
前端面经整理
节流、防抖
防抖
<div>
<input type="text" id="input">
</div>
<script>
listenInput = ()=>{
console.log('输入结束,调用接口');
}
function debounce(fn , wait){
let start = Date.now() , end , st
return ()=>{
end = Date.now()
if(end - start < wait){
clearTimeout(st)
st = setTimeout(() => {
fn()
}, wait);
}else{
st = setTimeout(() => {
fn()
}, wait);
}
start = Date.now()
}
}
let input = document.querySelector('#input')
input.oninput = debounce(listenInput , 1000)
</script>
节流
<div>
<input type="text" id="input">
</div>
<script>
listenClick = ()=>{
console.log('移动');
}
function throttling(fn , wait){
// 节流
let start = Date.now() , end
return ()=>{
end = Date.now()
if(end-start>=wait){
fn()
start = Date.now()
}
}
}
document.onmousemove = throttling(listenClick ,1000)
</script>
排序算法
快速排序
let quickSort = function(arr){
let low = 1 , high = arr.length-1 , key = arr[0]
while(high > low){
if( arr[low] > key ){
let temp = arr[high]
arr[high--] = arr[low]
arr[low] = temp
}else{
arr[low-1] = arr[low++]
}
}
arr[low] = key
low > 0 && quickSort(arr.slice(0 , low))
low < arr.length-1 && quickSort(arr.slice(low+1))
}
二分查找
let binarySearch = function(arr, num){
let low = 0 , high = arr.length , mid
while(high > low){
mid = Math.floor((low+ high)/2)
if(arr[mid] === num ){
return mid
}else if(arr[mid] > num){
high = mid-1
}else{
low = mid +1
}
}
return -1
}
归并排序
let mergeSort = function(arr){
if(arr.length === 1){
return arr
}else if(arr.length > 1){
let mid = Math.floor(arr.length / 2)
let arrL = mergeSort(arr.slice(0 , mid))
let arrR = mergeSort(arr.slice(mid))
let llen = arrL.length , rlen = arrR.length , ret = [] , l = 0 , r = 0
while(llen > l && rlen > r ){
if(arrL[l] > arrR[r]){
ret.push(arrR[r++])
}else{
ret.push(arrL[l++])
}
}
if(l < llen || r < rlen){
ret = ret.concat(l < llen ? arrL.slice(l) : arrR.slice(r))
}
return ret
}
}
https实现原理
http存在的问题:
- 通信使用明文
