
图像的拼接----RANSAC算法
一、全景拼接的原理
1.RANSAC算法介绍
RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outliers,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。
2.使用RANSAC算法来求解单应性矩阵
在进行图像拼接时,我们首先要解决的是找到图像之间的匹配的对应点。通常我们采用SIFT算法来实现特征点的自动匹配,SIFT算法的具体内容参照我的上一篇博客 。SIFT是具有很强稳健性的描述子,比起图像块相关的Harris角点,它能产生更少的错误的匹配,但仍然还是存在错误的对应点。所以需要用RANSAC算法,对SIFT算法产生的128维特征描述符进行剔除误匹配点。
由直线的知识点可知,两点可以确定一条直线,所以可以随机的在数据点集中选择两点,从而确定一条直线。然后通过设置给定的阈值,计算在直线两旁的符合阈值范围的点,统计点的个数inliers。inliers最多的点集所在的直线,就是我们要选取的最佳直线。
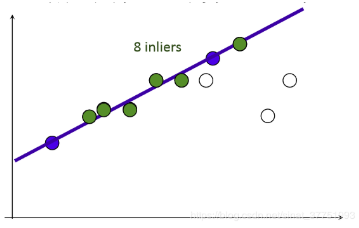
RANSAC算法就是在一原理的基础上,进行的改进,从而根据阈值,剔除错误的匹配点。首先,从已求得的匹配点对中抽取几对匹配点,计算变换矩阵。然后对所有匹配点,计算映射误差。接着根据误差阈值,确定inliers。最后针对最大inliers集合,重新计算单应矩阵 H。
3.基本思想描述:
①考虑一个最小抽样集的势为n的模型(n为初始化模型参数所需的最小样本数)和一个样本集P,集合P的样本数#(P)>n,从P中随机抽取包含n个样本的P的子集S初始化模型M;
②余集SC=P\S中与模型M的误差小于某一设定阈值t的样本集以及S构成S*。S*认为是内点集,它们构成S的一致集(Consensus Set);
③若#(S*)≥N,认为得到正确的模型参数,并利用集S*(内点inliers)采用最小二乘等方法重新计算新的模型M*;重新随机抽取新的S,重复以上过程。
④在完成一定的抽样次数后,若未找到一致集则算法失败,否则选取抽样后得到的最大一致集判断内外点,算法结束。
4.图像拼接
使用RANSAC算法估计出图像间的单应性矩阵,将所有的图像扭曲到一个公共的图像平面上。通常,这里的公共平面为中心图像平面。一种方法是创建一个很大的图像,比如将图像中全部填充0,使其和中心图像平行,然后将所有的图像扭曲到上面。由于我们所有的图像是由照相机水平旋转拍摄的,因此我们可以使用一个较简单的步骤:将中心图像左边或者右边的区域填充为0,以便为扭曲的图像腾出空间。
二、实验
1.源代码

# -*- coding: utf-8 -*-
from pylab import *
from PIL import Image
from PCV.geometry import homography, warp
from PCV.localdescriptors import sift
# set paths to data folder
featname = ['C:/Users/LE/PycharmProjects/untitled/hh/' + str(i + 1) + '.sift' for i in range(4)]
imname = ['C:/Users/LE/PycharmProjects/untitled/hh/' + str(i + 1) + '.jpg' for i in range(4)]
# extract features and match
l = {}
d = {}
for i in range(4):
sift.process_image(imname[i], featname[i])
l[i], d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(3):#2
matches[i] = sift.match(d[i + 1], d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(3):#2
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i + 1]))
figure()
sift.plot_matches(im2, im1, l[i + 1], l[i], matches[i], show_below=True)
# function to convert the matches to hom. points
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j + 1][ndx, :2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2, :2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1], fp[0], fp[2]])
tp = vstack([tp[1], tp[0], tp[2]])
return fp, tp
# estimate the homographies
model = homography.RansacModel()
fp, tp = convert_points(1)
H_12 = homography.H_from_ransac(fp, tp, model)[0] # im 1 to 2
fp, tp = convert_points(0)
H_01 = homography.H_from_ransac(fp, tp, model)[0] # im 0 to 1
# warp the images
delta = 1000 # for padding and translation
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12, im1, im2, delta, delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12, H_01), im1, im_12, delta, delta)
figure()
imshow(array(im_02, "uint8"))
axis('off')
show()
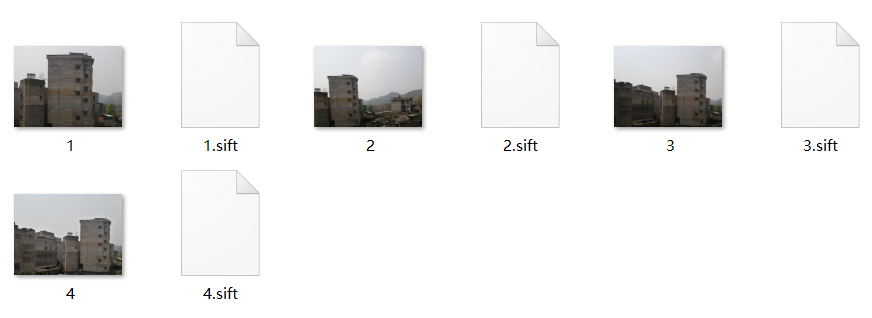
特征匹配


