====>223 不会报错,不会受到影响
(2)替换
sub(正则表达式,要替换的内容,参数)
例如:
import re
ret = re.sub("\d+","A","12sfd232sfsf23")
print(ret) ====>AsfdAsfsfA
例如:替换的次数
import re
ret = re.sub("\d+","A","12sfd232sfsf23",2)
print(ret) ====>AsfdAsfsf23
subn(正则表达式,替换的内容,参数) 打印出来的数据类型是个元组 第二位是替换的次数
例如:
import re
ret = re.subn("\d+","A","12sfd232sfsf23")
print(ret) ====>('AsfdAsfsfA', 3)
(3)切割
split(正则表达式,参数) 打印出来的数据类型是列表 是以正则表达式进行切割
例如:
import re
ret = re.split("\d+","alex23egon34taibai40")
print(ret) =====>['alex', 'egon', 'taibai', '']
(4)进阶方法 ----(主要用于爬虫和自动化开发)
compile (是将正则表达式编译成为一个正则表达式的对象) 首先将正则表达式转义,转义成python解释器可以理解的代码,然后再执行代码
(提高时间效率)
例如:
import re
ret = re.compile("-0\.\d+|-[1-9]+(\.\d+)?")
res = ret.search("alex-23sdlds-56sdfsg23")
print(res.group()) =====>-23
(只有在多次使用某一个相同的正则表达式的时候,这个compile才会帮助我们提高程序的效率)
finditer(finditer返回的是一个存放匹配结果的迭代器)
(提高空间效率)`
例如:
import re
ret = re.finditer("\d+","ds3sy4784a235")
print(ret) =====> <callable_iterator object at 0x00000218E531FB38>
print(next(ret).group()) ====> 3 查看第一个结果
print(next(ret).group()) ====> 4784 查看第二个结果
print([i.group() for i in ret]) ===> ['235'] 查看剩余的结果
例如: 拿到全部的在值
import re
ret = re.finditer("\d+","ds3sy4784a235")
for i in ret:
print(i.group()) ====>循环遍历 3 4784 235
2.优先级查询
(1)findall的优先级查询 (?:正则表达式)取消分组优先
例如:
import re
ret = re.findall("www.baodu.com|www.oldboy.com","www.oldboy.com")
print(ret) =====>['www.oldboy.com']
例如:
import re
ret = re.findall("www.(?:baidu|oldboy).com","www.oldboy.com")
print(ret) =====>['www.oldboy.com']
例如:
import re
ret = re.findall("www.(baidu|oldboy).com","www.oldboy.com")
print(ret) ====>['oldboy'] 在这里因为findall会优先匹配结果组里的内容返回,如果想要匹配结果,取消权限就可以在括号里面前面添加?:
(2)split的优先级查询 (遇到分组,会保留分组内被切割掉的内容)
例如:
import re
ret = re.split("(\d+)","alex24egon34taibai40")
print(ret) =====>['alex', '24', 'egon', '34', 'taibai', '40', '']
(3)search (如果search中有分组的话,通过group(n)能够拿到group中的匹配内容)
例如:
import re
ret = re.search("\d+(.\d+)(.\d+)(.\d+)?","1.2.3.4-2")
print(ret.group(3)) =====>.4
print(ret.group(2)) =====>.3
print(ret.group()) =====>1.2.3.4
分组的例子
1.只取参数中的整数
import re
ret = re.findall("\d+(?:\.\d+)|(\d+)","1-2*(60+(-40.35/5)-(-4*3)")
print(ret) =====>['1', '2', '60', '', '5', '4', '3']
ret.remove("")
print(ret) =====>['1', '2', '60', '5', '4', '3']
2.分别取出<a>wahaha</a> 中的 a wahaha /a
import re
ret = re.search(r"<\w+>(\w+)<(/\w+)>",r"<a>wahaha</a>")
print(ret.group()) =====> <a>wahaha</a>
print(ret.group(1)) =====> wahaha
print(ret.group(2)) =====> /a
3.分组命名
(1)?P<name> 分组命名的语法 name为组名
import re
ret = re.search("<(?P<name>\w+)>\w+</(?P=name)>","<h1>qqxing</h1>")
print(ret.group()) =====> <h1>qqxing</h1>
print(ret.group("name")) =====> h1 可以在group里面填写组名,找到该组名对应的值
(2)如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组的内容一致
import re
ret = re.search(r"<(\w+)>\w+</\1>","<a>wahaha</a>")
print(ret.group()) =====> <a>wahaha</a>
