达梦统计信息
https://www.cnblogs.com/wuran222/p/15633918.html
现象描述
请树立意识:
- 数据库在导入大量数据之后,请立即更新统计信息
- 数据库数据分布方式不太变动的时候,请不要更新他们的统计信息(可以维持计划稳定)
- 对于时间列,尤其是有具体参数的时间列(分布不均的方式),我们需要每天都及时更新这些列的统计信息
如果上述 2 和3 看不懂,没关系,请牢记第一点。而怎么收集统计信息,就是这篇文章会告诉你的。
现象描述
我们在使用达梦数据库的过程中,有时候碰到一个这样子的情况:
Create table manyrows_tables; Select * from manyrows_tables where col=xx; -- 查询很慢 Create index test_1 on manyrows_tables(col); Select * from manyrows_tables where col=xx; -- 查询还是很慢?
这个时候怎么办? —— 只需要收集下 col 那个列的统计信息即可
Stat 100 on manyrows_tables(col); Select * from manyrows_tables where col=xx; -- 查询很快了
处理方法
收集统计信息一共有三种方式:
- Sp 系统函数
- Stat 命令
- Dbms_stats 系统包
方法1 :
既然是函数,那么我们通过达梦提供的系统视图看看,一共有哪些相关函数:
Select * from v$ifun where name like '%SP%STAT%INIT';
有的人会问为什么这么查,其实,确实,不用记住,只要知道为什么这么查询就可以了
- V$ifun 是达梦提供的函数
- 通过名字 like 就可以找出来, sp 是 system procedure 的意思, stat 是统计信息的意思, init 是初始化的意思,而且很巧 like %init 也包含了 deinit 反初始化(清空统计信息),所以我们通过 where 条件, name like '%SP%STAT%INIT' 找出我们感兴趣的系统过程了
对于查询出来的其他函数,不做解释,大家可以有个印象就好了,我们要用到的就下面这几个:
-- 针对表自身的
SP_TAB_STAT_INIT
SP_TAB_STAT_DEINIT
-- 针对索引的
SP_INDEX_STAT_INIT
SP_INDEX_STAT_DEINIT
-- 针对全库的(慎用,库比较大的话,每个一时半会,别想跑完)
SP_DB_STAT_INIT
SP_DB_STAT_DEINIT
-- 针对列的
SP_COL_STAT_INIT
SP_COL_STAT_DEINIT
-- 针对sql 语句的
SP_SQL_STAT_INIT
下面分别是他们的一个例子:
基础数据:
drop table if exists test ; create table test ( v1 int , v2 int ); insert into test select level , level connect by level <=10000 ; commit ; create index idx_test_v1 on test ( v1 ); -- 注意索引的命名规范
执行例子:
-- 针对表自身的
SP_TAB_STAT_INIT ( 'SYSDBA' , 'TEST' ); SP_TAB_STAT_DEINIT ( 'SYSDBA' , 'TEST' );
-- 针对索引的
SP_INDEX_STAT_INIT ( 'SYSDBA' , 'IDX_TEST_V1' ); SP_INDEX_STAT_DEINIT ( 'SYSDBA' , 'IDX_TEST_V1' );
-- 针对全库的(慎用,库比较大的话,每个一时半会,别想跑完)
SP_DB_STAT_INIT (); SP_DB_STAT_DEINIT ();
-- 针对列的
SP_COL_STAT_INIT ( 'SYSDBA' , 'TEST' , 'V2' ); SP_COL_STAT_DEINIT ( 'SYSDBA' , 'TEST' , 'V2' );
-- 针对 sql 语句的
SP_SQL_STAT_INIT ( 'select * from test a ,test b where a.v1=b.v2' );
方法2 :
Stat 命令,主要是我们用在表的列上,比较方便:
Stat 100 on test(v1);

当然,stat 100 on sysdba.test(v1); 也是对的。( 就是这么通过指定用户名——有的时候我们叫做模式名 )
方法3 :
这里只讲两个方法,其他可以参考:达梦安装目录的/doc/special 目录下的 System_Packages.pdf 手册(系统包),中间 第21章 DBMS_STATS 包 的详尽介绍
收集某用户下的所有索引:
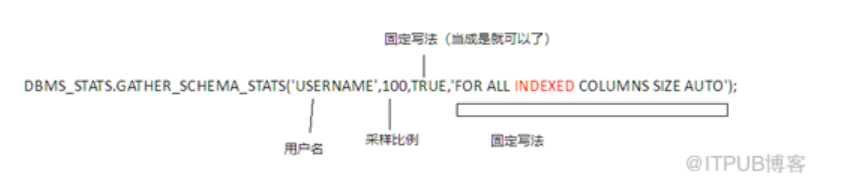
注意字符串参数里面的空白符,请 一定手敲整个字符串,不要从网页上复制,不要从网页上复制,不要从网页上复制,不要搞些全角空格进去,那样子在,可能你的这个命令(当成 sql 语句执行),执行的非常快,但是没用,没有收集统计信息。
某用户下所有字段(包括索引):
DBMS_STATS.GATHER_SCHEMA_STATS('USERNAME',100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
某表下的所有字段:
DBMS_STATS.GATHER_TABLE_STATS('USERNAME','TABLENAME',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');

几种方式的DBA 意识层面的比对
|
方法1 |
可以对表自身收集 可以对sql 语句涉及到的对象收集,—— 当sql 很复杂的时候,很舒服! 但是,他使用的自适应的采样比例,不可以控制。——系统内嵌的算法,数据量在什么级别的时候,用多大的采样比例,不可以指定。 |
|
方法2 |
对于收集列的统计信息的时候,最常用的一个方法。尤其是在刚建立完索引的时候。 直接 在索引的语句 on 前面 加个 stat 100 选中后面部分执行就可以,很方便。—— 懒人。。。 可以指定列收集,既是它的优点,也是他的缺点。 |
|
方法3 |
用的也很多,可以对整个表的索引列,指定采样比例收集,或者对整个表的全部列,指定采样比例收集。 一个命令,对全表涉及列收集,是它的优点,也是它的缺点,因为有时候,我们不需要收集某些列嘛,表大的时候,收集很浪费时间的。 当然,可以指定采样比例收集整个模式,也是它的优点,但是不建议,只因为他中断了怎么办,再次执行又是从头再来。 |
总之,如果我们碰到说要收集统计信息,就随便用前面哪种方式收集一下就好了,如果可行的话,就选择采用率为100 的方式收集。
更多资讯请上达梦技术社区了解: https://eco.dameng.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号