图像拼接

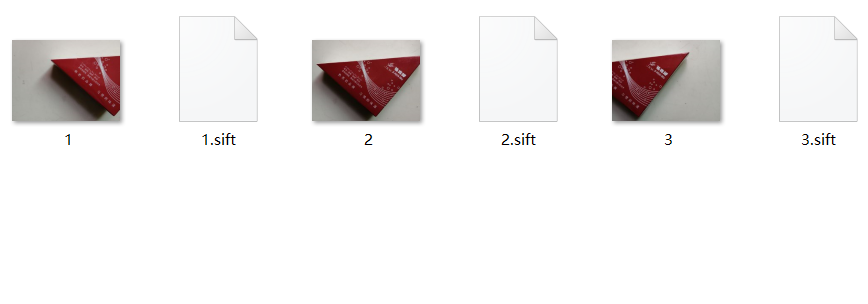
特征匹配


图像拼接

4.视差变化大拍摄
数据集
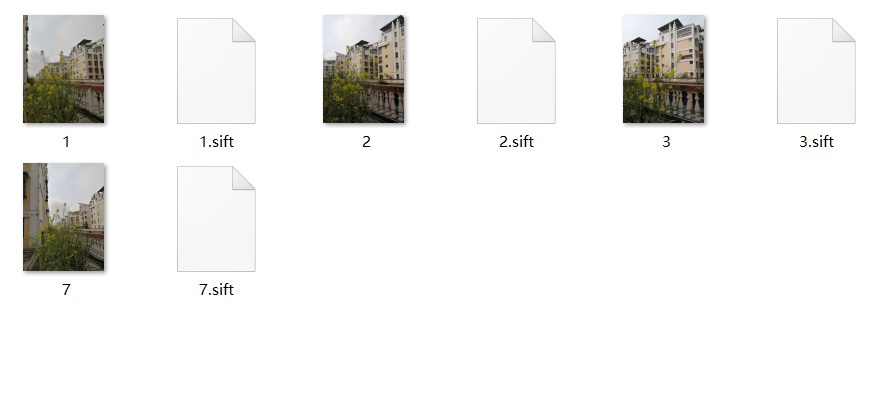
特征匹配



图像拼接

5.同一地点不同方位拍摄
数据集
特征匹配


图片拼接

三、实验结果分析
通过四种不同场景的测试,可以看出:
室外固定点位拍摄的场景因为检测到的特征点较多提高了匹配度, 虽然总体的拼接图像在视觉上有点扭曲,但大致上都拼接出来了。
室内固定点位拍摄的场景,拼接效果比较理想,但由于图像曝光度的不同,导致在图像的边界上存在边缘效应,这也是该算法需要改进的地方。
室外同一地点不同角度拍摄场景,拼接效果最不理想,这是由于,虽然算法在特征匹配时匹配度很高,但是在进行拼接时,算法不会帮我们旋转图片的角度达到很好的拼接效果。
室外视察变化大拍摄的场景,按理来说应该检索到的特征点很多,但拼接结果不是很理想,这是由于我拍摄时没有尽可能的水平移动所导致,并且我的拍摄背景很相似,建筑物比较对称,所以也提醒大家拍摄测试图像要注意:为了拼接出效果比较好的图像,在保证有相同匹配点的情况下,拍摄图像的间隔尽可能大一些。且一定要站在同一点,水平移动手机进行拍摄,就像拍摄全景图那样。若人拍摄的位置发生移动的话,算法可能就会因为找不到正确的点对而报错,且最好不要拍摄那种对称的建筑物,且两边的的特征点长的几乎一样的。这样会使算法的匹配出现失误。
图片像素越高会导致代码运行较慢甚至报错。
四、实验中遇到的错误
1.代码运行时出现

解决方法:这是由于图片像素没有设置一致,将所有图片像素设置相同得以解决,同时像素不能太大会降低运行速度,也不能过小,这样提取的特征点不够准确。
2.在解决问题1.后又遇到

解决方法:这是因为拍摄的图片没有尽可能的水平位移,并且选取的场景尽量不要对称。
3.解决完问题1和问题2后我又遇到了如下问题
![]()
在百度,询问同学尝试多种方法后,此问题还是没有解决,可能是与拍摄图片本身有关,所以重新拍摄,以后找到解决方法再更新吧。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?