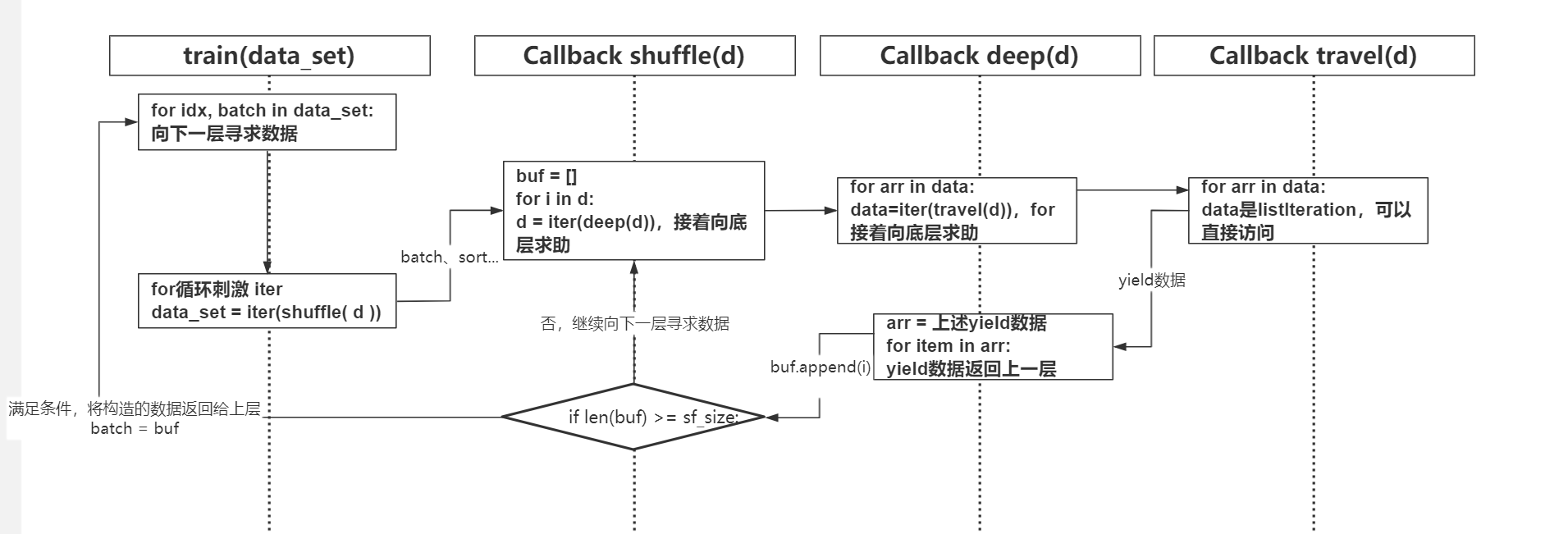
分析下述示例中输入数据依次执行顺序:travel -> deep -> shuffle -> sort -> batch,实际由于嵌套循环或设置缓存的存在,数据流式会有变化,具体如后图分析
from torch.utils.data import IterableDataset
# ...import random
classProcess(IterableDataset):
def__init__(self, data, f):
self.data = data
# 绑定处理函数
self.f = f
def__iter__(self):
# for循环遍历时,返回一个当前环节处理的迭代器对象return self.f(iter(self.data))
a = ['a0', 'a1', 'a2', 'a3', 'a4', 'a5', 'a6', 'a7', 'a8', 'a9']
b = ['b0', 'b1', 'b2', 'b3', 'b4', 'b5', 'b6', 'b7', 'b8', 'b9']
c = ['c0', 'c1', 'c2', 'c3', 'c4', 'c5', 'c6', 'c7', 'c8', 'c9']
# data = [[j + str(i) for i in range(10)] for j in ['a','b', 'c'] ]
data = [a, b, c]
deftravel(d):
for i in d:
# print('travel ', i)yield i
defdeep(d):
for arr in d:
for item in arr:
yield item
defshuffle(d, sf_size=5):
buf = []
for i in d:
buf.append(i)
iflen(buf) >= sf_size:
random.shuffle(buf)
for j in buf:
# print('shuffle', j)yield j
buf = []
for k in buf:
yield k
defsort(d):
buf = []
for i in d:
buf.append(i)
iflen(buf) >= 3:
for i in buf:
# print('sort', i)yield i
buf = []
for k in buf:
yield k
defbatch(d):
buf = []
for i in d:
buf.append(i)
iflen(buf) >= 16:
for i in buf:
# print('batch', i)yield i
buf = []
# 对训练数据进行的多个预处理步骤
dataset = Process(data, travel)
dataset = Process(dataset , deep)
dataset = Process(dataset , shuffle)
dataset = Process(dataset , sort)
train_dataset = Process(p, batch)
# 可在此处断点测试for i in p:
print(i, 'train')
# train_data_loader = DataLoader(train_dataset,num_workers=args.num_workers,prefetch_factor=args.prefetch)# train(model , train_data_loader)
由上可以构造数据流式方向 :batch(iter(sort(iter(shuffle(iter(deep(iter(travel(iter( d ))))))))))



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2021-01-08 Object.defineProperty 详解(数据响应式原理)