import re
ret = re.search(r"<(\w+)>(\w+)</\2>","<a>wahaha</wahaha>")
print(ret.group()) ======> <a>wahaha</wahaha>
(3)分组命名
分组命名
(?P<name>正则表达式) 表示给分组起名字
(?P=name) 表示使用这个分组,这里匹配到的内容应该和分组中的内容完全相同
通过索引使用分组
\1表示使用第一组,匹配到的内容必须和第一个组中的内容完全相同
三.random模块 (随机:在某个范围内取到每一个值的概率是相同的)
import random
1.随机小数
(1)0-1之间的随机小数
print(random.random(1))
(2)任意之间的随机小数
print(random.uniform(1,5)) (1,5之间的随机小数)
无限循环小数 包含在float里
2.随机整数
(1)[1,2]包含2在内的范围的随机整数
print(random.randint(1,2))
(2)[1,2)不包含2在内的范围的随机整数
print(random.randrange(1,2))
(3)[1,10)不包含10在内的范围内的随机奇数
print(random.randrange(1,10,2))
3.随机抽取
(1)随机抽取一个值
lst = [1,2,3,"aaa",("wahaha","qqxing")]
ret = random.choice(lst)
print(ret)
(2)随机抽取多个值
lst = [1,2,3,"aaa",("wahaha","qqxing")]
ret = random.sampe(lst)
print(ret)
4.打乱顺序 (在原列表中的基础上做乱序) 只能排列表
lst = [1,2,3,"aaa",("wahaha","qqxing")]
random.shuffle(lst)
print(lst)
四.时间模块 time
1.时间戳时间 (格林威治时间,float数据类型) 是给机器看的时间
1970.1.1 0:0:0 (英国伦敦的时间)
1970.1.1 8:0:0 (北京时间)
import time
print(time.time()) =====> 1533714658.3928015
2.结构化时间 (时间对象:能够通过.属性名来获取对象中的值) 从给机器看的 ------>给人看的过程
时间元祖:
import time
time_obj = time.localtime() 对象数据结构
print(time_obj) =====>time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=15, tm_min=48, tm_sec=9, tm_wday=2, tm_yday=220, tm_isdst=0)
print(time_obj.tm_year) =====>2018
3.格式化时间 (可以根据你的需要的格式来显示时间) 给人看的时间
时间字符串:
import time
print(time.strftime("%Y-%m-%d %H:%M:%S")) =====>2018-08-08 15:52:49
print(time.strftime("%Y/%m/%d %H-%M-%S")) =====>2018/08/08 15-53-52
4.三种格式之间的转换
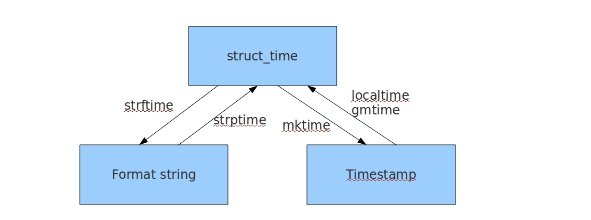
(1)由时间戳时间 ----->格式化时间
import time
time_obj = time.localtime(1500000000) ======> (时间戳时间(time.time()))
ret = time.strftime("%Y-%m-%d",time_obj) ======> ("格式定义","结构化时间")
print(ret) =====> 2017-07-14
(2)格式化时间 ------>时间戳时间
import time
ret = time.strptime("2018-08-08","%Y-%m-%d") =======>("时间字符串","该时间对应的格式")
time_obj = time.mktime(ret)
print(time_obj) =====> 1533657600.0
练习题: 求本月一号的时间戳时间
(1)方法一:
import time
ret = time.localtime()
ret = time.strptime("%s-%s-1" % (ret.tm_year,ret.tm_mon),"%Y-%m-%d")
a = time.mktime(ret)
print(a)
(2)方法二
import time
ret = time.strftime("%Y-%m-1")
a = time.strptime(ret,"%Y-%m-%d")
b = time.mktime(a)
print(b)
五.sys模块
sys模块是与python解释器交互的一个接口
1.sys.path
返回模块的搜索路径,初始化使用python.path环境变量的值
2.sys.modules
表示所有在当前python程序中导入的模块的内存地址
3.sys.platform
返回操作系统平台的名称 win32/win64 但是在pycharm中不准确
4.sys.exit()
退出程序 正常退出是sys.exit(1) 错误退出是sys.exit(0)
5.sys.argv
(1)打印出来的是列表数据类型
(2)第一个元素是执行这个文件的相对路径,也就是写在python命令后面的第一个值
(3)python命令后面的值都可以打印出来,之后的元素,在执行python启动的时候可以写多个值,都会依次添加到列表中
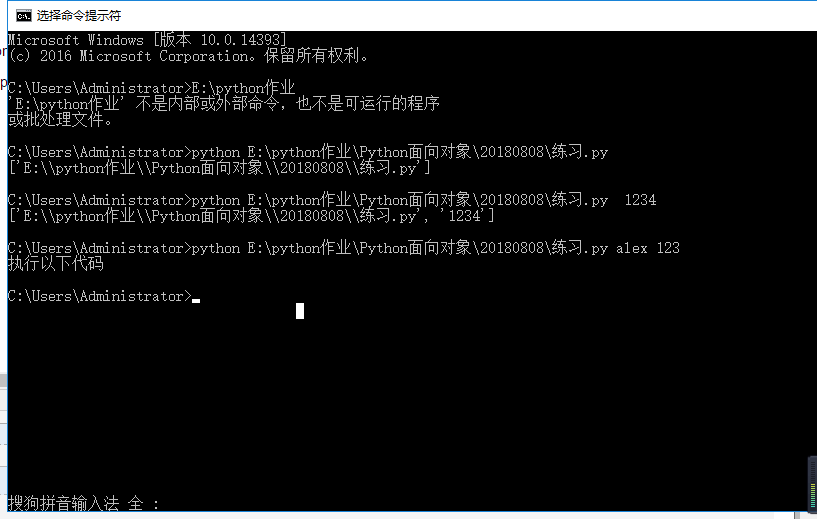
有什么用?怎么用? (在cmd练习中操作)
import sys
name = sys.argv[1]
psw = sys.argv[2]
if name == "alex" and psw == "123":
print("执行以下代码")
else:
exit()
六.os模块
os模块是与操作系统交互的一个接口
(1)os.getcwd()
在哪个地方执行了这个文件,getcwd的结果就是执行的那个文件所在文件夹的绝对路径
import os
print(os.getcwd())

