
MySQL8的新特性
一 字典数据与资源管理
1.1 数据字典
以前MySQL都是采用元数据文件、非事务性表结构或者是存储引擎特有的方式来存储字典数据,这些字典数据通常都是以数据对象为主,比如说最常见的表结构信息等。
在MySQL8.0中,这些字典数据都被移动到拥有InnoDB存储引擎的事务性表中进行存储了,这样做可以带来下列这些好处:
(1) 字典数据集中化管理更加方便;
(2) 移除掉了基于文件的元数据存储;
(3) 支持事务,字典数据也同样可以crash-safe;
(4) 使用INFORMATION_SCHEMA表更加简单并且得到改进;
(5) 原子性DDL操作得到支持。
1.2 原子性DDL
在MySQL8.0中,无论是否针对表的DDL操作,都可以得到很好的支持。
(1) 针对表、表空间、索引等的DDL操作:比如说CREATE、ALTER、DROP、TRUNCATE TABLE都可以支持原子性操作;
(2) 针对非表的DDL操作:比如说账户授权的GRANT、REVOKE操作。
比如说,数据库中有两张表t1和t2,我们执行如下DDL:
DROP TABLE t1, t2
要么这两张表同时被DROP,要么同时DROP失败(有一种例外:只有一张表会被DROP成功,那就是另一张表已经不存在)。
1.3 资源管理
MySQL支持资源组的创建和管理,并允许将服务器内运行的线程分配给特定组,以便线程根据组可用的资源执行。组属性可以控制其资源,以启用或限制组中线程的资源消耗。DBA可以根据不同的工作负载修改这些属性。
目前,CPU时间是可管理的资源,由“ 虚拟CPU ”的概念表示为包括CPU核心,超线程,硬件线程等的术语。服务器在启动时确定可用的虚拟CPU数量,具有适当权限的数据库管理员可以将这些CPU与资源组关联,并将线程分配给组。
DBA可以根据不同的作业优先级,可以动态调配机器资源的使用,从而达到服务器性能价值发挥的最大化。
1.4 表加密
MySQL8.0开始,支持对表进行加密,具体加密方式,可以采用default_table_encryption 参数对所有的表都默认进行加密,也可以在创建表的时候使用DEFAULT ENCRYPTION语句来对表进行加密。
二 InnoDB增强
2.1 Redo Log
(1) innodb_flush_log_at_trx_commit参数:
0:每次都只写redo log buffer。
1:每次都持久化到磁盘(调用fsync)。
2:每次都只写os page cache(调用write)。
(2) 架构设计的优化,采用无锁异步设计;
redo_log的优化将之前锁冲突化解,用户线程的“等锁-写”机制转化为“写缓冲-查看写盘”机制。用户线程不进行刷盘操作,由后台线程统一刷盘,用户线程在写缓冲后就可以做其他操作,达到日志写盘和mtr做其他事情的并行,提升效率。
log_writer:负责将日志从log buffer写入磁盘,并推进write_lsn(原子数据)
log_flusher:负责fsync,并推进flushed_to_disk_lsn(原子数据)
log_write_notifier:监听write_lsn,唤醒等待log落盘的用户线程(根据 flush_log_at_trx_commit设置,用户commit操作会等待write_lsn推进)
log_flush_notifier:监听flushed_to_disk_lsn,唤醒等待log fsync的用户线程。
log_closer:1、在正常退出时清理所有redo_log相关lsnlog buffer相关数据结构;2、定期清理recent_closer的过老数据(recent_closer所用之后详述)
log_checkpointer:定期做checkpoint检查,根据flush list刷dirty page情况推进check point,释放log buffer等
(3) 可以动态调整自旋迟延的高低水位值
优化器使用自旋延迟(spin delay)的方式等待redo的刷新。自旋延迟有利于减少延迟。在低并发的时候,减少延迟并没有太大效果,并且在此期间避免使用来减少性能消耗。在高并发期间,我们可能希望避免在自旋延迟上消耗处理能力,以便它可以用于其他工作。以下系统变量允许设置高水位值和低水位值,这些值定义了使用自旋延迟的边界。
innodb_log_wait_for_flush_spin_hwm:定义最大平均日志刷新时间,超过该时间,用户线程在等待刷新的redo log时不再旋转。默认值为400微秒。