- 无法证明报文的完整性,可能被篡改信息
- 不验证对方的身份,可能伪装
对称/非对称加密的特点
对称/非对称加密的特点:
- 对称加密:加密和解密使用同一个密钥
- 密钥可能落入他人之手,失去加密的意义
- 非对称加密:私有密钥、公开密钥(任何人获得)
- 黑客窃取到公开密钥,解密交流信息
- 公钥不包含身份信息,存在中间人攻击
- 加密、解密过程消耗时间大,效率低
解决内容可能被窃听:
交换密钥(后续会话)使用非对称加密,客户端使用服务器的公开密钥 加密 会话密钥 发送给 服务器- 后续会话使用 会话密钥 加密通话
数字签名特点:
- 能确定发送方的身份
- 确定信息的完整性,确认未被篡改
生成数字签名:
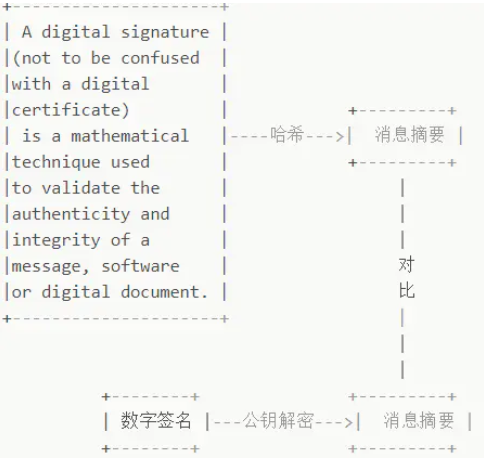
如何证明公钥是服务器的 => 证书颁发机构(Certificate Authority,CA),CA 生成服务器的公钥的数字签名(证书),而客户端内置受信任的CA的证书(CA的公钥)
数字证书:确定发送方只会是真正的发送方发送过(即公钥未被截取),服务器公钥是该服务器的
- 服务器的运营人员向第三方机构CA提交公钥、组织信息、个人信息(域名)等信息并申请认证
- CA通过线上、线下等多种手段验证申请者提供信息的真实性
- 如信息审核通过,CA会向申请者签发认证文件-证书,包含:
- 明文部分:申请者(服务器)公钥、申请者的组织信息和个人信息、签发机构 CA的信息、有效时间、证书序列号等信息的明文
- 签名部分:明文=散列函数=>CA私钥加密=>签名
- 客户端 Client 向服务器 Server 发出请求时,Server 返回证书文件
- 客户端使用对应的 CA 公钥解密签名数据,确定是否合法,合法则该服务器的公钥是值得信赖的
HTTPS工作流程:
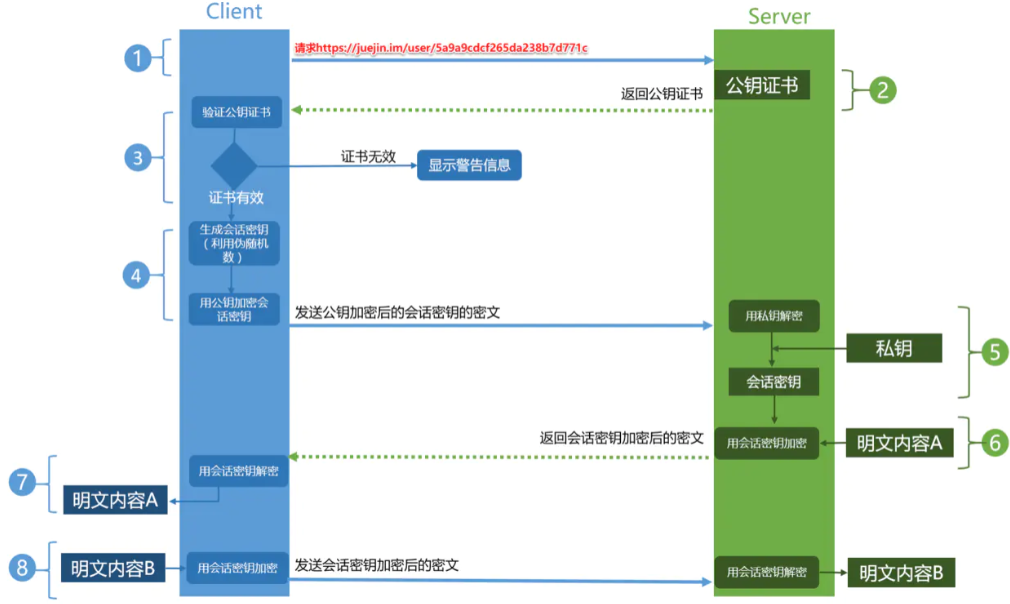
前端攻击有哪些? 如何防范
XSS攻击本质:恶意代码未经过滤,与网站正常的代码混在一起,而浏览器是无法辨认哪些脚本是恶意的导致恶意脚本被执行
XSS:其实我简称CSS,Cross-Site Scripting,跨站脚本攻击
根据攻击来源分类:- 反射型XSS:
- 攻击者构造出特殊的url,其中包含恶意代码(需要用户主动点击,往往装扮的很诱人)
- 用户打开带有恶意代码的url时,网站服务端将恶意代码从url取出,拼接在HTML中返回给用户
- 浏览器接受到之后立即执行,可以窃取用户数据
- DOM型XSS:
- 前端不严谨,使用 .innerHTML、.outerHTML、.appendChild、document.write() 等API
- 同上,构造除了恶意的DOM片段,被插入了
恶意DOM片段:
<a href="#" onclick="doAttack()">
click me
<script type="text/javascript">
function doAttack() {
while (true) {
alert('u are under attack');
}
}
</script>
</a>
- 存储型XSS:
- 攻击者将恶意代码提交到目标网站的数据库中
- 用户打开目标网站时,网站服务端将恶意代码从数据库取出,拼接在 HTML 中返回给浏览器
- 同上
XSS攻击防范
冷兵器时代:(无间道之处处防范)
- 反射型XSS:
app.get('/welcome', function(req, res) {
//对查询参数进行编码,避免反射型 XSS攻击
res.send(`${encodeURIComponent(req.query.type)}`);
});
- DOM型XSS:
- 对于url链接(例如图片的src属性),那么直接使用 encodeURIComponent 来转义
- 非url,我们可以这样进行编码:
function encodeHtml(str) {
if(!str) return '';
return str.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/&/g, '&');
}
- 存储型XSS:
- 前端数据传递给服务器之前,先转义/过滤
- 服务器接收到数据,在存储到数据库之前,进行转义/过滤
- 前端接收到服务器传递过来的数据,在展示到页面前,先进行转义/过滤