(2)os.chdir()
import os
print(os.getcwd())
os.chdir(r"E:\python作业\Python面向对象")
print(os.getcwd())

(3)os.mkdir("文件夹名字") 创建一个文件夹
import os
os.mkdir('dir1')

import os
os.mkdir('dir1/dir2') (如果dir1存在,就会在dir1下面在创建一个dir2,并不会报错,这也相当于创建一个文件夹)

(4)os.makedir("dir2/dir3/dir4") 创建多层递归目录
import os
os.makedirs("dir2/dir3/dir4")

如果已经存在文件,也不会报错,如果没有,就新建
import os
os.makedirs("dir2/dir3/dir4",exist_ok=True)
os.makedirs("dir2/dir3/dir5",exist_ok=True)

(5)os.rmdir("dir2/dir3/dir4") 删除一个文件夹(但是不能删除非空文件夹)
import os
os.rmdir("dir2/dir3/dir4") ===.dir4 被删除了

import os
os.remove("dir2/dir3/dir5/aa")
os.rmdir("dir2/dir3/dir5")
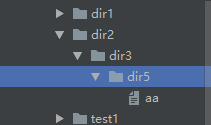

(6)os.removedirs("dir2/dir3/dir4")
递归向上删除文件,只要删除当前目录之后,发现上一级目录也为空,就把上一级目录删除,如果上一层目录里有其它文件,就停止删除
import os
os.removedirs("dir2/dir3/dir4")
(7)os.remove("文件绝对路径") 删除文件
import os
os.remove("dir1/dir2/aaa")
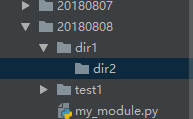
(8)os.rename("旧名字","新名字") 重命名
import os
os.rename("dir1/aaa","dir1/bbb")
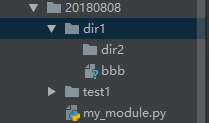
(9)os.listdir("路径") 可以查看该路径下的全部文件夹
import os
print(os.listdir(r"E:\python作业"))
(10)os.stat("路径") 查看文件的状态
import os
print(os.stat(r"E:\python作业\Python面向对象\20180808\dir1\bbb"))