innodb_log_spin_cpu_abs_lwm:定义在等待刷新redo log时用户线程不再旋转的最小CPU使用量。该值表示为CPU核心使用量的总和。例如,默认值80是单个CPU核心的80%。在具有多核处理器的系统上,值150表示100%使用一个CPU核心加50%使用第二个CPU核心。
innodb_log_spin_cpu_pct_hwm:定义在等待刷新redo log时用户线程不再旋转的最大CPU使用量。该值表示为所有CPU核心的总处理能力的百分比。默认值为50%。例如,两个CPU内核的100%使用率是具有四个CPU内核的服务器上组合CPU处理能力的50%。
innodb_log_spin_cpu_pct_hwm: 配置选项方面处理器的亲缘性。例如,如果服务器有48个内核但 mysqld进程仅固定为4个CPU内核,则忽略其他44个CPU内核。
(4) 支持Redo Log的归档;
在MySQL8.0之前的版本中,Redo Log是只能保存最近一段时间的redo log,这个大小可以配置。但MySQL8.0之后,可以支持对Redo Log进行归档。
归档日志可以解决备份时,Redo Log被覆盖的问题,覆盖问题的产生就是Redo Log的复制速度跟不上Master的Redo Log的写入速度,如果Redo Log被写满,就会存在覆盖。
2.2 服务自适应参数
innodb_dedicated_server这个参数默认是关闭的,如果开启它,innodb将自动探测服务器内存资源,可以自动配置下面这几个参数的取值:
innodb_buffer_pool_size (缓冲池大小)
innodb_log_file_size (日志文件大小)
innodb_flush_method(刷盘方式)
2.3 双写缓冲池
在MySQL 8.0之前,doublewrite缓冲区存储区位于InnoDB系统表空间中。从MySQL 8.0开始,doublewrite缓冲区存储区位于doublewrite文件中。这样做可以降低写延迟,提高吞吐率,同时提供了下面这些参数对双写缓冲区进行配置:
innodb_doublewrite_dir(配置双写缓冲区文件目录)
innodb_doublewrite_files(配置双写缓冲区文件数量)
innodb_doublewrite_pages(配置每个线程每一次批量写双写缓冲区的最大页数)
innodb_doublewrite_batch_size(配置每一次批量写双写缓冲区的最大页数)
2.4 并行查询
在MySQL8.0中,可以对聚集索引进行并发写操作,在以往,我们在执行select count(*)的时候,都只能单线程。
它提供了参数innodb_parallel_read_threads 来配置并发读的线程数。
目前该特性对二级索引还不支持。
2.5 自增计数器的持久化
在8.0之前的版本,自增值是保存在内存中,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1。这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题。8.0版本将会对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。
MySQL从8.0开始,当前最大的自增计数器每当发生变化,值会被写入redo log中,并在每个检查点时候保存到私有的系统表中。这一变化,对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。
MySQL server重启后不再取消AUTO_INCREMENT = N表选项的效果。如果将自增计数器初始化为特定值,或者将自动递增计数器值更改为更大的值,新的值被持久化,即使服务器重启。
在回滚操作之后立即重启服务器将不再导致重新使用分配给回滚事务的自动递增值。
如果将AUTO_INCREMEN列值修改为大于当前最大自增值(例如,在更新操作中)的值,则新值将被持久化,随后的插入操作将从新的、更大的值开始分配自动增量值。
三 字符集及数据类型增强
3.1 字符集
默认字符集由latin1改为uft8mb4。
3.2 时间类型支持时区偏移
TIMESTAMP和DATETIME类型允许存储时区偏移
四 JSON增强
4.1 聚合函数
MySQL8.0增加了两个聚合函数JSON_ARRAYAGG()和JSON_OBJECTAGG()。
JSON_ARRAYAGG()函数:可以把分组后多行合并成数组,如下:

JSON_OBJECTAGG()函数:分组后直接把一个分组生成json对象。

4.2 工具函数
JSON_PRETTY()函数,对查询结果进行美化:

JSON_STORAGE_SIZE()函数,计算json数据所占用的空间(字节数):
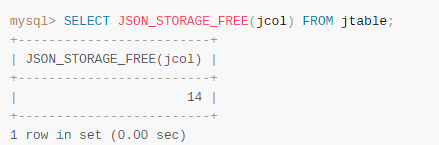
JSON_STORAGE_FREE() 函数,计算json数据更新后所释放的空间(字节数):

JSON_MERGE_PATCH()函数,允许把两个json对象合并为一个json对象:

4.3 Schema校验
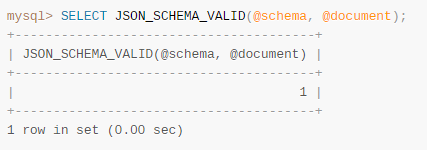
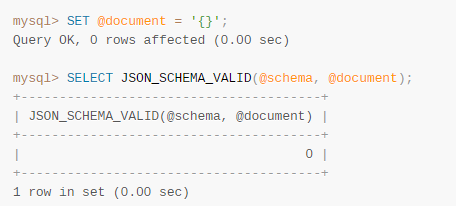
JSON_SCHEMA_VALID()函数,可以判断文档是符合预定义的Schema:

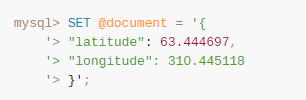
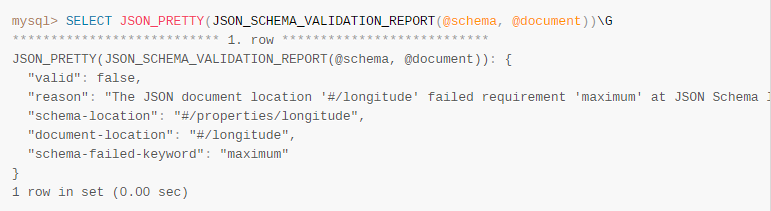
JSON_SCHEMA_VALIDATION_REPORT()函数,可以生成Schema校验报告:
4.4 多值索引
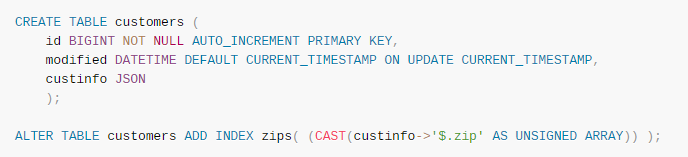
Multi-valued indexes,MySQL8.0允许对json中数组的每一个元素建立索引:
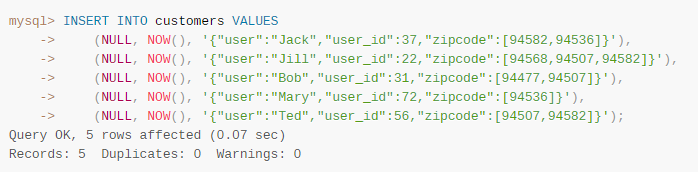

MEMBER OF()函数:判断输入的元素是否目标数组中的元素
JSON_CONTAINS()函数:判断输入数组是否为目标数组的子集
JSON_OVERLAPS()函数:判断输入数组是否与目标数组存在交集
五 其它新特性
5.1 使用函数设置默认值
在MySQL8.0中,建表时,可以使用函数对字段进行默认值的赋值:

5.2 窗口函数
对于查询中的每一行,可以使用窗口函数,利用与该行相关的行执行计算。
ROW_NUMBER():分区内当前行的编号。
RANK():分区中当前行的等级(有间隔)。
DENSE_RANK():分区内当前行的等级(无间隔)。
PERCENT_RANK():百分比排名值。
FIRST_VALUE():窗口帧中第一行的参数值。
LAST_VALUE():窗口帧中最末行的参数值。
LEAD():领先于分区内当前行的那一行的参数值。
LAG():落后于分区内当前行的那一行的参数值。
NTH_VALUE():窗口帧中的第 n 行的参数值。
NTILE():分区内当前行的桶的编号。
COME_DIST():累积分布值。
5.3 内部临时表
内存内部临时表,默认的存储引擎从MEMORY变成了TempTable。TempTable对于VARCHAR和VARBINARY字段存储更高效。
5.4 通用表达式查询
支持通用表达式查询,支持递归查询(必须指定终止条件)
5.5 取消查询缓存
MySQL8.0取消了查询缓存,取消它的原因在于大家都爱在生产环境禁用这个鸡肋功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号