
新技术
大模型分词技术:
BPE(Byte Pair Encoding):
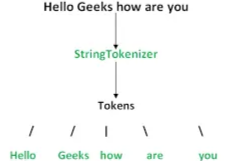
- 执行分析的算法/模型:Tokenizer
- 分出来的最小粒度的组成部分:Token
- 分词的目标:尽可能使token蕴含更多有用的信息(1、上下文信息 2、shiyong更高频、丰富的字词作为token)
- 整个过程称为 Tokenization
古典分词方法:
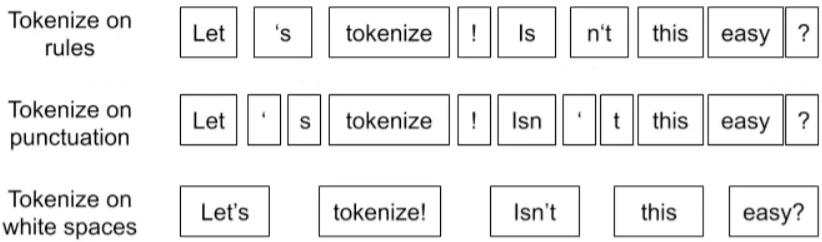
古典分词缺点:
对于未在词表中出现的词(Out Of Vocabulary, OOV ),模型将无法处理(未知符号标记为 [UNK])。
词表中的低频词/稀疏词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率)。(前两点BPE用UNK 解决)
⭐️ 很多语言难以用空格进行分词,例如英语单词的多形态,"look"衍生出的"looks", "looking", "looked",其实都是一个意思,但是在词表中却被当作不同的词处理,模型也无法通过 old, older, oldest 之间的关系学到 smart, smarter, smartest 之间的关系。这一方面增加了训练冗余,另一方面也造成了大词汇量问题。(有冗余浪费,重复部分不用浪费信息,进行编码)
BPE(BPE, Byte Pair Encoding)分词:又称 digram coding 双字母组合编码,适用于字符形式语言(中文还是分字、词(多一点,语义信息更多))
核心思想:不再使用全词方案,使用subword方案(基于子词的分词方法(Subword Tokenization))
Subword 算法主要含3种:Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model
流程:BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。
优点:可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的 token 数量)。
注意:随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值。
BBPE
Byte-level BPE,它是一种基于字节级别的BPE分词器
参考:
https://juejin.cn/post/7088322473640329230
https://juejin.cn/post/7431760347710128179
https://mp.weixin.qq.com/s/lsCshrnmtO-bYaszLFBSNw
https://mp.weixin.qq.com/s/aELfLx6QTlNzsyKnuEqW7A
https://mp.weixin.qq.com/s/zP4YMP2Pn3niTG1YEXF9GA
https://mp.weixin.qq.com/s/dfHQ3Z6ym6pblVWTtuN7SA
旋转位置编码:https://mp.weixin.qq.com/s/BKFZcEaSjrE4t2fnMPbPNQ
nltk(Natural Language Toolkit)是一个用于自然语言处理(NLP)的Python库,提供了丰富的工具和资源,用于文本处理、语言分析、词性标注、分词、命名实体识别等任务。以下是NLTK的基本使用方法和一些常见功能的示例。
import nltk
nltk.download('punkt') # 用于分词
nltk.download('averaged_perceptron_tagger') # 用于词性标注
nltk.download('maxent_ne_chunker') # 用于命名实体识别
nltk.download('words') # 英语词汇列表
nltk.download('stopwords') # 停用词列表,去除文本中的常见停用词(如“the”、“is”等)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)