(11)os.sep("路径") 当前你所在的操作系统的目录的分隔符
import os
print(os.sep)
win 下为"\\" Linux下为"\"
(12)os.linesep() 输入当前平台使用的行终止符
import os
print([os.linesep])
win下为["\r\n"] Linux下为["\n"]
(13)os.pathsep 输出用于分割文件路径的字符串
import os
print(os.pathsep)
win下为";" Linux下为":"
(14)os.name 输出字符串指示当前使用平台
import os
print(os.name)
win下为"nt" Linux下为"posix"
(15)os.system("命令") 用于删除文件/copy一个文件的时候使用(不关心结果) 用于自动化开发
import os
print(os.system("ipconfig"))
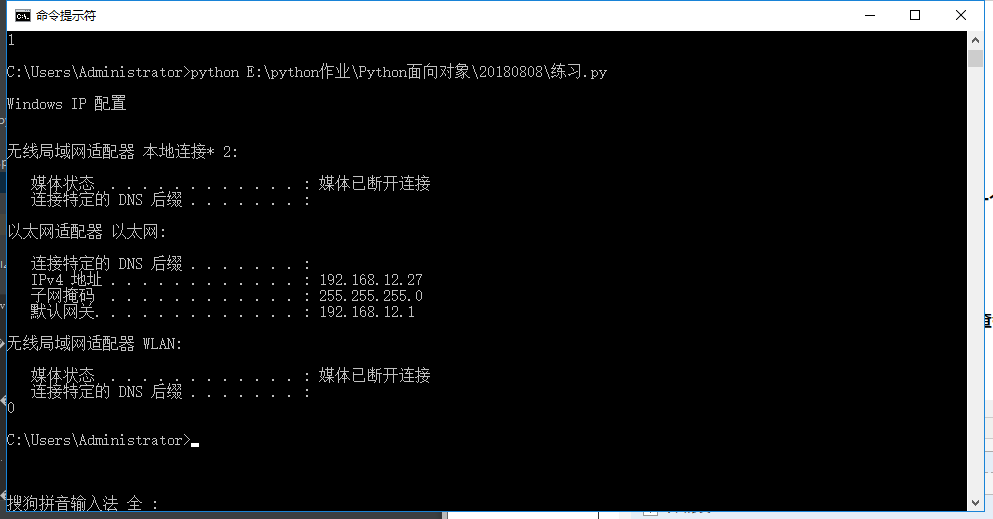
(16)os.popen("文件名") 用于查看当前路径,查看某些信息的时候使用 用于自动化开发
import os
ret = os.popen("ipconfig")
print(ret.read())

(17)os.environ 能够打开操作系统/python系统环境变量
import os
print(os.environ)
os.path
(18)os.path.abspath("路径") 返回规范过的绝对路径
import os
ret = os.path.abspath(r"E:\python作业\Python面向对象\\\20180808\练习.py")
print(ret)
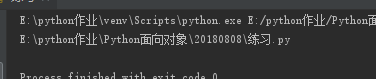
(19)os.path.split("路径") 将路径切割成目录和文件名的元组
import os
ret = os.path.split(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)

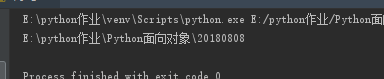
(20)os.path.dirname("路径") 返回的是os.path.split("路径")切割后的第一个元素
import os
ret = os.path.dirname(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)
(21)os.path.basename("路径") 返回的是路径最后的文件名,如果路径是以"\"或者"/"结尾的,返回的结果就会为空
import os
ret = os.path.basename(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)

import os
ret = os.path.basename(r"E:\python作业\Python面向对象\20180808/")
print(ret)

(22)os.path.exists("路径") 查看该路径是否存在,如果该路径存在返回True 如果不存在就返回False
import os
ret = os.path.exists(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)