CSP:Content-Security-Policy(二向箔划痕打击)
- 如何使用:
Content-Security-Policy: default-src 'self'//想要所有内容均来自站点的同一个源 (不包括其子域名):
CSRF攻击:跨站请求伪造,攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
CSRF:Cross-Site Request Forgery,(伪装者之披着羊皮的狼)
- 受害者登录A站点,并保留了登录凭证(Cookie
- 攻击者诱导受害者访问了站点B
- 站点B向站点A发送了一个请求,浏览器会默认携带站点A的Cookie信息
- 站点A接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是无辜的受害者发送的请求
- 站点A以受害者的名义执行了站点B的请求
- 攻击完成,攻击者在受害者不知情的情况下,冒充受害者完成了攻击
CSRF攻击防范
- 添加验证码(体验不好,繁琐)
- 可以要求所有的用户请求都携带一个CSRF攻击者无法获取到的Token。服务器通过校验请求是否携带正确的Token,来把正常的请求和攻击的请求区分开
- 服务端给用户生成一个token,加密后传递给用户
- 用户在提交请求时,需要携带这个token
- 服务端验证token是否正确
点击劫持攻击:在一个Web页面中隐藏了一个透明的iframe,用外层假页面诱导用户点击,实际上是在隐藏的frame上触发了点击事件进行一些用户不知情的操作
性感荷官在线发牌...(好胆你就点)
攻击过程:- 攻击者构建了一个非常有吸引力的网页(跟前面有区别:攻击者构造的网页)
- 将被攻击的页面放置在当前页面的 iframe 中
- 使用样式将 iframe 叠加到非常有吸引力内容的上方
- 将iframe设置为100%透明
- 你被诱导点击了网页内容,你以为你点击的是***,而实际上,你成功被攻击了
攻击防范:
if (top.location !== window.location) {
top.location = window.location; }
- 另外HTML5中 iframe的 sandbox 、IE中iframe的security 都可以限制iframe中的脚本执行
Web前端性能优化
网页内容
减少http请求:
- CSS Sprites:雪碧图
- 字体图标:
- 需要请求的脚本和样式表合并起来,较少请求次数
减少 DNS 查询次数:
DNS 查询:浏览器缓存 => 操作系统缓存 => DNS查找
- 使用 DNS 缓存
- 缓存时间长,有利于重复利用
- 缓存时间短:有利于及时检测目标站点 IP 更新
- 将需要请求的内容放在同一个域名
- 但会出现下载资源排队现象,一个网站使用 2~4个 域
避免页面跳转
缓存AJAX(Asynchronrous Javascript and XML)、Expires、Cache-Control、ETags
添加Expires头:提醒客户端可以缓存数据到一定时间
- 初始形态:
Expires: Fri, 18 Mar 2016 07:41:53 GMT- 要求服务求与客户端时钟严格同步:过期日期需要经常检查
- HTTP1.1来临:
Cache-Control: max-age=12345600- max-age、Expires同时存在,max-age 更顶,指定失效时间
- ETags:Entity Tag,实体标签:一个特殊字符串来标识某个资源的“版本”。工作原理:
- 客户端第一次请求资源:服务端响应:200,响应头部包含ETag的信息(ETag "
6ab823201a4ece1:0") - 客户端再次请求该资源:请求头添加一行:
If-None-Match "6ab823201a4ece1:0" - 此次,服务器会比对 ETag的值,如果没有变化,会返回
304状态码,响应体不需要包含任何实际内容- 浏览器得到304之后,直接使用本地缓存的版本
- 客户端第一次请求资源:服务端响应:200,响应头部包含ETag的信息(ETag "
压缩组件:HTTP1.1之后
- 客户端:表达自己接受的类型,
Accept-Encoding: gzip,deflate - 服务器端:
Content-Encoding: gzip
延迟加载
- 网页最初加载需要的最小内容集
- 比较激进的做法是开发网页时确保没有JavaScript也能完成基本工作
- 然后通过延迟加载完成一些高级的功能
可以看到点击博客园首页所有的请求中,第一个请求就是返回的页面骨架
提前加载
- 无条件提前加载:当网页加载完成后,马上下载其它内容(如CSS Sprites)
- 有条件加载:根据用户的输入提前加载准备
减少DOM元素数量
- 查DOM数量:
document.getElementsByTagName('*').length
减少iframe数量
iframe优点:
- 可以用来加载速度较慢的内容,例如广告
- 安全沙箱保护。浏览器可以对 iframe 中的内容进行安全控制
- 脚本可以并行下载
iframe缺点:
- 即使iframe 内容为空也消耗加载时间
- 会阻止页面加载
避免404
- 结果返回404:阻塞其它脚本下载,下载回来的内容(404)客户端还会将其当作JavaScript执行
- CDN:(Content Delivery Network)那日容分发网络,就近获取目标服务器的数据
CSS部分
避免CSS表达式
background-color: expression( (new Date()).getHours()%2 ? "#B8D4FF" : "#F08A00" );
- 网页重新绘制
- 滚动屏幕、移动鼠标...都在计算
避免使用 代替@import
相当于将CSS放在网页内容底部
将CSS样式表置顶
- 这样做可以使浏览器逐步加载已经下载的网页内容,不会出现等待一个白屏
- 原因:大多数浏览器都在避免重绘,样式表中的内容是绘制网页的关键信息
JavaScript
- 去除重复脚本,代码更精简(避免浪费下载时间)
- 减少 DOM 的访问
clone = old.copyNode(true)先复制一份需要改变的节点的副本- 更新该节点,加回到DOM Tree:
old.parentNode.replaceChild(clone, old)
- 减少监听事件的触发
- 例 div 中有10个button,仅给div添加click事件代替分别给10个button添加,使用冒泡确定按钮来源
- 将脚本置底:
- 如果脚本正在下载,浏览器就不会开始任何其它下载任务,因为浏览器要在脚本下载之后解析和执行
- 脚本置底,这样可以让网页渲染所需要的内容尽快加载显示给用户
- 主流浏览器支持 defer 关键字,可以指定脚本在文档加载后执行
- HTML5新加 async 关键字,可以让脚本异步执行
- 如果脚本正在下载,浏览器就不会开始任何其它下载任务,因为浏览器要在脚本下载之后解析和执行
- 使用外部JavaScript和CSS文件
- 如果经常使用这些文件,采用外部方式浏览器会缓存文件
- 去掉JavaScript和CSS中的空格、注释
输入URL到渲染过程
渲染过程
- 输入URL按下回车=> 解析URL
- 网络线程发出一个完整的请求
- 应用层DNS解析域名,将域名转换成IP地址
3。应用层ARP协议查询 MAC地址 - 应用层发送请求,到达网络层分割编号=>数据链路层=>物理层
- TCP/IP协议:3次握手建立连接
- 服务器接收请求,会比较缓存版本=>返回相应的数据
- 解析HTML构建DOM Tree
- 根据DTD类型 => GUI渲染线程处理
- HTML网页字节流 ==html解释器>> 字符流 ==词法解释器>> 词流 ==词法分析器>> 节点 => DOM树
- 上述过程中:,如果遇到的节点是JS代码=>JS引擎解释执行(JS引擎和GUI渲染线程互斥)
- 如遇到加载图片/CSS等资源,他们是异步的,不会阻塞当前DOM树的构建
- 如遇到 JS 资源,会停止渲染线程,直至js加载并执行完毕再急促构建DOM树
- 根据DTD类型 => GUI渲染线程处理
- 解析CSS 构建CSSOM Tree(CSS解释器、CSS词法、CSS语法),最后CSS对象模型(CSSOM)
- DOM树和CSSOM结合生成渲染树
- 布局(Layout):设备视口内的确切位置 ==绘制>> 换成实际像素 ==合成>> GPU将各层信息合成显示在屏幕上


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人