
Danswer 快速指南:不到15分钟打造您的企业级开源知识问答系统

一、写在前面
至于为什么需要做企业知识库,知识问答检索系统,以及现有GPT模型在企业应用中存在哪些劣势,今天在这里就不再赘述了,前面介绍其他构建知识库案例的文章中基本上都有讲过,如果您有兴趣可以去翻翻历史文章来了解。
今天就直接进入主题,介绍一款还不错的开源项目 Danswer,相较于其他开源的产品来说,从 Danswer 的设计上来来看确实存在一定的优势和可以参考的地方,其中最值得一提的还属 Connectors 连接器。目前官方已经提供了 12 中内置的连接器,连接器可以很方便的将任何你需要加入知识检索和问答的文档资料添加到向量数据库中进行索引。
二、Danswer 基本介绍
Danswer 允许您针对内部文档提出自然语言问题,并获得由源材料中的引用和参考文献支持的可靠答案,以便您始终可以信任您得到的结果。您可以连接到许多常用工具,例如 Slack、GitHub、Confluence 等。
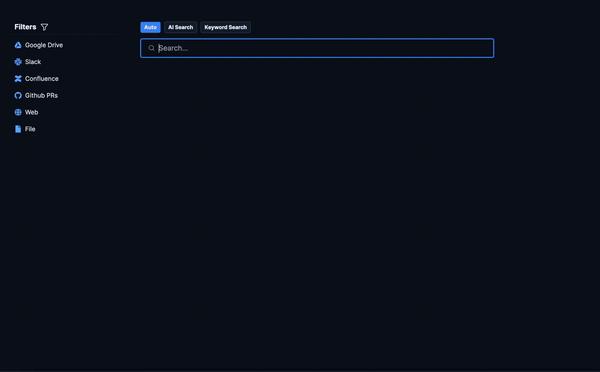
2.1、Danswer 有哪些优势 ?
- 它是完全开源的(MIT 许可证)并且免费使用,完全可以本地部署,数据隐私安全。
- 允许您即插即用不同的 LLM 模型,例如 GPT、HuggingFace、GPT4All、Llama cpp,甚至自定义自托管模型。
- 具有开箱即用的关键功能,如文档访问控制、前端 UI、管理仪表板、轮询文档更新和灵活的部署选项。
- 与 Slack、GitHub、GoogleDrive 等12种其他工具的连接器的不错列表。
- 直接提问,无需打开任何文档即可解答您的问题,由GPT-4(或您选择的自托管模型)提供支持的答案,每个答案均附有引文和参考资料,因此您始终可以相信您得到的答复。
- Danswer 使用最新的大语言模型来查找最相关的文档。
- 自定义深度学习模型根据用户意图优化搜索。智能文本分块甚至可以防止细则丢失。
默认设置下,Danswer 使用 OpenAI 的 GPT 系列模型,你也可以根据需要在Danswer中使用开源模型,比如最近很火的Llama 2模型。
三、Danswer 实现原理
Danswer 是开源 NLP 和生成人工智能的最新技术的结合,Danswer 在执行用户查询请求到反馈结果的流程和原理如下:
1)、当用户提交查询时,首先通过用户意图模型进行处理,该模型确定是使用关键字搜索还是语义搜索。该模型是使用DistilBert检查点微调而成,使用由GPT提示生成的数据集,并手动过滤掉不良示例。
2)、语义搜索流程分为两个步骤:检索和重新排序。
- 检索是通过使用双编码器模型对文本进行嵌入来完成的。向量存储在Qdrant向量数据库中,然后在查询时通过以相同方式投影用户查询来获取。在进行检索时会执行一些操作包括:上下文感知分块文档,包括跨块的重叠,并在不同尺度上多次嵌入块。一次使用512个标记进行更大的上下文,然后使用128个标记进行更精细的细节。
- 对于重新排序,使用了一组不同的模型作为集合。通过组合在不同数据集上表现更好的多个模型,可以获得最佳的重新排序结果,甚至可以使用较小的模型,从而使步骤整体更快。
3)、最后,最相关的文档部分被传递给生成模型,该模型被提示也提供其答案的引用。然后将引用与源文档匹配,并将其与答案一起呈现给用户。
四、Danswer 快速部署
Danswer 提供了 Docker 容器,可以轻松部署在任何云上,无论是在单个实例上还是通过 Kubernetes。在本演示中,我们将使用 Docker Compose 在本地运行 Danswer。
- 首先拉取代码:
git clone https://github.com/danswer-ai/danswer.git- 接下来导航到部署目录:
cd danswer/deployment/docker_compose- [可选] 默认的 Danswer 模型是 GPT-3.5-Turbo,因此如果您想使用它,则无需进行任何更改。
如果想使用开源的如Llama 2 模型API,可以通过创建 .env 文件来覆盖一些默认值,将 Danswer 配置为使用新的 Llama 2 端点:
INTERNAL_MODEL_VERSION=request-completion # 将Danswer设置为使用requests而不是客户端库与LLM进行接口交互
GEN_AI_HOST_TYPE=colab-demo # 将请求的头/主体设置为模型端点所期望的格式
GEN_AI_ENDPOINT=<REPLACE-WITH-YOUR-NGROK-PUBLIC-URL>/generate # 设置模型端点URL- 启动Danswer(使用docker版本≥= 1.13.0):
docker compose -f docker-compose.dev.yml -p danswer-stack up -d --pull always --force-recreate- 完成后,Danswer 将在http://localhost:3000上可用访问。
有关 Danswer 的更多文档,请访问https://docs.danswer.dev/quickstart
五、Danswer 应用实践
5.1、添加文档到 Danswer
Danswer 提供了12种 Connectors 连接器用于将 Danswer 连接到你的数据源,以便答案基于你组织的知识来回答,如果目前内置的所有连接器不满足你的要求,也可以给官方提需求,或者自己基于开源代码来实现。将不同的数据源连接到 Danswer 是通过管理页面完成的,在右上角点击[Admin Panel]菜单即可进行设置。
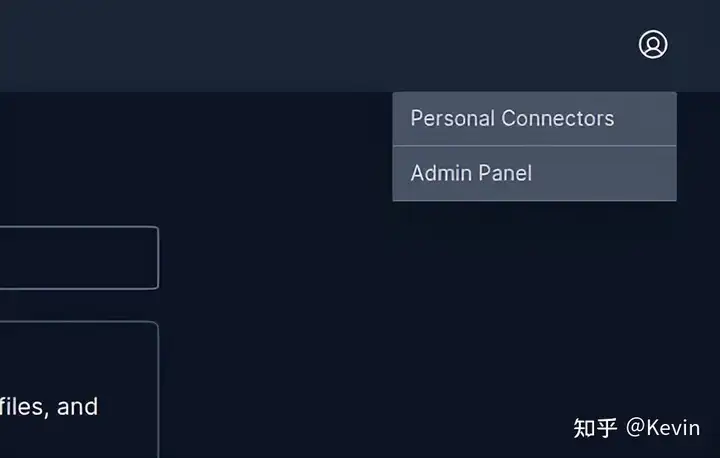
关于每个 Connectors 连接器具体的配置使用可以在官网文档中找到详细的介绍。
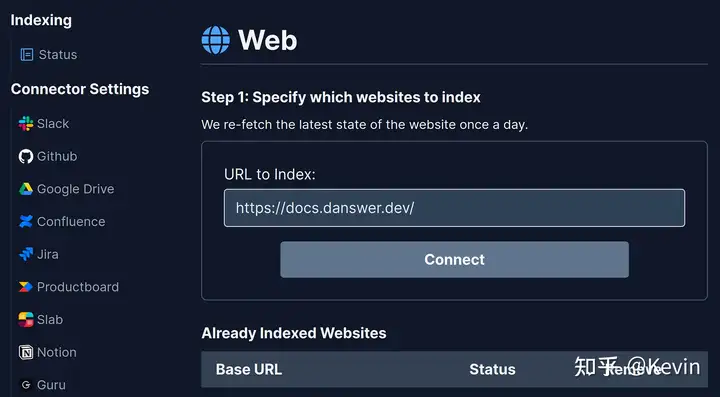
这里我们添加一个Web连接器数据源来演示,只需要将一个公开可访问的网址URL加入到Web连接器即可,Danswer会爬去该文档的内容来存储到向量数据库中。
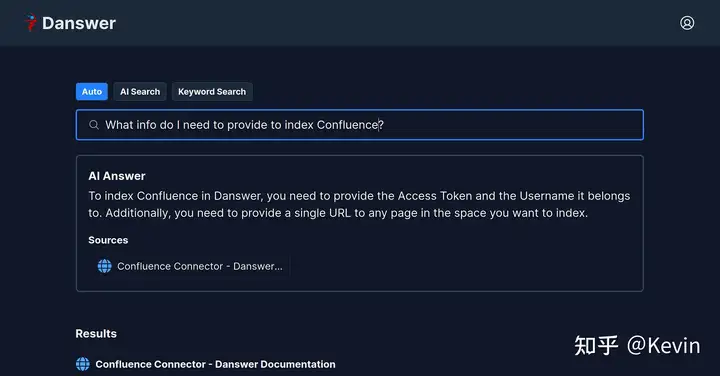
5.2、从 Danswer 获取答案
添加完数据源之后,我们就可以单击 Danswer 图标返回主页,现在就可以直接输入你文档相关的问题来索引了。
六、结束语
Danswer 是一款优秀的开源企业知识问答系统,通过使用连接器,可以方便地将各种文档资料添加到向量数据库中进行索引。它允许用户针对内部文档提出自然语言问题,并获得可靠、有参考价值的答案。Danswer 的优势包括完全开源、免费使用、数据隐私安全以及支持即插即用不同的 LLM 模型。它还可以与许多常用工具(如 Slack、GitHub、Confluence 等)无缝连接,为企业提供高效且可靠的知识检索和问答解决方案。
七、References
- Danswer GitHub:https://github.com/danswer-ai/danswer
- Danswer Docs:https://docs.danswer.dev/connectors/overview
- Dnaswer Connectors:https://github.com/danswer-ai/d


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· DeepSeek “源神”启动!「GitHub 热点速览」
· 上周热点回顾(2.17-2.23)