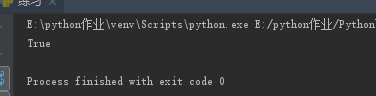
(23)os.path.isabs("路径") 如果是绝对路径,返回True
import os
ret = os.path.isabs(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)
绝对路径:(E:\python作业\Python面向对象\20180808\练习.py)
相对路径:(练习.py)
(24)os.path.isfile("路径") 如果路径是一个存在的文件,就返回True,否则返回False
import os
ret = os.path.isfile(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)
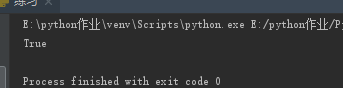
(25)os.path.isdir("路径") 如果路径是一个存在文件夹或者目录,就返回True,否则返回False
import os
ret = os.path.isdir(r"E:\python作业\Python面向对象\20180808")
print(ret)

(26)os.path.join(path1[,path2[,......]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
(27)os.path.getatime("路径") 返回路径指向的文件/目录/文件夹最后访问的时间
import os
ret = os.path.getatime(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret) =====>打印出来的是时间戳时间的flost的数据类型
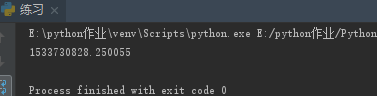
(28)os.path.getmtime("路径") 返回路径指向的文件/目录/文件夹最后修改的时间
import os
ret = os.path.getmtime(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)
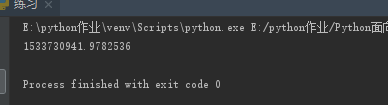
(29)os.path.getsize("路径") 返回文件/文件夹/目录的大小 (文件夹/目录的大小始终是4096)
import os
ret = os.path.getsize(r"E:\python作业\Python面向对象\20180808\练习.py")
print(ret)
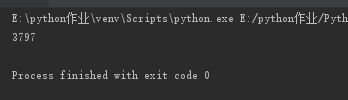
七.序列化模块
序列化:将原本的字典,列表等内容换成一个字符串的过程就叫序列化
1.序列化的目的:
(1)以某种存储形式使自定义对象持久化
(2)将对象从一个地方传递到另一个地方
(3)使程序更具维护性
2.为什么要序列化?
(1)要把内容写进文件
(2)网络传输数据

3.模块
(1) json模块 *****
① json的功能:
dumps 功能 可以处理嵌套型的数据类型
import json
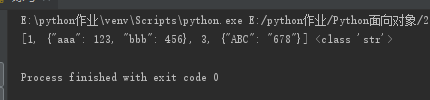
l = [1,{"aaa":123,"bbb":456},3,{"ABC":"678"}]
str_l = json.dumps(l)
print(str_l,type(str_l))
loads 功能 反序列化:将一个字符串格式的数据类型换成他原本的类型
import json
l = [1,{"aaa":123,"bbb":456},3,{"ABC":"678"}]
str_l = json.dumps(l)
ll = json.loads(str_l)
print(ll)

dump 功能 接收一个文件句柄,直接将字典转换成json字符串写入文件
mport json
f = open("json_file",mode="w",encoding="utf-8")
dic = {"aaa":123,"bbb":456}
json.dump(dic,f)
f.close

