
大数据之Hadoop
Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
从Hadoop的发展历程来看,它的思想来自于google的三篇论文。
GFS:Google File System 分布式处理系统 ------》解决存储问题
Mapreduce:分布式计算模型 ------》对数据进行计算处理
BigTable:解决查询分布式存储文件慢的问题,把所有的数据存入一张表中,通过牺牲空间换取时间
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系。
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作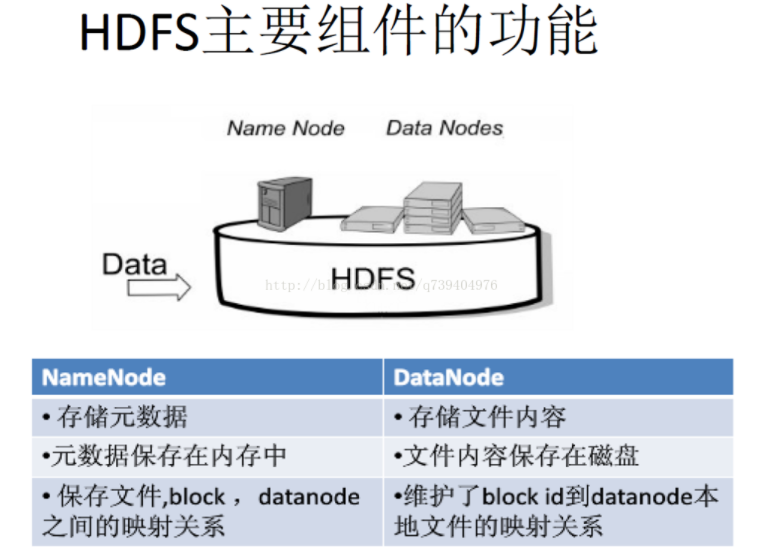
一、系统结构与环境角色
1.架构图
2.HMaster
监控RegionServer
处理RegionServer故障转移、处理源数据变更
处理region的分配与移除
空闲时进行数据的负载均衡
通过ZK发布自己的位置给客户端连接
3.RegionServer
负责与hdfs交互,存储数据到hdfs中
处理hmaster分配的region
刷新缓存到hdfs
维护hlog
执行压缩
处理region分片
处理来自客户端的读写请求
4.Client
Client包含了访问Hbase的接口
维护对应的cache来加速Hbase的访问,比如MATE表的元数据信息
5.Zookeeper
Zookeeper主要负责master的高可用
RegionServer的监控
元数据的入口以及集群配置的维护工作。
6.HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:
提供元数据和表数据的底层分布式存储服务
数据多副本,保证的高可靠和高可用性
二、组件
1.Write-Ahead-logs(hlog)
它是Hbase的修改记录,当对Hbase进行读写操作时,数据不是直接资额入到磁盘的,它会在内容中保存一段时间(时间长短以及数据量的阈值可以设置)。但是我们都知道数据存放在内存中并不安全,为了避免这个问题;数据会先写入到Write-Ahead-logfile的文件中(和hdfs的edit文件相似),然后在写入内存。当系统故障时可以通过日志文件重建数据。
2.Region
Hbase的表分片,Hbase表会根据RowKey的不同被切分成不同的region存储在RegionServer中;所以在一个RegionServer中可以有多个不同的region。
3.Store
Hfile存储在Store中,一个Store对应Hbase表中的一个列族。
4.HFile
是在磁盘上保存原始数据的实际物理文件。StoreFile是以Hfile的形式存储在Hdfs中。
5.MemStore
内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
三、读写存操作
1.Hbase的写流程
2.Hbase的读流程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号