load 功能 load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
mport json
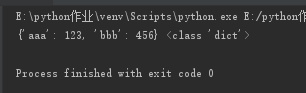
f = open("json_file")
dic1 = json.load(f)
f.close()
print(dic1,type(dic1))
② json模块的补充
json模块格式的key必须是字符串数据类型
json格式中的字符串只能是" "
set集合不能dump/dumps
如果是数字key,那么dumps之后会强行转换成字符串数据类型
import json
dic = {123:456,678:234}
str_dic = json.dumps(dic)
print(str_dic) ======> {"123": 456, "678": 234}
new_dic = json.loads(str_dic)
print(new_dic) ======> {'123': 456, '678': 234}
json是否支持元组,当元组做value的字典会把 元组强制转换成列表
import json
dic = {"abc":(4,5,6)}
str_dic = json.dumps(dic)
print(str_dic) =======> {"abc": [4, 5, 6]}
new_dic = json.loads(str_dic)
print(new_dic) =======> {'abc': [4, 5, 6]}
json不支持元组做keyimport json
dic = {(1,2,3):"abd"}
str_dic = json.dumps(dic)
print(str_dic) =======> 直接报错
对列表dump (如果dump完之后,自己强行把文件中的" ",改成' ',则在load的时候就会报错)
import json
lst = ["aaa","bbb","ccc"]
with open("json_dump","w")as f:
json.dump(lst,f) ======> ["aaa", "bbb", "ccc"]
with open("json_dump")as f:
ret = json.load(f)
print(ret) ======> ['aaa', 'bbb', 'ccc']
json可以多次dump数据到文件里,但是不能load出来
import json
lst = ["aaa","bbb","ccc"]
dic = {"abc":(4,5,6)}
with open("json_dump","w")as f:
json.dump(lst,f)
json.dump(dic,f) =======>["aaa", "bbb", "ccc"]{"abc": [4, 5, 6]}
with open("json_dump")as f:
ret = json.load(f)
print(ret) =======> 直接报错
想dump多个数据的时候,就用dumps
import json
lst = ["aaa","bbb","ccc"]
dic = {"abc":(4,5,6)}
with open("json_dump","w")as f:
str_lst = json.dumps(lst)
str_dic = json.dumps(dic)
f.write(str_lst+"\n")
f.write(str_dic+"\n") =======>["aaa", "bbb", "ccc"]
{"abc": [4, 5, 6]}
with open("json_dump")as f:
for line in f:
ret = json.loads(line)
print(ret) =====>['aaa', 'bbb', 'ccc']
{'abc': [4, 5, 6]}
json也可以转中文格式的
import json
dic = {"abc":123,"country":"中国"}
str_dic = json.dumps(dic,ensure_ascii=False)
print(str_dic) ========>{"abc": 123, "country": "中国"}
new_dic = json.loads(str_dic)
print(new_dic) ========>{'abc': 123, 'country': '中国'}
文件中也可以转中文格式
import json
dic = {"abc":123,"country":"中国"}
with open("json_dump","w",encoding="utf-8")as f:
json.dump(dic,f,ensure_ascii=False) =====> {"abc": 123, "country": "中国"}
with open("json_dump","r",encoding="utf-8")as f:
ret = json.load(f)
print(ret) =====> {'abc': 123, 'country': '中国'}
json的其他参数,是为了用户看的更方便,但是会相对浪费存储空间
import json
data = {"username" : ["李华","二愣子"],"sex":"男","age":16}
json_dic = json.dumps(data,sort_keys=True,indent=4,separators=(",",":"),ensure_ascii=False)
print(json_dic)
=======>
{
"age":16,
"sex":"男",
"username":[
"李华",
"二愣子"
]
}
sort_keys = True :字典key的首字母按照英文排序
indent: 设置缩进
separators = (",") 按照 , 进行分割
(2) pickle模块 *****
pickle模块适合用于保存状态和对象
pickle模块dump/dumps的结果是bytes类型,dump用的f文件句柄的时候需要以"wb"的形式打开,load则用的是"rb"形式
pickle模块支持几乎所有对象的序列化
① pickle模块dump/dumps出来的结果是bytes类型
import pickle
dic = {1:(1,2,3),("a","b"):4}
pic_dic = pickle.dumps(dic)
print(pic_dic) ======> b'\x80\x03}q\x00(K\x01K\x01K\x02K\x03\x87q\x01X\x01\x00\x00\x00aq\x02X\x01\x00\x00\x00bq\x03\x86q\x04K\x04u.'
new_dic = pickle.loads(pic_dic)
print(new_dic) ======> {1: (1, 2, 3), ('a', 'b'): 4}
② pickle模块能够处理够复杂的数据类型,会原封不动的恢复到原来的状态
import pickle
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
alex = Student("alex",45)
ret = pickle.dumps(alex) 可以把类中的实例化自定义的对象也dumps
print(ret) ======> b'\x80\x03c__main__\nStudent\nq\x00)\x81q\x01}q\x02(X\x04\x00\x00\x00nameq\x03X\x04\x00\x00\x00alexq\x04X\x03\x00\x00\x00ageq\x05K-ub.'
小花 = pickle.loads(ret)
print(小花.name) ======> alex
print(小花.age) ======> 45
③ dump用文件句柄的时候需要用"wb"打开,load用文件句柄的时候需要以"rb"模式
import pickle
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
alex = Student("alex",45)
with open("pickle_dump","wb")as f:
pickle.dump(alex,f)
with open("pickle_dump","rb")as f:
ret = pickle.load(f)
print(ret.name,ret.age)
④ 对于多次dump/load的操作做了良好的处理
import pickle
with open("pickle_dump","wb")as f:
pickle.dump({"k1":"v1"},f)
pickle.dump({"123":"456"},f)
pickle.dump({"abc":"def"},f)
with open("pickle_dump","rb")as f:
while True:
try:
print(pickle.load(f))
except EOFError:
break
(3) shelve 模块
如果你写一定了一个文件(改动比较少),读文件操作比较多,且你大部分的读取都需要基于某个key获取某个value值
import shelve
f = shelve.open("shelve_demo")
f["key"] = {"k1":(1,2,3),"k2":"v2"}
f.close() =====>关闭文件
f = shelve.open("shelve_demo") ====>open打开文件就是在占用文件
content = f["key"]
f.close()
print(content) =====> {'k1': (1, 2, 3), 'k2': 'v2'}
八.hashlib模块 (摘要算法的模块)
import hashlib
1.hashlib模块的第一个用法是:登录的密文验证
hashlib模块能够把一个字符串类型的变量转换成一个定长的密文的字符串,字符串里的每一个字符都是十六进制的数字
它能够将字符串转换成密文,但是密文没有办法转回为字符串
算法:对于同一个字符串,用相同的算法,相同的手段去进行摘要,获得的值总是相同的
(1).md5算法 (32位的字符串,每一个字符都是一个十六进制)
例如:
import hashlib
s = "alex"
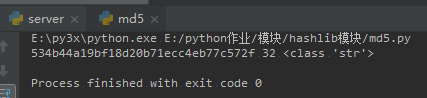
md5_obj = hashlib.md5() #先实例化一个对象
md5_obj.update(s.encode("utf-8")) #update里必须写的是bytes类型
res = md5_obj.hexdigest() #对字符串进行摘要加密
print(res,len(res),type(res))
md5 的优缺点:
(1)计算速度快,没有sha()算法复杂
(2)md5()普及
(3)算法相对简单
(4)md5由于使用的人太多,撞库的几率比较高,所以不够安全
(2).sha()算法 (40位的字符串,每一个字符都是十六进制)
例如:
import hashlib
s = "alex"
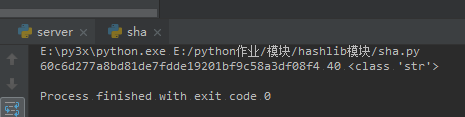
m = hashlib.sha1() #实例化一个sha对象
m.update(s.encode("utf-8"))
res = m.hexdigest()
print(res,len(res),type(res))
sha1的优缺点:
(1)算法相对复杂
(2)计算速度慢
(3)用的人少,所以安全性相对比较高
md5,sha1具有相同的特点:
对于同一个字符串,不管这个字符串有多长,只要是相同的,无论在任何环境下,多少次执行,在任何语言中,使用相同的算法/相同的手段得到的结果永远是相同的
只要不是相同的字符串得到的结果一定不同
(3).md5/sha1加盐
例如:
import hashlib
s = "alex"
md5_obj = hashlib.md5("wusir".encode("utf-8")) #在这个位置上加盐,可以加任意的字符串
md5_obj.update(s.encode("utf-8"))
res = md5_obj.hexdigest()
print(res)
(4).动态加盐
例如:
import hashlib
name = input("请输入名字:")
password = input("请输入密码:")
md5_obj = hashlib.md5(name.encode("utf-8"))
md5_obj.update(password.encode("utf-8"))
res = md5_obj.hexdigest()
print(res) #用户名密码最后的摘要结果
2.hashlib模块第二个用法:文件的一执行校验
例子1:
import hashlib
md5_obj = hashlib.md5() #实例化一个对象
with open("file.py","rb")as f:
md5_obj.update(f.read())
ret1 = md5_obj.hexdigest()
md5_obj = hashlib.md5()
with open("file1.py","rb")as f1:
md5_obj.update(f1.read())
ret2 = md5_obj.hexdigest()
print(ret1,ret2) #(如果两个文件里的内容一致,打印出来结果一样)
例子2:对于同一个字符串,update一个,update多个结果一样
(1)
import hashlib
md5_obj = hashlib.md5()
md5_obj.update("hello,world".encode("utf-8"))
print(md5_obj.hexdigest())
(2)
md5_obj = hashlib.md5()
md5_obj.update("hello,".encode("utf-8"))
md5_obj.update("world".encode("utf-8"))
print(md5_obj.hexdigest())
九.configparser模块
